如何通过推理加速优化你的大模型? 目前大模型火归火,但落地一看推理慢、资源吃紧,许多都跑不动,特别是在边缘设备或者商用场景里。所以推理加速优化,真的就是决定能不能真正work的关键。我们来聊聊2025年比较实用、还挺有前景的优化手段... 内容分享# Python# sci# 大模型 7个月前130
做RAG系统最难搞定的是那部分工作? RAG基础概念Retrieval-Augmented Generation(RAG)是通过检索外部知识来增强LLM生成能力的技术。检索可以是通过搜索引擎或是离线数据库(如企业、政府机密数据)。检索到的... 内容分享# Python# 代码定制# 深度学习 9个月前020
上班摸鱼写了篇 推荐系统 教程 。基本所有的内容平台都离不开推荐,那么推荐背后的技术原理是什么呢? 推荐系统的概念源于电商,协助用户决定应该购买什么产品 不过随着互联网发展,推荐系统也由原来的电商领域覆盖到了互联网的方方面面,我们实... 内容分享# ai# 推荐算法# 推荐系统 9个月前040
DeepSeek:多模态AI,重塑信息处理 Deepsig的多模态能力,简单来说就是它能够同时理解和处理来自不同来源的信息 示例:当你对着手机说出一句话并附上一张图片,Deepsig不仅能识别你的语音内容,还能解析图片中的信息,甚至将它们结合起来,给出更精准的回应。 技术支撑:Deepsig在深度学习领域的突破,它通过复杂... 内容分享# Deepsig# 多模态ai# 深度学习 9个月前020
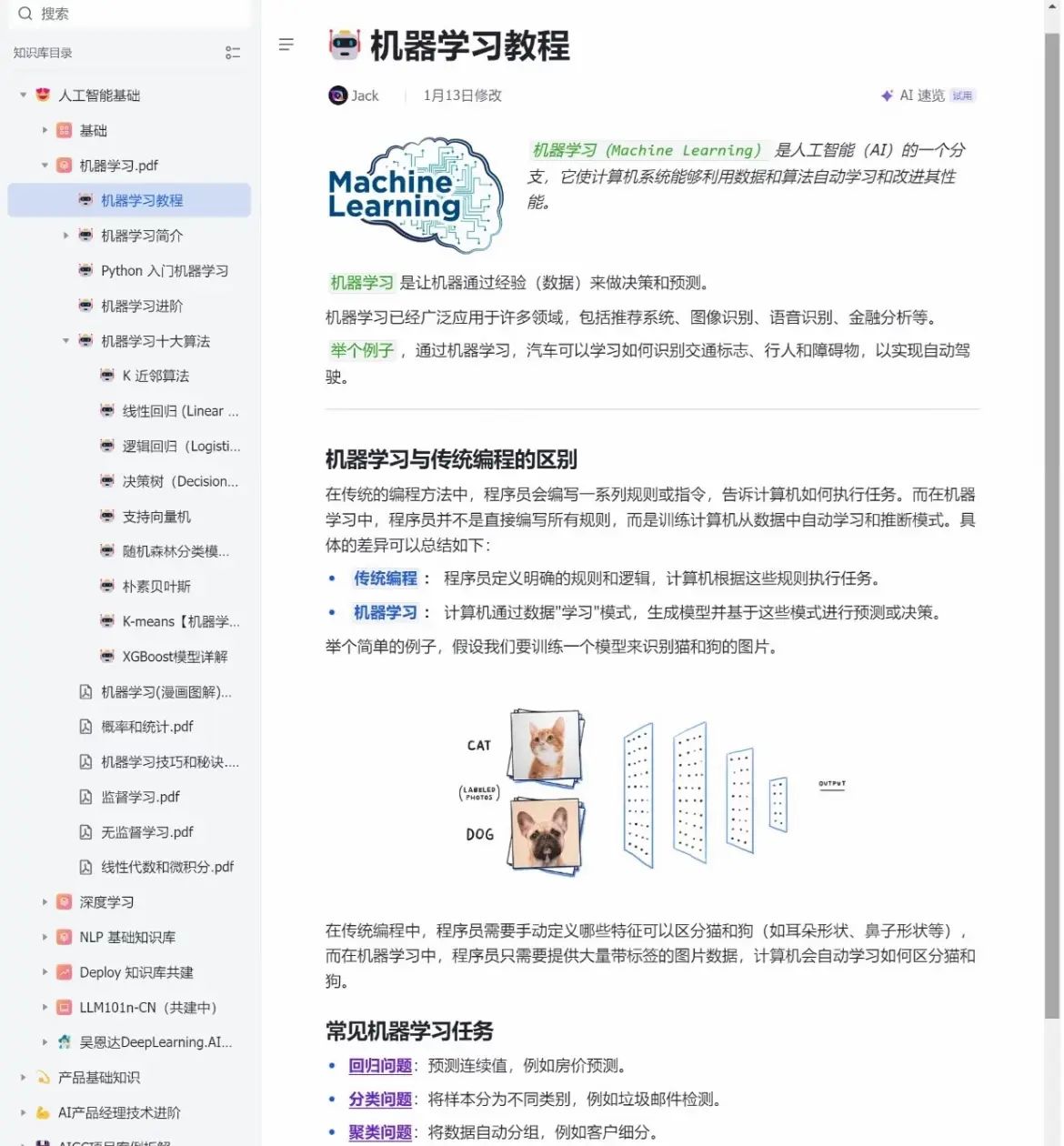
我们机器学习有自己的作业帮 。机器学习目前在日常生活中有许多地方都有应用,作为人工智能的知识支柱之一,它的十大经典算法有哪些呢?今天就用这个知识库在线文档讲清楚这机器学习10大经典算法 内容分享# AI产品经理# ai产品经理入门# 机器学习 9个月前640
机器学习入门总搞不懂核心概念?! 全网唯一用 2 万字、100 张图、100 个例子把 100 个机器学习核心概念讲透的干货!从数据、学习过程到模型,一步步拆解超清晰,新手也能轻松入门,提议收藏慢慢啃~ 内容分享# 人工智能# 基础# 机器学习 9个月前080
机器学习真不难!15小时肝完拿下! 。由Google团队倾力开发的15小时机器学习速成课程,为学员构建了一条贯穿机器学习基础知识、核心理念以及案例剖析的完整学习轨迹。 这门课程对于那些对人工智能和机器学习怀揣热忱的人,以及渴望增强自身机... 内容分享# pytorch# 机器学习# 深度学习 9个月前620
多模态大模型视觉编码器优化 。 视觉编码器扩展:传统的视觉语言模型(VLM)如CLIP使用的是基于ViT的编码器,一般采用监督学习进行训练。这些模型通过对齐图像与文本标签来提取图像特征,但对于分布外图片的处理存在不足,可能导致图... 内容分享# ccf# Python# sci 9个月前030
2025深度学习8大算法模型详解! 。深度学习算法在许多领域都有超级广泛的应用,包括:计算机视觉、自然语言处理、语音识别、视频分析、生物信息学、金融市场等。 对于算法小白来说,深度学习可能有点难,但是别担心,今天我帮大家整理了深度学习的... 内容分享# 人工智能# 机器学习# 深度学习 9个月前530
Meta 刚刚在 Hugging Face 上发布了 MobileLLM-R1 边缘推理模型,参数少于 10 亿 性能提升 2–5×,超越其他完全开源模型:MobileLLM-R1 MATH 准确率上比 Olmo-1.B 高约 5 倍,比 SmolLM2-1.7B 高约 2 倍 与 Qwen 相比,仅使用 1 10 的预训练 token:仅用 4.2 万亿 token(仅占 Qwen3 的 36 万亿 token 的 11.7%)进行训练,就在多个推理基准测试中达到或超过 Q... 内容分享# 技术分享# 日常生活# 每天跟我涨知识 9个月前0120
研究生搞深度学习怎么选择?! 。就目前来看,我提议学习pytorch。代码结构与框架设计第一,TensorFlow的代码结构相较于PyTorch显得更加臃肿,且源代码框架设计上不如PyTorch那样规整合理。这也是为何在过去工业界... 内容分享# Python# pytorch# sci 9个月前1130
多模态大模型的前沿算法 。LLaVA架构视觉编码器+语言模型的融合,LLaVA算法我感觉还挺好用的。它用Vision Transformer提取图像特征,然后直接接入大语言模型,简单粗暴但效果炸裂。最大的好处就是可以复用现有... 内容分享# sci# 发文# 复现 9个月前070
*°▽°* 深度学习的好处,千万别错过! 第1集 | 。信任许多人都听过深度学习,也知道深度学习很好。可是,深度学习究竟有多好,你知道吗? 深度学习的本质如果把大脑比作成一个加工厂,其头号任务是选择高质量的知识进行深加工。这种深加工不仅包括知... 内容分享# 升职加薪# 学习提升# 学习方法 9个月前140
还得是神经网络!就是这么帅啊!! 。基础概念:神经网络与线性变化神经网络的核心原理是利用连续线性变化和非线性激活函数的组合。线性变化类似于函数 y=kx+by = kx + by=kx+b,通过对输入进行加权求和并加上截距,得到一条直... 内容分享# 大模型# 强化学习# 深度学习 9个月前250
PyTorch真不难!学完这51页就牛了 。零基础入门教都给小伙伴们整理好啦 想自学的包子赶紧住!! 掌握Pytorch实则并不难,只需20天就能精通! 这本著作无疑是Pytorch初学者的福音,它秉持“简化思考”的理念,致力于让读者轻松步入... 内容分享# pytorch# pytorch入门# 人工智能专业 9个月前1040
我们PyTorch有属于自己的作业帮 。我发现了一份超实用的《20天攻克PyTorch指南》!这份指南的题目是按照难易程度精心分类的,每个主题所需的学习时间也都标注得清清楚楚。每天只需抽出30分钟到2小时,就能循序渐进地掌握PyTorch... 内容分享# pytorch# pytorch深度学习# 机器学习 9个月前19230
我竟然半天时间就学会了八大神经网络!!! 。在深度学习中主要的八大神经网络包括以下几种: 卷积神经网络(CNN)卷积神经网络是用于图像和空间数据处理的神经网络,通过卷积层和池化层来捕捉图像的局部特征,广泛应用于图像分类、物体检测等领域。典型的... 内容分享# 人工智能专业# 机器学习入门# 深度学习 9个月前2510
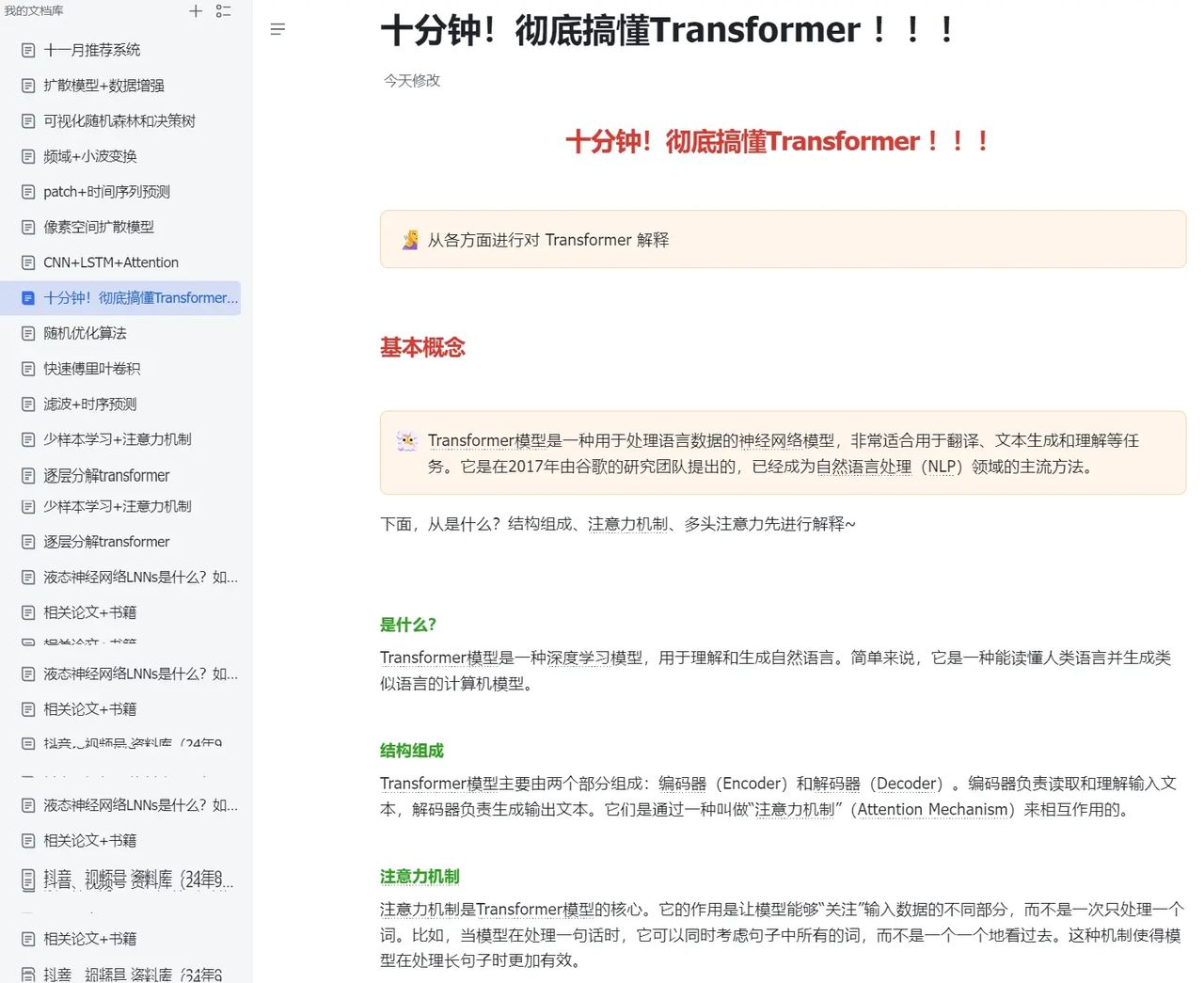
十分钟!彻底搞懂Transformer 。Transformers 亮相以来彻底改变了深度学习模型。 今天将从各方面进行对 Transformer 解释, 包括基本概念、理论基础、完整案例、模型分析、优缺点、与其他算法的对比等等。 内容分享# transformer# 人工智能# 深度学习 9个月前310
有被这个Transformer 惊艳到! 第一介绍四种不同类型的视觉语言预训练(VLP)模型,并归纳两种模态相互作用方式及三种视觉嵌入方式,最后探讨ViLT的设计思路。 视觉与语言模型分类:四种VLP模型的示意图中,各矩形的高度表明计算量的大... 内容分享# transformer# 多模态# 大模型 9个月前050
计算机视觉常用的十大模型总结!! 。今天为大家科普一下计算机视觉领域中的常用模型。计算机视觉,作为智能驾驶、智能技术等领域的核心算法,具有举足轻重的地位。尽管对于初学者来说,它可能显得深奥且难以捉摸,但请放心,带你了解CV的世界! 内容分享# 人工智能# 机器学习# 深度学习 9个月前110
论文带读系列2023 第4集 | 。深度学习是指在教师的引领下,学生围绕具有挑战性的主题,全身心积极参与,体验成功,获得发展的有意义的学习过程。五个特征:联想与结构 体验与活动 本质与变式 迁移与应用 价值与评价 读后感... 内容分享# 深度学习# 郭华 9个月前160
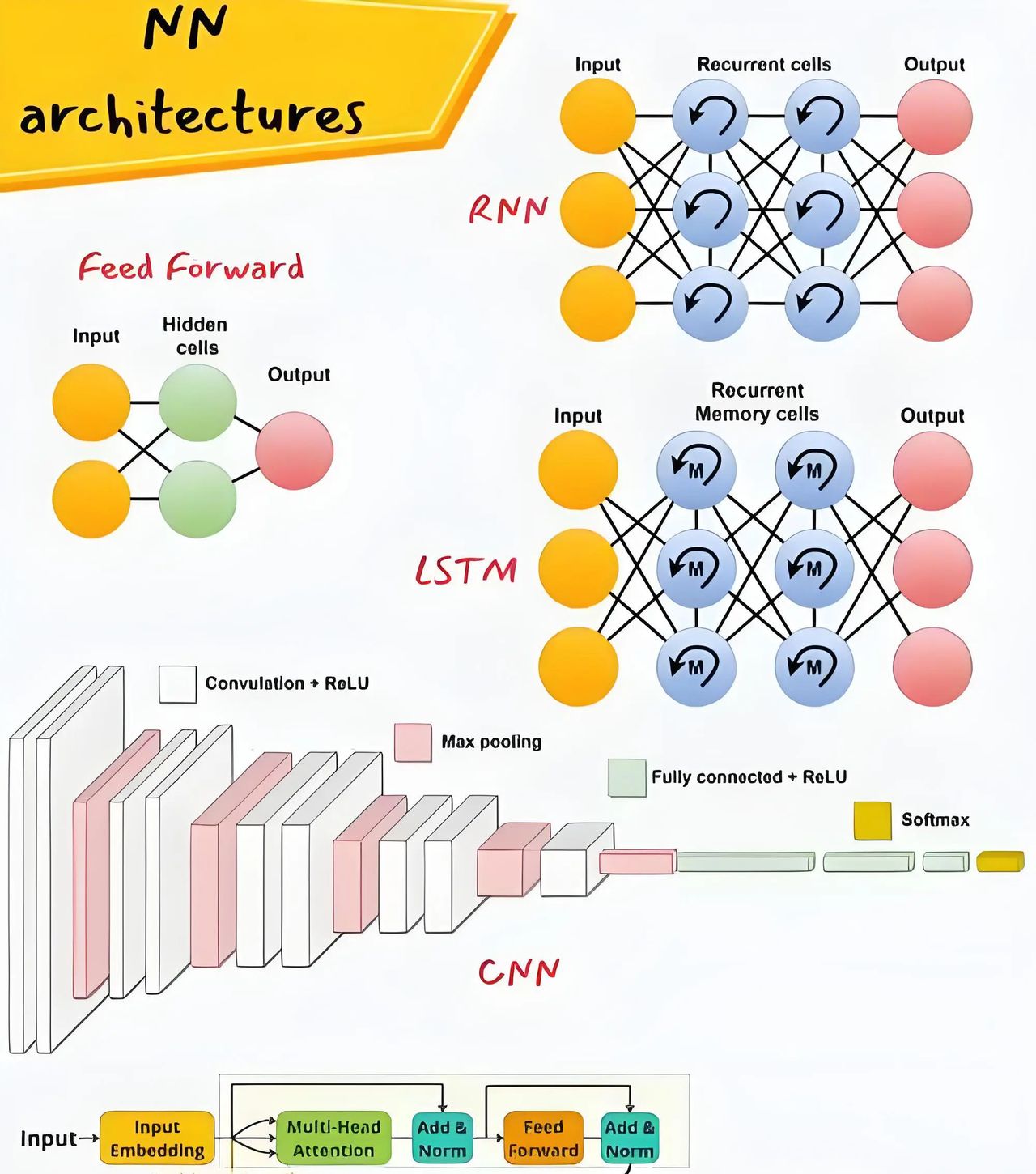
深度学习24种神经网络架构速览 。 感知器极简鼻祖 二分类 数据库编码 前馈网络FF全连接架构 图像 语音识别 径向基RBN函数逼近 股价预测神器 深度前馈DFF防过拟合 ECG降噪 循环RNN时序记忆 机器翻译 LSTM三道记忆门... 内容分享# AI入门# WordPress# 人工智能 9个月前250