
还在抱怨公司的AI搜索像“智障”?搜“销售合同”,它给你蹦出一堆“销售日报”?搜“2024财报”,它却给你展示“2023财报”?
别急,今天咱们不聊虚的,直接拆解一张企业级混合检索(Hybrid Search)架构图。这套方案完美解决了“搜不准”和“越权看”两大顽疾,是目前RAG(检索增强生成)项目中最硬核的落地实践!
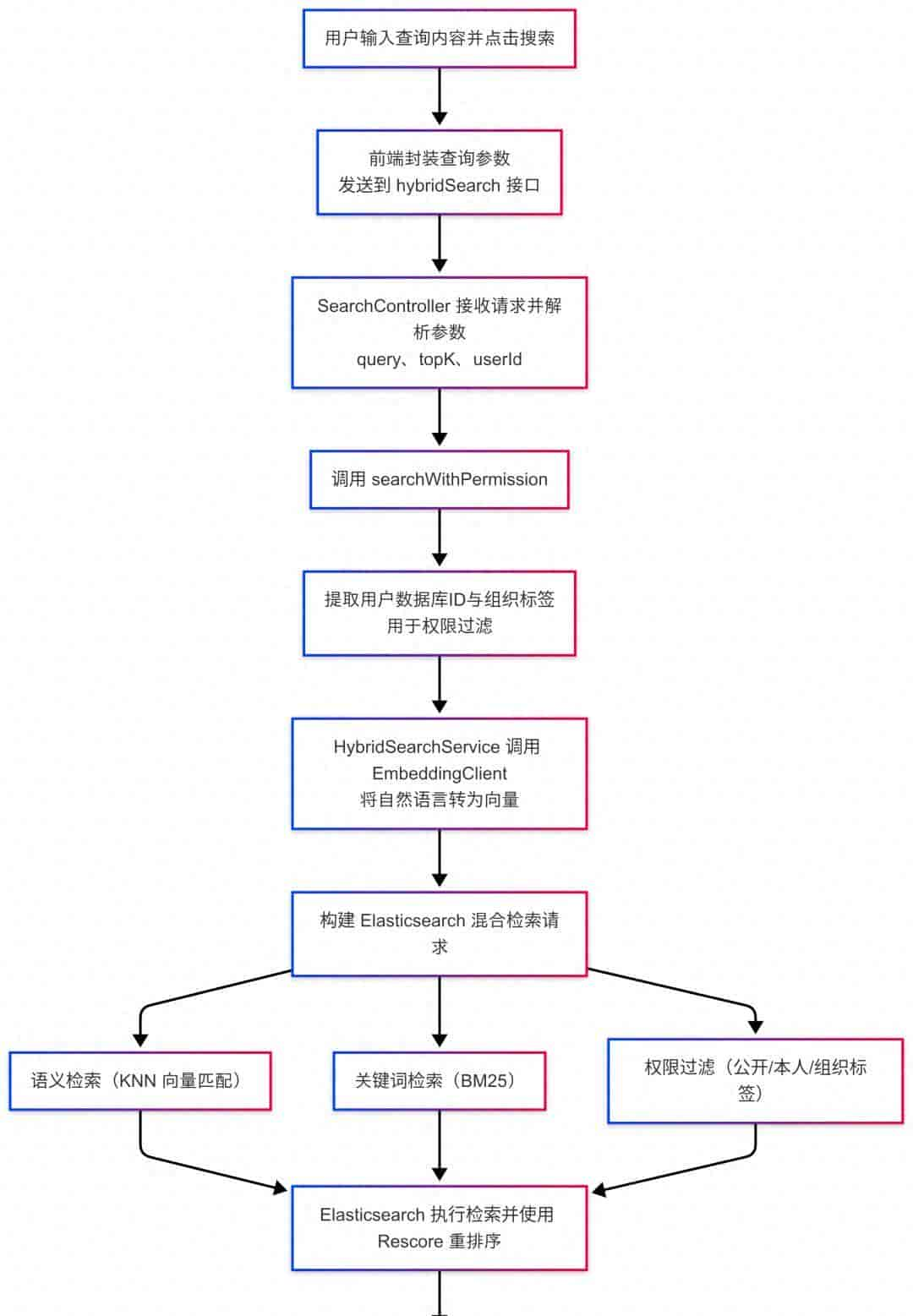
痛点:为什么传统搜索搞不定AI?
以前的搜索,要么是死板的关键词匹配(搜“苹果”绝不给你“水果”),要么是完全不可控的向量搜索(只要意思像就给你,完全不管权限)。
这张图展示的架构,核心就一个词:取长补短。它把“关键词匹配”的精准和“语义向量”的理解力结合在了一起,还顺手加了“权限锁”。
深度拆解:这4步是如何让搜索“变机智”的?
第一层:入口与鉴权(门卫要把好关)
流程一开始,用户输入内容,前端封装参数发给后端。注意图中的一个关键细节:提取用户数据库ID与组织标签。
这意味着,搜索还没开始,系统就已经知道你是谁了。是“公开数据”、“本人数据”还是“组织内数据”,这一步就已经在内存里画好了红线。这是许多开源项目最容易忽略的数据安全环节。
第二层:双管齐下(理解你的意图)
这是整个架构的灵魂!HybridSearchService调用EmbeddingClient,将你的自然语言转化为向量。
此时,系统并没有急着去搜,而是构建了一个Elasticsearch混合检索请求。它同时发起了三路进攻:
语义检索(KNN向量匹配):理解你话里的“潜台词”。列如你搜“怎么报销”,它能通过向量匹配找到“差旅费申报流程”,哪怕文档里根本没有“报销”这两个字。
关键词检索(BM25):死磕精准匹配。如果你搜“工号10086”,向量搜索可能会给你推“工号10085”,但BM25算法会死死咬住“10086”,保证精准度。
权限过滤:这是第三路并行线,直接把不属于你的数据挡在门外。
第三层:重排序(Rescore,优中选优)
这是许多新手架构师不知道的“杀手锏”。Elasticsearch在执行检索时,使用了Rescore机制。
简单说,就是先粗排一批结果,然后再用更精细的算法进行二次打分排序。这就像高考阅卷,先筛出及格卷,再由专家组进行二次复核,确保高分卷不被漏掉。
第四层:结果封装(最后的一公里)
经过打分、封装,最终返回给前端。用户看到的,既不是单纯的关键词堆砌,也不是毫无逻辑的语义联想,而是既懂我、又安全、还精准的完美答案。
结语:为什么这套架构值得抄作业?
这张图的价值在于它不仅仅是在做“搜索”,而是在做“业务赋能”。
技术融合:它没有盲目抛弃传统技术(BM25),而是将其与前沿AI技术(向量检索)结合,这是目前工业界最务实的做法。
安全落地:将权限过滤前置并融入检索链路,解决了AI落地企业最担心的数据泄露问题。
体验升级:通过Rescore重排序,极大地提升了用户满意度。
如果你正在做企业知识库、智能客服或者RAG项目,这张图就是你的标准答案。别再只用单一的向量数据库了,混合检索才是王道!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











