
彻底搞懂AI智能体:Python从入门到高级实战,带你构建下一代自动化工作流
“
导语:如果说2023年是“聊天机器人”的元年,2024年是“大型语言模型(LLM)应用”的爆发期,那么2025年,无疑是“自主AI智能体(AI Agents)”时代的开端。
它们是当前AI领域最热门的焦点。与传统的问答系统不同,智能体能够推理、规划、决策、使用工具、执行任务,甚至无需人工干预即可完成复杂的“使命”。掌握AI智能体的设计与构建,是把握下一代AI浪潮的关键所在。
本文将基于实战,从基础架构、核心技术(工具使用、记忆、规划)到高级工作流(LangChain、LangGraph、CrewAI)进行全面且深入的剖析。
”
一、AI智能体的本质:从“问答”到“任务完成”
1. 智能体的核心定义与能力(七大要素)
一个真正的AI智能体,并非一个简单的API调用,而是一个复杂的、有组织的智能软件实体。它必须具备七大核心能力,才能被称为“智能体”:
- 感知信息: 接收和理解来自环境或用户输入的各类信息。
- 推理分析: 对感知到的信息进行深度思考。
- 制定决策: 根据推理结果,决定下一步的最佳行动。
- 工具使用: 调动外部功能或API,扩大自身能力范围。
- 采取行动: 执行决策,在外部世界中产生实际效果。
- 学习适应: 从过往经验中汲取教训或调整策略。
- 达成目标: 最终目的是完成指定的复杂任务或目标。
2. LLM与AI Agent的根本区别
基础的大型语言模型(LLM),例如GPT-4o、Claude或Llama-3,只有在被赋予了以下关键组件和结构时,才能进化成为真正的AI智能体:
- 记忆功能
- 规划能力
- 工具调用
- 上下文自适应能力
- 自我反思机制
- 工作流或图结构
最简单的区分方式可以概括为:
“
聊天机器人回答问题,AI智能体完成任务。
”
以一个实际任务为例:“找出五款价格低于60,000卢比的最佳笔记本电脑,总结用户评论,并将最终清单通过邮件发送给我。”这是一个典型的多步骤复杂任务:
- 聊天机器人:无法直接完成。
- AI智能体:可以,由于它能使用搜索工具、数据提取工具,并利用推理完成总结和邮件发送流程。
3. AI Agent的应用前景:引领自动化浪潮
企业正在大规模构建AI智能体,覆盖了从内部运营到客户服务的多个领域:
- 编码自动化: 自动编写、测试和修复代码。
- 研究协助: 自动进行信息搜索和文献分析。
- 客户支持: 提供超越简单问答的深度问题解决服务。
- 数据提取: 从非结构化数据中准确抽取所需信息。
- 文档分析: 理解和处理复杂的合同、报告等。
- 工作流自动化: 连接并驱动企业内部的复杂流程。
- 内部知识系统: 负责知识的检索、更新与维护。
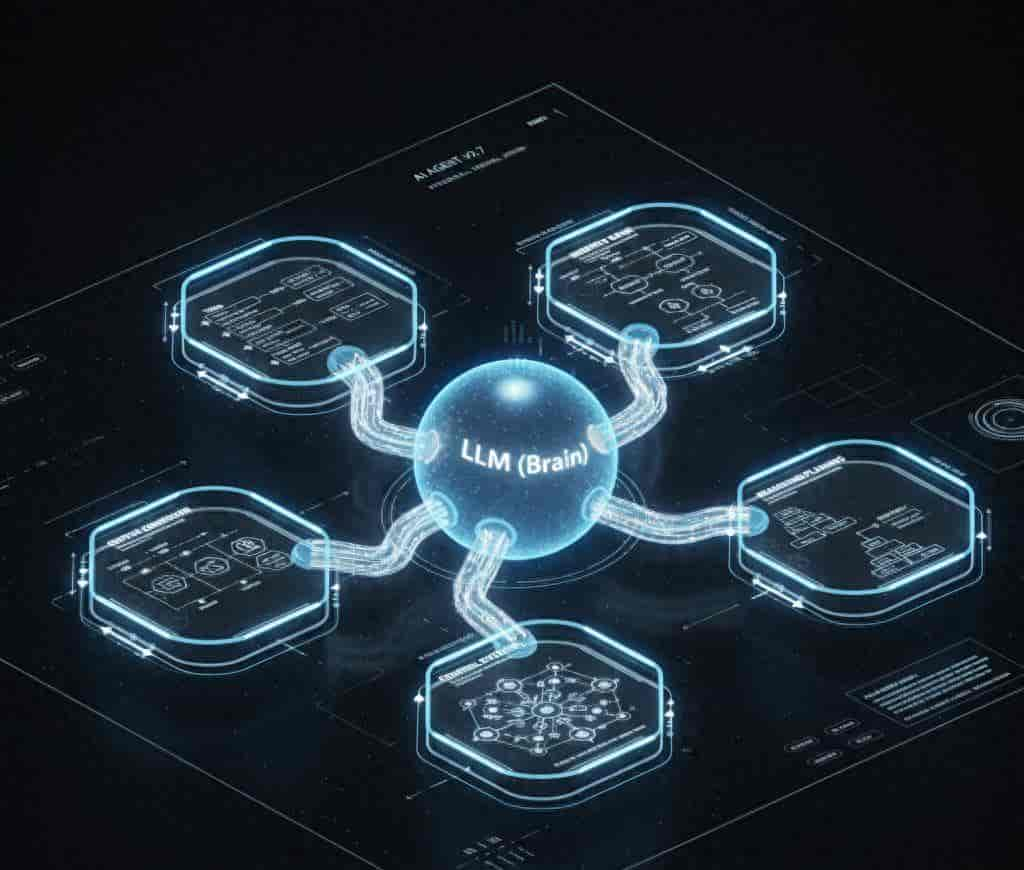
二、智能体的核心架构解析(六大支柱)
一个生产级的AI智能体,由六个不可或缺的部分构成,形成一个完整的执行系统:
组件名称 角色与功能 典型案例或技术 LLM (大脑) 智能体的核心智能和推理引擎。 GPT-4o, Claude, Llama-3, Mistral 工具(Tools) 智能体感知世界和执行行动的外部接口。 Web搜索、代码执行(REPL)、API调用、数据库访问 记忆(Memory) 保持上下文连贯性,避免重复犯错的基础。 短期记忆(会话)、长期记忆、向量数据库(RAG) 推理/规划(Reasoning/Planning) 决定执行顺序和策略的逻辑核心。 ReAct策略、分步骤思考链(CoT) 控制系统 负责协调任务的分解和执行的流程框架。 循环结构(Loops)、图结构(Graphs)、工作流 输出生成器 将结果转化为用户可读或可用的格式。 人类可读文本、结构化数据(JSON)
三、从零开始构建智能体:基础与工具使用
1. 静态智能体(Simple Agent):思考但不能行动
最基础的智能体只具备“思考”的能力。它接收任务,内部进行分解步骤,然后返回结果。
这是一个使用OpenAI API实现的静态代理的基本循环:
from openai import OpenAI
client = OpenAI()
def agent(task):
messages = [
{"role": "system", "content": "You are a helpful task-solving agent."},
{"role": "user", "content": f"Break down the task into steps and solve it. Task: {task}"}
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages
)
return response.choices[0].message["content"]
# 示例调用
# print(agent("Find three key benefits of using solar energy"))这个代理可以进行逻辑推理,例如列出太阳能的好处。但是,它无法通过外部工具进行搜索、计算或文件操作。它是一个功能受限的“思考者”。
2. 赋予行动力:“工具使用”(Tool Use)
工具是智能体能够成为实用系统的核心,它们赋予智能体实际的行动能力。
常见的工具类型包括:
- Python REPL(代码执行环境)
- Web搜索 API (例如SerpAPI)
- 文件操作(读写)
- 数据库访问
- 向量搜索(用于RAG,即检索增强生成)
- 自定义API调用
工具调用逻辑的核心在于:一个真实的智能体必须使用LLM来决定何时以及如何使用一个工具。
例如,为智能体添加一个简单的计算器工具:
import math
def calculate(expression):
try:
return str(eval(expression))
except:
return "Error"
# 智能体需要判断何时调用这个函数,
# 如果用户输入包含 "calculate:" 等关键词,则触发工具调用。
# tools = { "calculator": calculate }
# 在高级框架中,LLM将直接接收到工具定义,并根据任务自行判断调用。四、智能体的进化:多步骤推理与工作流
一个强劲的AI智能体,在接收任务后不会立即回复,而是会经历一系列的内部循环:
- 分步骤推理 (Step-by-step reasoning)
- 思维过程 (Thought processing)
- 规划 (Planning)
- 反思 (Reflection)
1. 基本多步骤推理循环的构建
这种循环确保智能体可以持续优化其答案,直到找到一个明确的终点(例如,包含“final answer”):
def reasoning_agent(task):
messages = [
{"role": "system", "content": "You are a reasoning agent."},
]
while True:
messages.append({"role": "user", "content": task})
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages
)
content = response.choices[0].message["content"]
messages.append({"role": "assistant", "content": content}) # 将助手的回复作为上下文存入
if "final answer" in content.lower():
return content
# 在实际应用中,这里会有工具调用逻辑,根据 content 的内容判断是否需要进一步行动
本质: 智能体通过重复的思维周期来持续改善和收敛其任务解决方案。
2. 利用LangChain实现简单智能体
LangChain是一个强劲的框架,它提供开箱即用的代理架构,极大地简化了工具启用和推理能力的实现。
通过LangChain,开发者可以轻松地将多个工具(例如serpapi进行搜索和llm-math进行数学计算)结合起来,并采用ReAct (Reasoning and Acting) 策略进行动态决策:
# 安装: pip install langchain langchain-openai
from langchain.agents import initialize_agent, load_tools
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
# 加载搜索和数学计算工具
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 初始化一个 ReAct 策略的智能体
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description" # 赋予工具使用和ReAct策略
)
# result = agent.run("What is 25 squared plus 13?")
# 智能体将动态决定是先调用数学工具还是直接回答。通过这种方式,我们获得了具备:工具使用能力、ReAct策略、动态决策能力以及内部推理能力的强劲智能体。
五、高级智能体系统:多Agent协作与内存管理
当任务复杂度超过单个智能体能处理的范畴时,就需要引入多智能体系统(Multi-Agent Systems)。
1. LangGraph:构建状态驱动的智能体网络
LangGraph是用于构建复杂、多阶段、有状态的代理网络或图结构的工具。它能够明确定义任务的执行路径和不同组件之间的交接。
应用场景:
- 多智能体之间的复杂协作
- 需要严格流程控制的代理
- 带有记忆、状态追踪的深度研究流水线
LangGraph通过**状态图(StateGraph)**定义节点和边,明确了流程:
# 安装: pip install langgraph
from langgraph import StateGraph
def step1(state):
state["a"] = "processed A"
return state
def step2(state):
state["b"] = "processed B"
return state
graph = StateGraph()
graph.add_node("A", step1)
graph.add_node("B", step2)
graph.set_entry_point("A") # 设置起始节点
graph.add_edge("A", "B") # 定义A完成后进入B
agent = graph.compile()
# print(agent.invoke({})) # 执行结果将先走step1,再走step2这是构建高度定制化的、具有严格流程控制的AI工作流的基础。
2. CrewAI:实现团队化的Agent协作
CrewAI框架专注于多智能体的协作和团队任务,它模拟了现实世界中团队合作的工作模式。
核心概念: Agent(定义角色和目标)、Task(定义任务和描述)、Crew(将Agent和Task组合)。
# 安装: pip install crewai
from crewai import Agent, Task, Crew
# 定义两个具备不同角色的智能体
researcher = Agent(role="Researcher", goal="Collect accurate data") # 研究员目标是收集数据
writer = Agent(role="Writer", goal="Write a summary") # 作者目标是写总结
# 定义两个有先后依赖的任务
task1 = Task(agent=researcher, description="Research solar energy benefits")
task2 = Task(agent=writer, description="Summarize findings") # 只有在researcher完成后writer才能开始
crew = Crew(agents=[researcher, writer], tasks=[task1, task2])
# result = crew.run() # 启动团队协作流程通过CrewAI,真正的AI工作流以更自然、更结构化的方式被建立起来,任务被分解给具备专业角色的智能体,提高了效率和准确性。
3. 智能体的“记忆”体系
记忆对于智能体至关重大,它可以协助智能体:
- 维持长对话的上下文(避免重复输入)。
- 避免重复执行已完成的任务(避免重复犯错)。
- 检索过去经验(用于学习和适应)。
记忆类型:
- 短期记忆: 一般是最近的对话记录。
- 长期记忆: 存储实际性知识或重大的历史交互记录。
- 向量记忆(RAG): 使用向量数据库(Vector Search)进行信息检索和增强生成。
在生产环境中,需要使用专业的向量数据库工具实现长期记忆和RAG:
- FAISS
- Pinecone
- Weaviate
六、实战应用与部署:从项目到云端
1. 案例项目:研究与总结Agent
这是一个高度实用的智能体项目,旨在:网络搜索信息、提取关键数据、生成总结、并输出一份最终报告。
这个任务需要一个拥有强劲工具和推理能力的智能体:
from langchain.agents import initialize_agent, load_tools
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
# 只加载一个Web搜索工具
tools = load_tools(["serpapi"])
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description"
)
query = "Research top electric cars in India 2025 and summarize the advantages."
# print(agent.run(query))
# 智能体将自行规划:1. 识别需要搜索; 2. 调用serpapi; 3. 对结果进行总结; 4. 输出最终报告。价值洞察: 这种具备搜索、推理、总结能力的Agents,是当前许多AI初创企业正在构建的核心产品。
2. 智能体的API部署方法
将智能体投入实际生产,一般需要将其封装为Web服务API。使用像FastAPI这样的现代Python框架可以高效完成:
from fastapi import FastAPI
# 假设上面的 Agent 已经被初始化
# from YOUR_AGENT_FILE import agent
app = FastAPI()
@app.get("/agent")
def run_agent(q: str):
"""通过GET请求运行智能体任务"""
# 接收查询字符串 q,并将其输入给智能体运行
return {"answer": agent.run(q)}
# 部署路径:
# 1. 使用 uvicorn 在本地运行。
# 2. 通过Docker进行容器化。
# 3. 部署到云服务(如 Cloud Run 或 AWS EC2)七、总结与进阶:成功AI智能体的八大原则
一个能够在实际业务中成功的AI智能体,并非依赖单一模型,而是遵循一系列经过验证的设计原则。只有掌握这些模式,才能构建出可用于生产环境的Agents。
1. 智能使用工具(Intelligent Tool Use): 核心不在于工具的数量,而在于智能体能准确地判断何时、如何调用正确的工具,以最高效率达成目标。
2. 先规划后行动(Plan Before Acting): 避免“拍脑袋”式的决策。成功的Agent会先进行多步骤推理和任务分解,生成内部规划,再执行具体动作。
3. 任务分解(Subtask Breakdown): 复杂任务必须被分解为小的、可管理且独立的子任务,这有利于提高每一步的准确性和效率。
4. 维护记忆(Maintain Memory): 保持短期和长期记忆,确保会话连贯性,并利用历史数据进行适应和改善。
5. 灵活运用向量搜索(RAG): 当需要从海量专有文档或知识库中提取信息时,必须结合RAG(向量搜索)来确保结果的准确性和减少“幻觉”。
6. 遏制幻觉(Stop Hallucinations): 通过多步骤的推理循环、实际核查工具和反思机制,减少LLM编造实际的倾向。
7. 产出可验证的结果(Verifiable Outputs): 确保Agent的最终结果可以被用户或后续系统进行核实,提高整体系统的可信赖度。
8. 采用图工作流(Use Graph Workflows): 对于涉及复杂顺序、条件分支或多Agent协作的流程,利用LangGraph等图结构进行清晰的流程管理。
结论:开发者掌握Agent技能正当其时
AI智能体不再是遥远的概念,它们正在迅速成为企业自动化和Python开发的新基础。
- 传统的聊天机器人将被具有更强执行力的Agents取代。
- 基础的搜索功能将被具有RAG能力的Agents取代。
- 未来的工作场景将是人类与协作型Agent团队共同完成任务。
通过掌握核心架构、推理循环、工具调用、多Agent系统和内存集成,您已具备进入下一代AI工程师行列所需的全部知识。
行动提议: 从一个最简单的Agent开始,逐步为其添加工具、记忆,最终将其进化为基于LangGraph/CrewAI的协作型工作流,并尝试部署上线。这一实践路径将定义您在AI自动化领域的新核心竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。















[db:评论]