前言 在互联网项目里,数据库永远是性能瓶颈的“重灾区”。 一句慢SQL就能让服务器CPU飙到100%,一次深度分页就能把响应时间从50ms干到10秒以上。 今天这篇干货,把我这几年踩过的所有MySQL坑、用过的所有优化手段全部整理成一份“保姆级”实战指南,直接可抄作业!
一、MySQL优化全景图:先搞清楚从哪下手

优化MySQL,永远记住这4个层次(从上到下性价比递减):
|
层次 |
优化手段 |
典型收益 |
|
SQL和索引 |
索引优化、SQL改写 |
10倍~100倍+ |
|
架构层 |
读写分离、分库分表、缓存 |
3~10倍 |
|
配置层 |
Buffer Pool、连接池参数调优 |
30%~200% |
|
硬件层 |
加内存、换SSD |
钱能解决的事… |
记住:80%的性能问题来自20%的垃圾SQL,先用慢查询日志+EXPLAIN找出来,再动手!
二、索引优化:性能提升的第一把屠龙刀
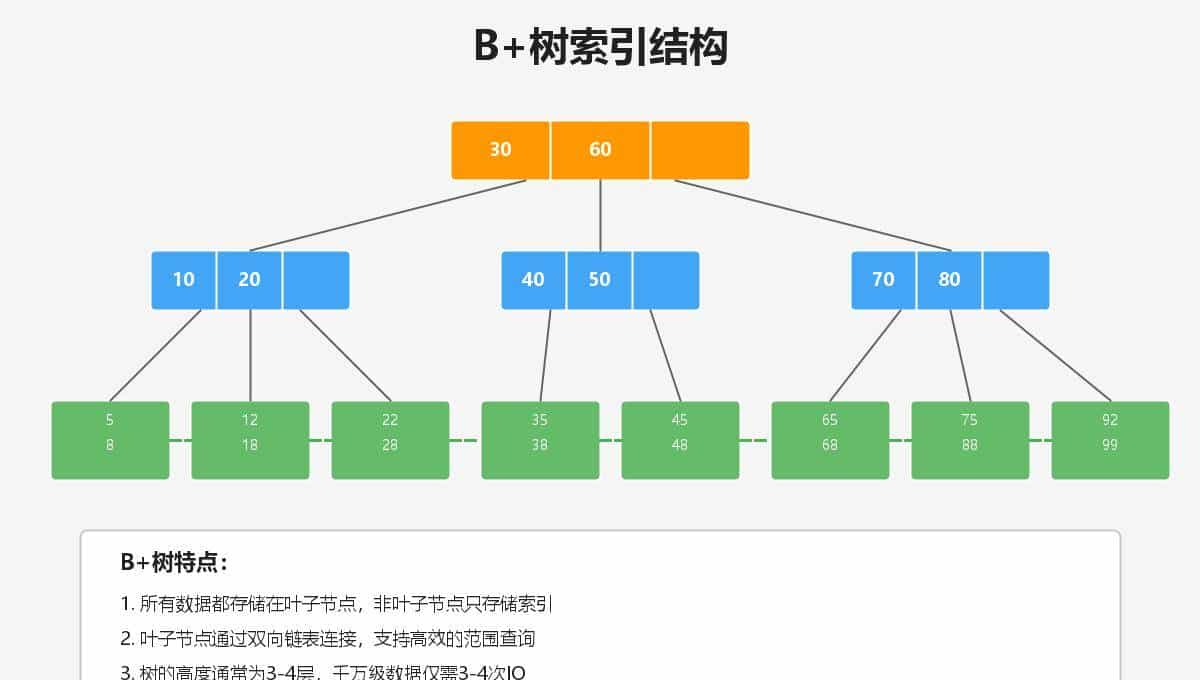
1. 索引失效最常见的8个坑(必背!)
- 对索引列使用函数 → 失效 ❌ WHERE YEAR(create_time) = 2024;
- 正确姿势:WHERE create_time BETWEEN '2024-01-01' AND '2024-12-31 23:59:59';
- 隐式类型转换 → 失效 ❌ phone VARCHAR 却写 WHERE phone = 13800138000(数字) 正确姿势:加引号 '13800138000';
- 最左前缀法则被违反 联合索引 (a,b,c) 能用:a=?a=? AND b=?a=? AND b=? AND c=? 不能用:b=?c=?;
- OR条件太多 → 可能不走索引;
- LIKE以%开头 → 失效;
- != / NOT IN → 基本不走索引;
- NULL值判断用 IS NULL 才走索引;
- ORDER BY / GROUP BY 字段不在索引里 → Using filesort(慢得要死);
2. EXPLAIN执行计划必看字段
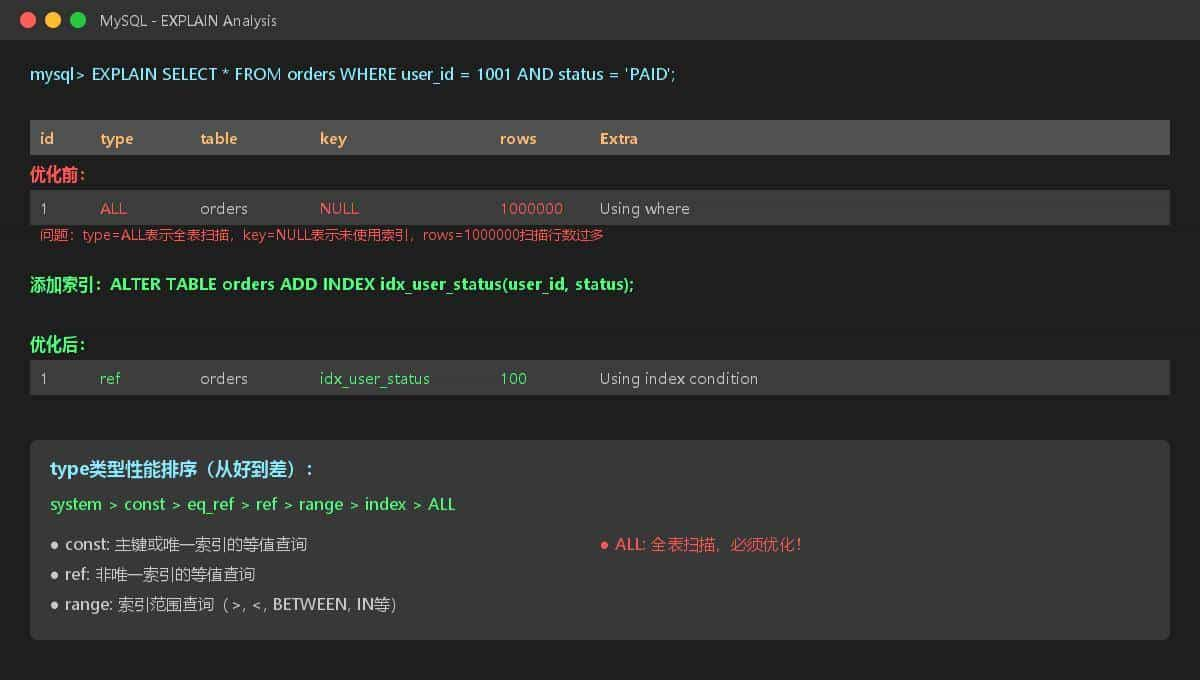
|
字段 |
关注点 |
红线警报 |
|
type |
至少range,最好ref/const |
ALL/index = 赶紧优化 |
|
key |
是否使用了你期望的索引 |
null = 没走索引 |
|
rows |
扫描行数,越小越好 |
几万、几十万 = 危险 |
|
Extra |
Using filesort / Using temporary |
出现就必须干掉 |
三、SQL优化实战案例(直接抄)
1. 深度分页:从10秒到30ms
❌ 经典慢到吐血写法
SQL
SELECT * FROM orders ORDER BY id LIMIT 1000000,10;正确姿势1:游标分页(推荐!)
SQL
SELECT * FROM orders WHERE id > 1000000 ORDER BY id LIMIT 10;正确姿势2:子查询+延迟关联
SQL
SELECT o.* FROM orders o
INNER JOIN (
SELECT id FROM orders ORDER BY id LIMIT 1000000,10
) t ON o.id = t.id;2. 批量插入:从30秒到300ms
❌ 循环单条insert(1万条要30秒)
Java
for (User user : list) {
jdbcTemplate.update("INSERT INTO user...");
}正确姿势:开启rewriteBatchedStatements
YAML
# application.yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true- 使用 batchUpdate,1万条数据只需200~500ms!
3. JOIN优化铁律:小表驱动大表
SQL
-- 用户1万,订单1000万
-- 正确写法(小表在前)
SELECT ... FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE u.status = 'VIP';
-- 务必给 orders.user_id 加索引!四、连接池别乱配!HikariCP最优参数
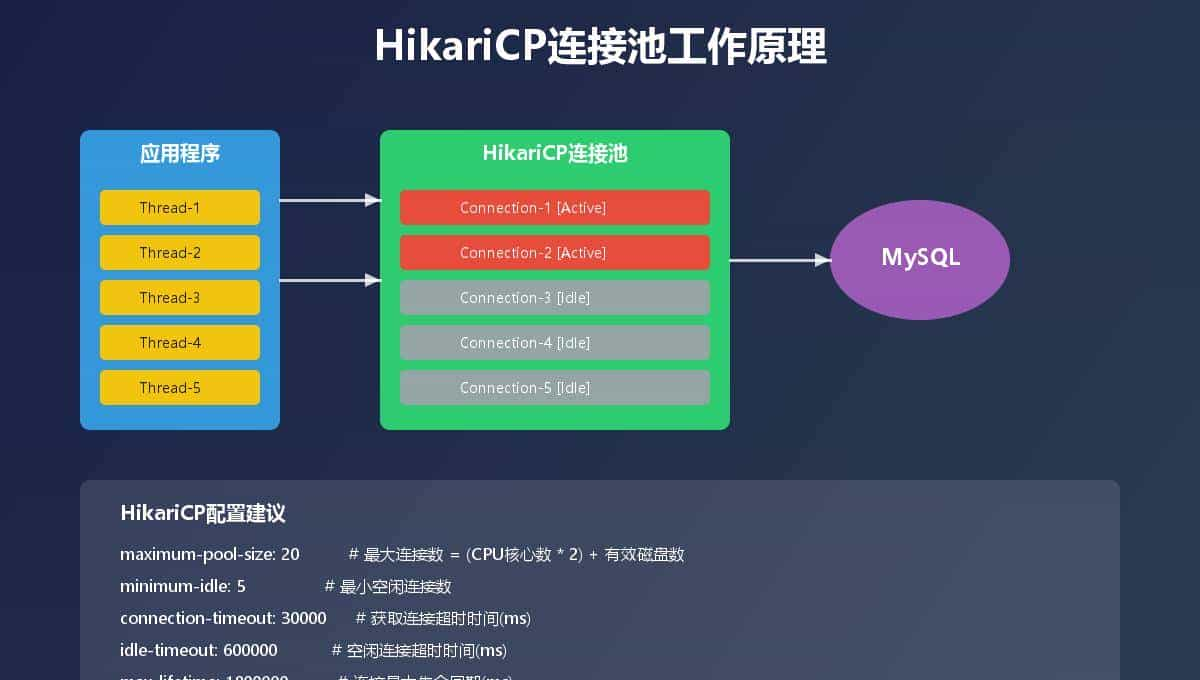
YAML
spring:
datasource:
hikari:
maximum-pool-size: 20 # (核心数×2)+磁盘数 ≈ 20
minimum-idle: 5
connection-timeout: 10000
idle-timeout: 600000
max-lifetime: 1800000五、读写分离 + 分库分表门槛
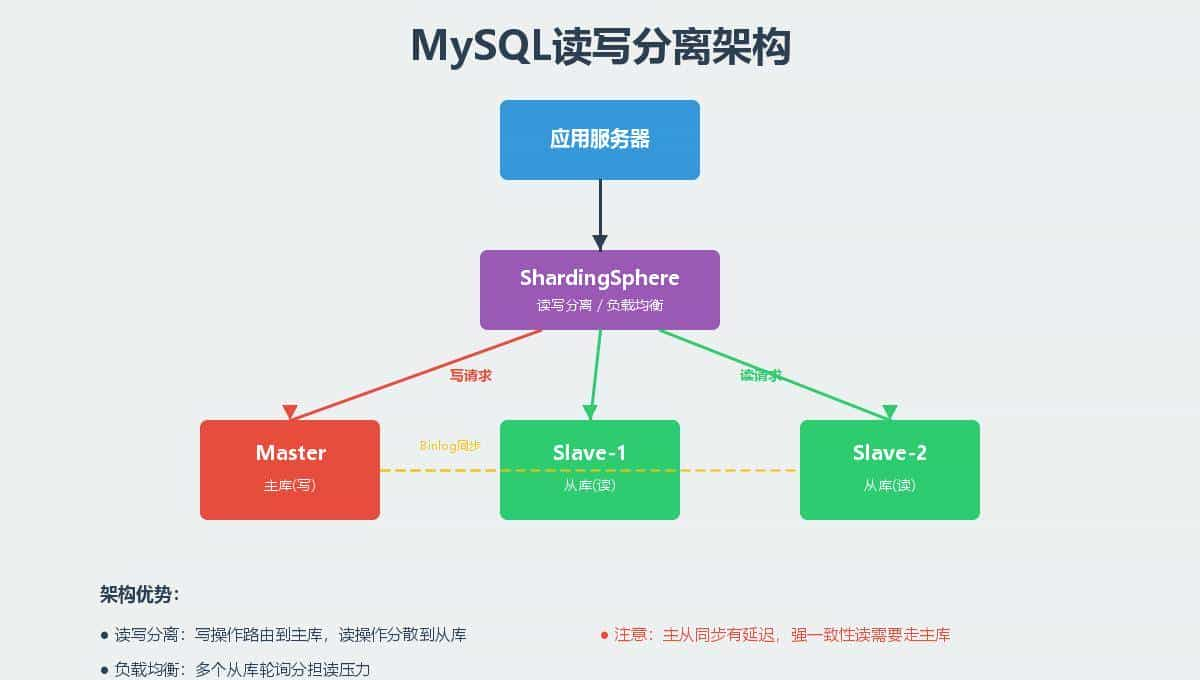
- 单表 > 1000万行 或 单库 > 100GB → 必须思考分库分表
- 读多写少 → 读写分离(一主多从 + ShardingSphere-JDBC/MyCat)
- 分布式ID → 雪花算法(Snowflake)最稳
六、生产真实案例:订单列表从5秒→50ms
原SQL:
SQL
SELECT * FROM orders
WHERE user_id = 888 AND status IN ('PAID','SHIPPED')
ORDER BY create_time DESC LIMIT 20;→ type=ALL,扫描100万行
优化后:
SQL
ALTER TABLE orders ADD INDEX idx_user_status_time(user_id,status,create_time);→ type=ref,扫描80行,响应时间 5s → 50ms,性能提升100倍!
七、MySQL核心参数(直接抄)

ini
innodb_buffer_pool_size = 70%~80% 物理内存 # 最重大!
innodb_buffer_pool_instances = CPU核心数
innodb_log_file_size = 1G
innodb_flush_log_at_trx_commit = 1 # 强一致性选1,性能可选2
max_connections = 500~1000Buffer Pool命中率必须 > 99%!
最后送你一份MySQL优化检查清单(收藏!)

- 慢查询日志是否开启?
- 所有线上SQL都EXPLAIN过吗?
- 有没有type=ALL的语句?
- 深度分页改成游标分页了吗?
- 批量操作开启rewriteBatchedStatements了吗?
- Buffer Pool命中率>99%了吗?
- 读压力都扔给从库了吗?
© 版权声明
文章版权归作者所有,未经允许请勿转载。














MySQL性能优化实战
收藏了,感谢分享