声明
本文中的所有案例代码、配置仅供参考,如需使用请严格做好相关测试及评估,对于因参照本文内容进行操作而导致的任何直接或间接损失,作者概不负责。本文旨在通过生动易懂的方式分享实用技术知识,欢迎读者就技术观点进行交流与指正。
引言部分
你是否也曾有过这样的经历:接手一个基于 SpringBoot 2.7.8 和 Java 1.8 的项目,它曾是团队的骄傲,稳定运行了数年。但随着业务量的增长,用户开始抱怨页面加载缓慢、接口响应超时。你打开监控面板,看到CPU使用率偶发刺高,GC频繁,数据库连接池时常告警。你尝试过增加服务器内存,但效果甚微,仿佛陷入了一个无解的泥潭。
别担心,你遇到的并非个例。在技术日新月异的今天,大量成熟且稳定的老项目依然在支撑着核心业务。直接升级到最新框架版本风险高、成本大,但坐视性能瓶颈不管又影响用户体验。本文将为你揭示 5 个针对这套经典技术栈的“性能秘籍”,它们并非高深莫测的黑科技,而是经过实践检验、易于落地的优化策略。我们将从启动、运行、并发、缓存等多个维度入手,让你的老项目在不进行大刀阔斧重构的前提下,重新焕发活力,显著提升性能表现。
背景知识
在深入优化之前,我们先快速回顾一下这套技术栈的核心概念和现状。
1. 技术概念简介
•Spring Boot 2.7.8: 这是 Spring Boot 2.x 分支中的一个成熟稳定版本。它极大地简化了 Spring 应用的初始搭建和开发过程,通过“约定优于配置”的理念,内置了自动配置机制。其核心是 Spring Framework,提供了依赖注入(DI)和面向切面编程(AOP)等强劲功能。
•Java 1.8 (Java 8): 这是一个具有里程碑意义的 Java 版本,引入了 Lambda 表达式、Stream API、新的日期时间 API (java.time) 以及 CompletableFuture 等关键特性,极大地提升了开发效率和代码表达能力。至今,它仍是许多企业生产环境中的主力版本。
2. 发展现程与现状分析
尽管 Spring Boot 3.x 和 Java 17/21 已经成为新项目的首选,但 Spring Boot 2.7.x + Java 8 的组合因其极高的稳定性和生态成熟度,在金融、政务、传统企业等领域拥有庞大的存量市场。这些系统承载着关键业务,追求的是“稳定压倒一切”。因此,对它们的优化更多是“精雕细琢”,而非“推倒重来”。
3. 核心原理解释
Spring Boot 应用的性能瓶颈一般源于几个核心环节:Bean 的初始化、I/O 操作(数据库、网络)、JVM 的内存管理(GC)以及重复计算。我们的优化策略也将围绕这些环节展开。
为了更直观地理解这些概念之间的关系,我们可以用下面的思维导图来展示:
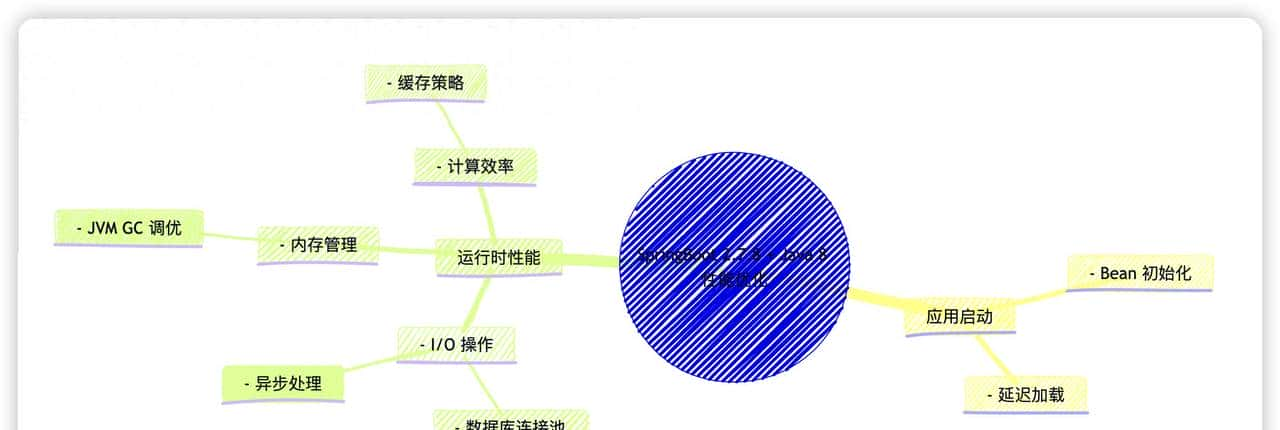
图1:SpringBoot 2.7.8 + Java 8 性能优化核心领域思维导图 该图清晰地展示了我们将要探讨的四大优化领域:应用启动、I/O操作、内存管理和计算效率,以及它们各自包含的关键技术点。
问题分析
让我们深入剖析一下,在这些经典技术栈中,性能瓶颈一般是如何产生的。
1. 详细剖析技术难点
•启动缓慢与资源占用高: Spring Boot 默认会在启动时实例化所有单例 Bean。对于大型应用,这意味着大量的初始化工作、内存占用和更长的启动时间。在微服务架构中,这会直接影响服务的扩缩容速度。
•数据库访问瓶颈: 数据库是绝大多数 Web 应用的性能核心。一个配置不当的连接池(如最大连接数过小、连接超时时间过长)会降低应用吞吐量,导致大量请求阻塞等待数据库连接。
•同步阻塞模型: 传统的 Spring MVC Controller 是同步阻塞的。一个请求线程在处理耗时操作(如调用第三方服务、读写大文件)时,会一直被占用,无法处理其他请求。在高并发场景下,线程池很快就会耗尽。
•JVM GC 停顿: Java 8 默认的并行回收器在处理大内存应用时,可能会发生长时间的“Stop-The-World”(STW)停顿,导致应用响应卡顿甚至超时。
•重复计算与查询: 对于一些“读多写少”的数据,如商品信息、配置项,每次请求都去数据库查询或重新计算,是对资源的巨大浪费。
2. 常见解决方案及其局限性
•增加服务器资源: 这是最直接但治标不治本的方法。成本高,且无法解决代码层面的效率问题。
•代码重构: 成本高、风险大,对于稳定运行的老项目来说,管理层和测试团队往往难以接受。
•引入缓存: 许多人会想到 Redis,但这引入了新的外部依赖,增加了系统复杂度和运维成本。对于简单的缓存场景,有些资源浪费了。
3. 关键挑战的技术本质
这些问题的本质在于资源利用效率低下。无论是 CPU、内存还是 I/O,都存在着等待和浪费。我们的目标就是通过精细化的配置和代码层面的改善,最大限度地减少这种浪费。
下面的流程图展示了一个典型的同步请求处理流程,并标注了潜在的瓶颈点:
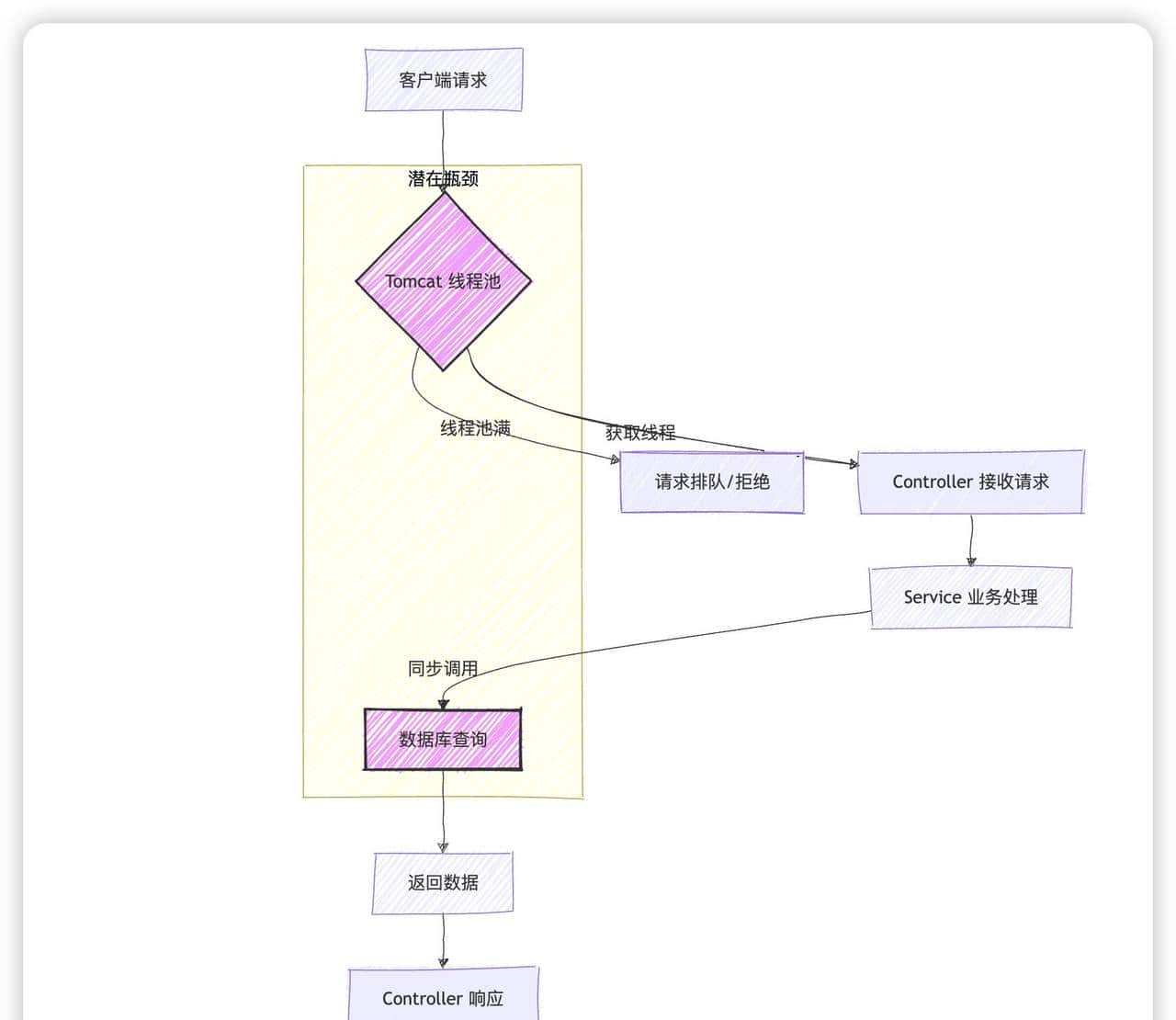
图2:典型同步请求处理流程与瓶颈分析 此流程图清晰地展示了,在同步模型下,Tomcat 线程池和数据库查询是两个主要的瓶颈点。当线程池满时,新请求会被排队或拒绝;数据库查询耗时则会长时间占用线程。
解决方案详解
针对上述问题,我们提出以下五个具体、可操作的优化方案。
方案一:启用全局延迟初始化,加速应用启动
原理: Spring Boot 2.2+ 版本引入了 spring.main.lazy-initialization 配置。开启后,所有 Bean 将不会在启动时立即创建,而是在第一次被使用时才初始化。这能显著缩短应用启动时间,并减少初始内存占用。
实现细节: 在 application.properties 或 application.yml 中添加一行配置即可。
# application.properties
spring.main.lazy-initialization=true最佳实践:
•适用场景: 微服务、对启动速度敏感的应用、或开发调试阶段。
•注意事项: 延迟初始化可能会将一些配置错误(如数据库连接失败、Bean 依赖缺失)推迟到运行时才暴露,增加了线上排错难度。提议在充分测试后再应用到生产环境。
方案二:精细化调优 HikariCP 连接池
原理: HikariCP 是 Spring Boot 2.x 默认的数据库连接池,以其高性能和稳定性著称。但默认配置较为保守,无法适应所有场景。根据业务负载特征调整其参数,是提升数据库访问性能最直接有效的方法。
核心组件/模块说明:
•maximum-pool-size: 连接池允许的最大连接数。这是最重大的参数,需根据数据库服务器性能和应用并发量综合评估。
•minimum-idle: 连接池保持的最小空闲连接数。
•connection-timeout: 客户端等待从连接池获取连接的最长时间。
•idle-timeout: 空闲连接存活的最长时间,超过此时间则被回收。
关键实现细节: 在 application.properties 中进行配置:
# HikariCP Fine-tuning
# 连接池最大连接数,应根据数据库承载能力设定
spring.datasource.hikari.maximum-pool-size=20
# 连接池最小空闲连接数
spring.datasource.hikari.minimum-idle=5
# 等待连接池分配连接的最大时长(毫秒),超过该时长未获取到连接则抛出异常
spring.datasource.hikari.connection-timeout=30000
# 一个连接空闲状态的最大时长(毫秒),超时则被释放
spring.datasource.hikari.idle-timeout=600000
# 连接的最大生命周期(毫秒),超时则被回收
spring.datasource.hikari.max-lifetime=1800000架构图: 下图展示了优化后的连接池工作流程:
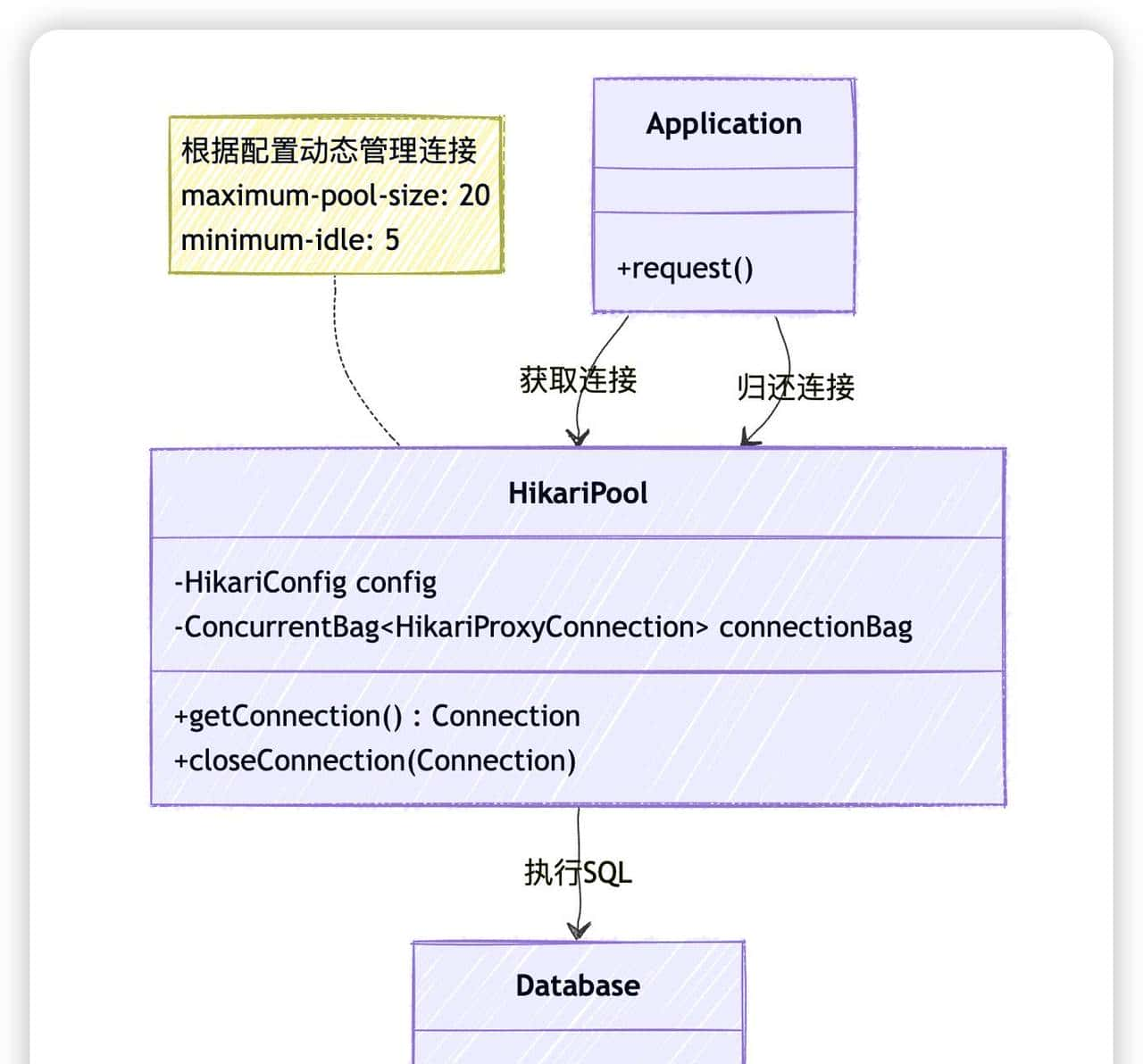
图3:HikariCP 连接池工作原理类图 该图描述了应用、HikariCP连接池和数据库之间的交互关系。HikariPool作为中间层,根据配置参数管理着物理连接的创建、分配和回收。
方案三:引入异步处理,提升系统吞吐量
原理: 对于耗时且非核心的 I/O 操作(如发送邮件、记录日志、调用第三方服务),可以使用 Spring 的 @Async 注解将其异步化。主线程会立即返回,而耗时任务则交由一个独立的线程池处理,从而快速释放请求线程,提升整体吞吐量。
核心组件/模块说明:
•@EnableAsync: 在配置类上开启异步支持。
•@Async: 标记在需要异步执行的方法上。
•TaskExecutor: 自定义线程池,替代默认的 SimpleAsyncTaskExecutor,以更好地控制线程资源。
关键实现细节与代码示例:
1.配置异步线程池:
// 包名称,请自行替换.config
package 包名称,请自行替换.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
@EnableAsync // 安全提示:开启异步功能,需注意线程安全和异常处理
public class AsyncConfig {
@Bean(name = "taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数
executor.setCorePoolSize(5);
// 最大线程数
executor.setMaxPoolSize(20);
// 队列容量
executor.setQueueCapacity(100);
// 线程名前缀
executor.setThreadNamePrefix("Async-");
executor.initialize();
return executor;
}
}2.在 Service 中使用:
// 包名称,请自行替换.service
package 包名称,请自行替换.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
@Service
public class NotificationService {
private static final Logger log = LoggerFactory.getLogger(NotificationService.class);
/**
* 模拟发送邮件的耗时操作
* @param email 收件人邮箱,如有需要自行替换
* @param content 邮件内容
*/
@Async("taskExecutor") // 指定使用我们配置的线程池
public void sendEmail(String email, String content) {
log.info("开始发送邮件给: {}", email);
try {
// 模拟耗时操作,例如调用邮件服务API
Thread.sleep(3000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("发送邮件任务被中断", e);
}
log.info("邮件发送成功: {}", email);
}
}流程图: 下面的时序图展示了同步与异步处理的区别:
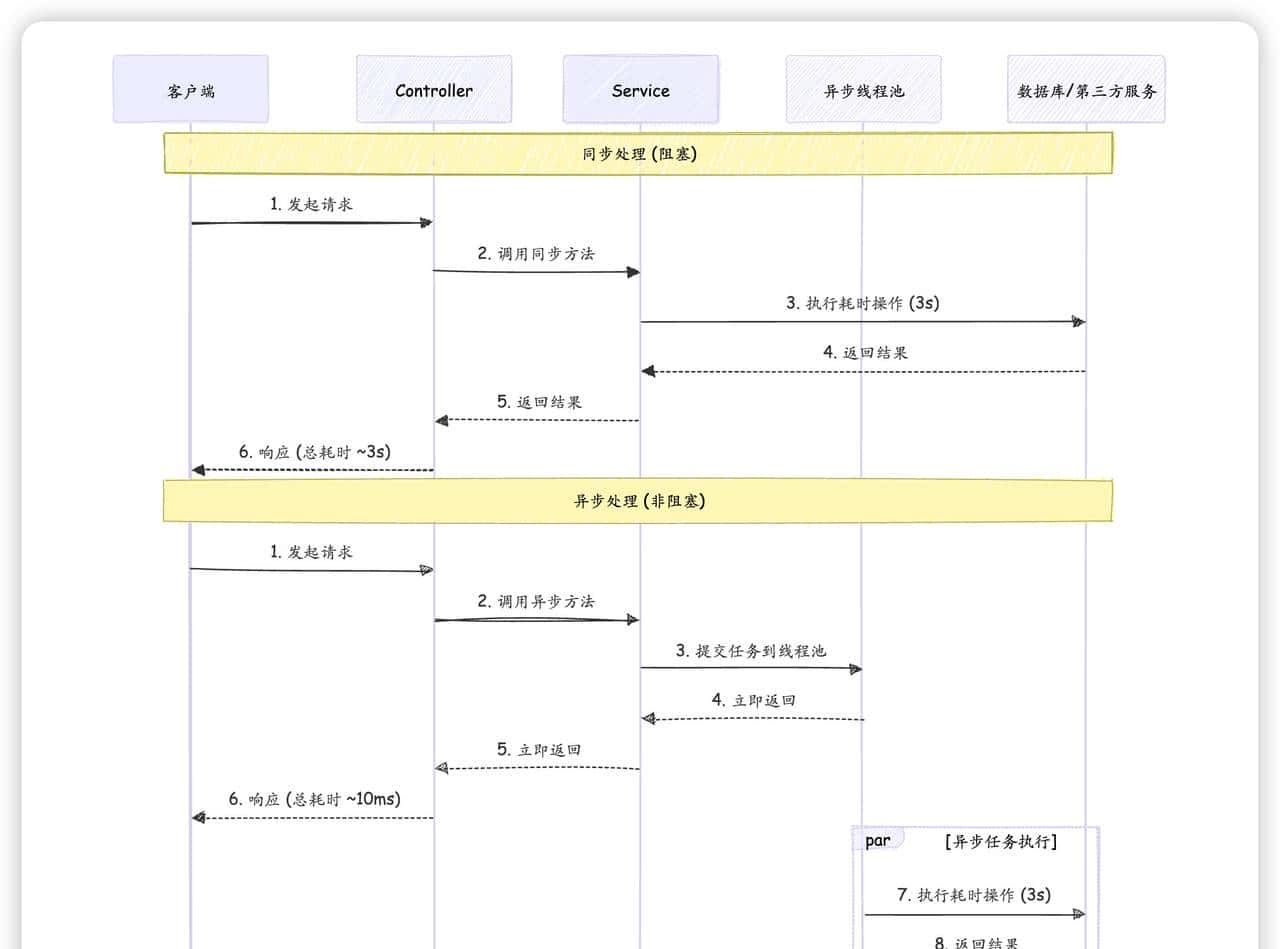
图4:同步与异步处理时序对比图 该图直观地展示了异步处理如何将主线程从耗时操作中解放出来,使得客户端能够更快地收到响应,从而提升了系统的并发处理能力。
方案四:拥抱 Caffeine 本地缓存,减少重复计算
原理: 对于那些变化不频繁但访问频繁的数据,使用本地缓存是性价比极高的优化手段。Caffeine 是 Java 8 时代的高性能缓存库,Spring Boot 2.x 对其有良好的支持。通过 @Cacheable 等注解,可以极简地实现方法级缓存。
核心组件/模块说明:
•@EnableCaching: 开启缓存功能。
•@Cacheable: 标记在方法上,表明该方法的返回结果应该被缓存。下次调用时,如果缓存中存在,则直接返回缓存值,而不执行方法体。
•CacheManager: 缓存管理器,用于创建和管理缓存实例。
关键实现细节与代码示例:
1.添加 Maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>2.配置 Caffeine:
// 包名称,请自行替换.config
package 包名称,请自行替换.config;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
@Configuration
@EnableCaching // 安全提示:开启缓存功能,需注意数据一致性问题
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
// 初始容量
.initialCapacity(100)
// 最大容量,超过后采用LRU策略淘汰
.maximumSize(1000)
// 写入后过期时间
.expireAfterWrite(10, TimeUnit.MINUTES)
// 记录缓存命中率等统计信息
.recordStats());
return cacheManager;
}
}3.在 Service 中使用:
// 包名称,请自行替换.service
package 包名称,请自行替换.service;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import 包名称,请自行替换.model.Product;
import java.math.BigDecimal;
import java.util.HashMap;
import java.util.Map;
@Service
public class ProductService {
// 模拟数据库存储
private static final Map<Long, Product> PRODUCT_DB = new HashMap<>();
static {
// 此处可自行连接数据库进行验证
PRODUCT_DB.put(1L, new Product(1L, "Laptop", new BigDecimal("999.99")));
PRODUCT_DB.put(2L, new Product(2L, "Mouse", new BigDecimal("19.99")));
}
/**
* 根据ID查询商品信息,并缓存结果
* @param id 商品ID
* @return 商品信息
*/
@Cacheable(value = "products", key = "#id")
public Product findProductById(Long id) {
System.out.println("从数据库查询商品,ID: " + id);
// 模拟数据库查询耗时
try {
Thread.sleep(500);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return PRODUCT_DB.get(id);
}
}方案五:JVM 层面 G1 垃圾收集器调优
原理: Java 8 默认使用 Parallel GC,它在高负载下可能产生较长的 Full GC 停顿。G1(Garbage-First)收集器是一款面向服务端的、可预测停顿时间的垃圾收集器,超级适合大内存(>4G)的服务。通过调整其参数,可以在吞吐量和低延迟之间取得更好的平衡。
优化策略与最佳实践: 在应用的启动脚本(如 startup.sh)中设置 JVM 参数:
#!/bin/bash
JAVA_OPTS="-Xms4g -Xmx4g" # 设置堆内存大小
JAVA_OPTS="${JAVA_OPTS} -XX:+UseG1GC" # 使用 G1 收集器
JAVA_OPTS="${JAVA_OPTS} -XX:MaxGCPauseMillis=200" # 设置期望的最大GC停顿时间(毫秒)
JAVA_OPTS="${JAVA_OPTS} -XX:InitiatingHeapOccupancyPercent=45" # 当堆空间使用率达到45%时启动并发标记周期
JAVA_OPTS="${JAVA_OPTS} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log" # 打印GC日志用于分析
java $JAVA_OPTS -jar your-application.jar注意: GC 调优是一个复杂且依赖具体场景的过程。以上参数是一个常见的起点,最佳实践是通过监控工具(如 GCViewer、JConsole)分析 GC 日志,根据实际的停顿时间和频率进行微调。
实践案例
让我们将上述技巧整合到一个简单的 Spring Boot 项目中进行演示。
1. 完整项目结构描述
performance-optimization-demo
├── pom.xml
└── src
└── main
├── java
│ └── 包名称,请自行替换
│ ├── PerformanceOptimizationDemoApplication.java
│ ├── config
│ │ ├── AsyncConfig.java
│ │ └── CacheConfig.java
│ ├── controller
│ │ └── ProductController.java
│ ├── model
│ │ └── Product.java
│ └── service
│ ├── NotificationService.java
│ └── ProductService.java
└── resources
└── application.properties图5:项目目录结构树形图 此结构展示了标准 Maven 项目的布局,包含了配置、控制器、模型和服务层,清晰地组织了我们的示例代码。
2. 依赖管理详解
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.8</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>包名称,请自行替换</groupId>
<artifactId>performance-optimization-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>performance-optimization-demo</name>
<description>Demo project for Spring Boot Performance Optimization</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3. 完整代码实现示例
•Product.java (Model)
// 包名称,请自行替换.model
package 包名称,请自行替换.model;
import java.io.Serializable;
import java.math.BigDecimal;
public class Product implements Serializable {
private Long id;
private String name;
private BigDecimal price;
// 构造器、getter、setter 省略,请自行补充
// ...
}•ProductController.java
// 包名称,请自行替换.controller
package 包名称,请自行替换.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import 包名称,请自行替换.model.Product;
import 包名称,请自行替换.service.NotificationService;
import 包名称,请自行替换.service.ProductService;
import java.util.concurrent.CompletableFuture;
@RestController
@RequestMapping("/products")
public class ProductController {
@Autowired
private ProductService productService;
@Autowired
private NotificationService notificationService;
@GetMapping("/{id}")
public Product getProduct(@PathVariable Long id) {
// 调用带缓存的服务
return productService.findProductById(id);
}
@GetMapping("/{id}/notify")
public String notifyUser(@PathVariable Long id) {
Product product = productService.findProductById(id);
// 异步发送通知,不阻塞当前请求
notificationService.sendEmail("邮箱,如有需要自行替换", "您关注的商品 " + product.getName() + " 有新动态!");
return "通知已发送!";
}
}•application.properties
server.port=8080
# 优化方案一:启用全局延迟初始化
spring.main.lazy-initialization=true
# 优化方案二:HikariCP 调优(本示例未连接真实数据库,但配置可供参考)
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.connection-timeout=30000
spring.datasource.hikari.idle-timeout=600000
spring.datasource.hikari.max-lifetime=18000004. 步骤式运行指南
1.环境准备:
•安装 JDK 1.8+ 并配置 JAVA_HOME。
•安装 Apache Maven 3.6+。
•一个 IDE(如 IntelliJ IDEA 或 VS Code)。
2.项目创建与代码填充:
•使用 Spring Initializr 创建一个 Maven 项目,选择 Spring Boot 2.7.8 和 “Spring Web” 依赖。•按照上述项目结构和代码,创建文件并填充内容。
3.编译与运行:
•在项目根目录打开命令行。
•执行 mvn clean install 编译项目。
•执行 mvn spring-boot:run 启动应用。
•观察控制台输出,看到 “Started PerformanceOptimizationDemoApplication” 字样表明启动成功。
4.测试与效果分析:
•测试缓存:
•使用 curl 或浏览器访问 http://localhost:8080/products/1。
•第一次访问,控制台会打印 “从数据库查询商品,ID: 1″,响应时间较长。
•再次访问 http://localhost:8080/products/1,控制台不再打印查询语句,响应时间显著缩短,说明缓存生效。
•测试异步:
•访问 http://localhost:8080/products/1/notify。
•浏览器会立即收到 “通知已发送!” 的响应。
•同时,观察控制台,会看到 “开始发送邮件…” 的日志在几秒后才出现,证明邮件发送任务是异步执行的。
进阶优化
掌握了基础技巧后,我们还可以从更宏观的视角进行思考和优化。
1. 扩展思路与优化方向
•组合拳: 将多种技巧结合使用。例如,在一个异步任务中,访问一个被缓存的数据源,实现“异步+缓存”的双重优化。
•代码层面: 优化算法复杂度、使用更高效的数据结构(如 HashMap vs ArrayList 的查找)、避免在循环中进行数据库操作。
•架构层面: 引入消息队列(如 RabbitMQ, Kafka)对系统进行解耦和削峰填谷,这是异步处理的终极形态。
2. 潜在问题及解决策略
•缓存穿透/击穿/雪崩: 这是缓存使用中的经典问题。可以通过布隆过滤器防止穿透、设置互斥锁防止击穿、为缓存添加随机过期时间防止雪崩。
•异步异常处理: @Async 方法的异常无法被主线程捕获。需要配置自定义的 AsyncUncaughtExceptionHandler 来统一处理异步任务中的异常。
•延迟初始化的陷阱: 某些 @PostConstruct 初始化逻辑可能依赖其他 Bean,延迟初始化可能导致依赖注入失败。需要对这类 Bean 排除延迟初始化。
3. 适用场景与局限性分析
我们可以用一个象限图来评估这五个技巧的适用性:
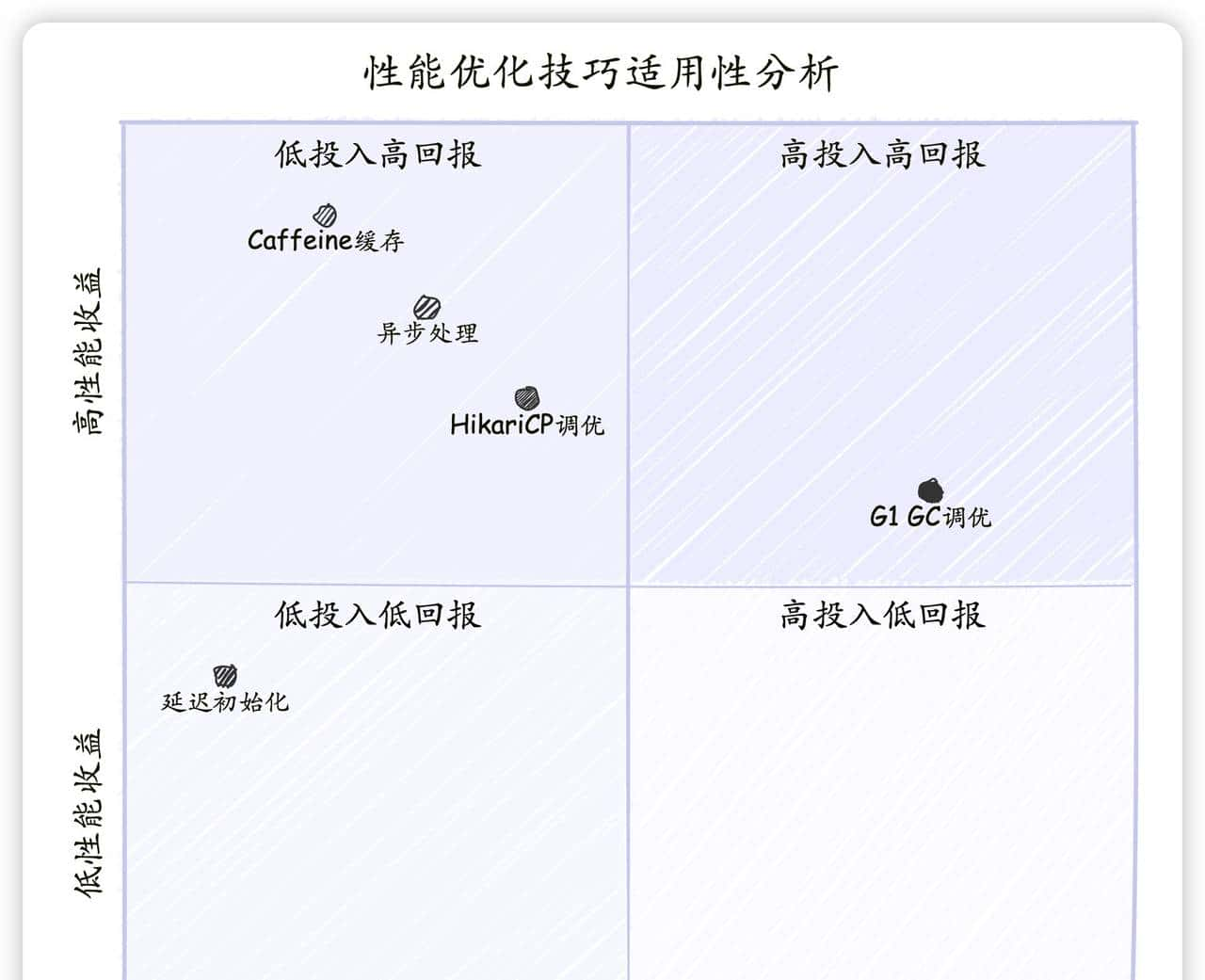
图7:性能优化技巧投入产出比象限图 此图将五个技巧按照实施难度和性能收益进行了分类。Caffeine缓存和异步处理属于“低投入高回报”的优先选项,应第一思考。G1 GC调优难度较高,但收益也相对可观。
总结与展望
1. 核心要点回顾
本文围绕 Spring Boot 2.7.8 和 Java 1.8 这套经典技术栈,提出了五个立竿见影的性能优化技巧:
•延迟初始化:加速启动,适合微服务。
•HikariCP 调优:疏通数据库瓶颈,提升吞吐。
•异步处理:释放线程,应对高并发 I/O 场景。
•Caffeine 缓存:减少重复计算,降低数据库压力。
•G1 GC 调优:优化 JVM,减少停顿,提升稳定性。
这些技巧并非孤立存在,而是相辅相成。在实际应用中,应根据业务场景和性能瓶颈的精准定位,灵活选择并组合使用。
2. 技术趋势展望
虽然我们聚焦于经典技术栈,但技术的演进从未停止。Java 的后续版本(LTS 版本如 11, 17, 21)带来了 ZGC、Shenandoah 等更先进的垃圾收集器,以及更丰富的语言特性。Spring Boot 3.x 则基于 Jakarta EE 和更高版本的 Java,提供了更优的启动性能和原生镜像支持。不过,本文所探讨的优化思想——如资源池化、异步解耦、空间换时间(缓存)、JVM 调优——是跨越具体技术版本的通用原则,无论技术栈如何变迁,其核心价值依然存在。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...