1 索引
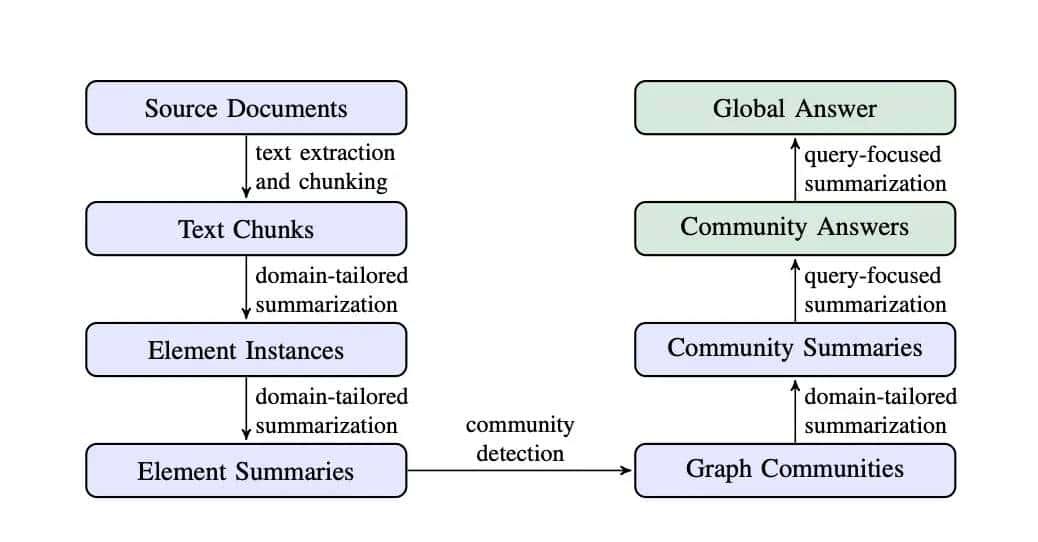
GraphRAG的索引过程可以分为以下几个关键步骤:
-
从源文档到文本块:
- 将源文档的文本分割成较小的文本块,以便后续处理。文本块的大小会影响实体提取的召回率,较小的块一般能提取更多的实体。但是,如果块太小也会带来一些新的问题,例如:较小的文本块可能无法提供足够的上下文信息,导致LLM难以准确理解实体之间的关系;较小的文本块也需要更多的LLM调用,这可能会导致整体处理效率下降。
-
从文本块到元素实例:
- 使用LLM(大语言模型)从每个文本块中提取实体和关系。实体包括名称、类型和描述,关系则描述实体之间的关联。(元素是指实体、关系以及Claim)
- 通过多轮提取,确保尽可能多的实体和关系被提取出来。
- 提取Claim(可选): 在提取实体和关系之后,可以使用另一个LLM提示(prompt)来提取与实体相关的Claim。Claim是与实体相关的陈述或主张,一般描述了某个实体在文本中的特定行为、观点、事件或属性。
-
从元素实例到元素摘要:
- 对提取的实体和关系进行摘要,生成每个元素的描述性文本块。这些摘要协助理解实体的含义和它们之间的关系。
- 例如:
- 实体摘要:“微软”——“全球领先的科技公司,专注于软件开发、云计算和人工智能”
- 关系摘要:“微软“与”人工智能”的关系——“微软在AI领域进行了大量投资,并推出了多个AI驱动的产品和服务”。
- Claim摘要:“Satya Nadella强调了AI的重大性”——“微软CEO Satya Nadella在最近的采访中强调了AI对未来科技发展的重大性”。
-
从元素摘要到Commutity:
- 将元素摘要构建成一个同质无向加权图,其中节点代表实体,边代表实体之间的关系,边的权重表明关系的强度(边的权重是基于从文本中提取的关系实例的频率或重大性来计算的)。
- 使用社区检测算法(如Leiden算法)将图划分为多个紧密连接的社区(dense group),每个社区包含一组高度相关的实体。
-
从图社区到社区摘要:
- 为每个社区生成摘要,描述该社区中的主要实体、关系和主题。这些摘要在回答全局查询时超级有用。
- 对于叶级社区(最底层的社区),直接使用元素摘要生成摘要;对于更高级别的社区,使用子社区的摘要来替代部分元素摘要。
2 查询
GraphRAG的查询过程包括全局查询和局部查询(Local Query)两种。
2.1 全局查询
GraphRAG的全局查询过程是一个多阶段的过程,旨在通过利用预先构建的图索引和社区摘要来回答用户的查询。以下是整个过程的详细步骤:
-
- 查询解析与实体识别
- 针对一个查询,系统会对该查询进行解析,识别出其中的关键实体和主题。之后使用嵌入模型(embedding model)将查询转换为向量表明,以便与社区摘要进行语义匹配。
-
语义匹配与社区摘要选择
- 计算查询向量与社区摘要向量之间的类似度,找到与查询最相关的社区摘要。
- 根据查询的复杂性和所需的详细程度,选择合适层次的社区摘要(如C0、C1、C2、C3)。
- 对于全局查询,一般选择较高层次的社区摘要(如C0或C1),由于它们涵盖了较广泛的主题。
-
随机打乱与分块:
- 将社区摘要随机打乱并分成预定义大小的块,以确保相关信息均匀分布在多个块中,而不是聚焦在单个上下文窗口中。 这种分块方式有助于避免信息丢失,并提高回答的多样性。
- 例如:
- 假设有以下社区摘要:
- 社区A:人工智能(AI)在科技行业中的重大性。
- 社区B:云计算市场的竞争格局。
- 社区C:隐私政策对科技公司的影响。
- 随机打乱后,社区摘要可能被重新组合为:
- 块1:人工智能的重大性 + 隐私政策的影响。
- 块2:云计算市场的竞争 + 人工智能的重大性。
- 块3:隐私政策的影响 + 云计算市场的竞争。
- 假设有以下社区摘要:
-
生成中间答案(Map阶段)
- 对于每个社区摘要块,使用LLM生成一个中间答案(partial answer)。
- LLM还会为每个生成的中间答案分配一个协助分数(helpfulness score),范围从0到100,表明该答案对回答查询的有用程度。
- 协助分数为0的答案会被过滤掉,不参与后续的汇总。
-
汇总全局答案(Reduce阶段):
- 将中间答案按协助分数从高到低排序。
- 将这些中间答案逐步添加到一个新的上下文窗口中,直到达到token的最大限制。
- 使用最终的上下文窗口生成一个全局答案,返回给用户。
2.2 局部查询
-
查询解析与实体识别:
- 对查询进行解析,识别出关键实体和主题。之后,使用嵌入模型(embedding model)将查询转换为向量表明。
-
语义匹配与实体检索
- 计算查询向量与图索引中实体和关系的向量之间的类似度,找到与查询最相关的实体。此步骤侧重于语义匹配(向量类似度比较)
-
图遍历与信息提取
- 从图索引中与查询相关的实体节点出发,遍历与之相连的关系边和Claim,提取详细信息。此步骤侧重于图遍历(图结构分析)
-
获取低层次社区摘要(可选)
- 如果查询需要更详细的子主题信息,GraphRAG会从低层次社区摘要中提取相关信息。例如,如果查询涉及“微软在人工智能领域的投资”,GraphRAG可能会获取与“微软”和“人工智能”相关的低层次社区摘要,描述具体的投资项目和合作伙伴。
-
生成详细答案:
- 使用LLM生成一个详细答案,描述与查询相关的具体信息。例如,对于查询“微软在人工智能领域的投资有哪些?”,生成的详细答案可能是:“微软在人工智能领域进行了大量投资,包括开发AI驱动的产品(如Azure AI)、与研究机构的合作(如OpenAI)以及对初创公司的收购(如Nuance Communications)。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...