
1. Pandas概述
1.1 Pandas简介
Pandas 是 Python 语言的一个扩展程序库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas是 Python 的核心数据分析支持库,可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据,可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工。Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
1.2 Pandas 的特点和用途
DataFrame和Series:DataFrame是二维表格数据结构,类似于电子表格或SQL表,它由行和列组成,每列可以包含不同数据类型。Series是一维标签化数组,用于存储单列数据。数据清理和预处理:Pandas提供了一系列功能,用于处理丢失数据(缺失值)、重复数据、异常值、数据类型转换等,以使数据变得更加干净和可用于分析。数据选择和过滤:Pandas允许使用标签和位置进行数据选择和过滤,包括布尔索引、条件过滤、列选择等。数据分组和聚合:Pandas支持数据分组操作,可以对数据进行分组并执行聚合操作,如求和、均值、计数等。合并和连接:Pandas提供了多种方法来合并和连接不同的数据集,包括数据库风格的连接、拼接和合并操作。时间序列处理:Pandas内置了强大的时间序列功能,支持时间索引和时间相关的操作,适用于处理时间序列数据。数据可视化:Pandas可以与Matplotlib等数据可视化库集成,帮助用户快速绘制图表和图形,以更好地理解数据。读取和存储数据:Pandas支持多种数据格式,包括CSV、Excel、SQL数据库、JSON等,可以方便地读取和存储数据。高性能计算:Pandas基于NumPy构建,因此具有高性能的数据处理能力,尤其在处理大规模数据集时非常有效。广泛应用领域:Pandas广泛应用于数据分析、数据科学、机器学习、金融建模、时间序列分析、数据清理和数据预处理等领域。
1.3 Pandas的总体内容
2. Pandas数据结构
Pandas提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列。
| 数据结构 | 维度 | 说明 |
| Series | 1 | 该结构能够存储各种数据类型,比如字符数、整数、浮点数、Python 对象等,Series 用 name 和 index 属性来描述 数据值。Series 是一维数据结构,因此其维数不可以改变。 |
| DataFrame | 2 | DataFrame 是一种二维表格型数据的结构,既有行索引,也有列索引。行索引是 index,列索引是 columns。 在创建该结构时,可以指定相应的索引值。 |
gn
2.1 pandas Series
2.1.1 pandas Series结构
Series 结构,也称 Series 序列,是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。Series 的结构图,如下所示:

通过标签我们可以更加直观地查看数据所在的索引位置。
2.1.2 创建Series对象语法及说明
Series 创建方法的完整语法及参数说明如下:
pandas.Series(
data=None, # 指定数据源
index=None, # 指定Series索引标签,如果没有传递,默认为RangeIndex(0, 1, 2, ..., n-1)
dtype=None, # 显式指定 Series 的数据类型,如果没有提供,则会自动判断得出
name=None, # 为 Series 指定一个名称
copy=False, # 控制是否复制输入数据,默认为 False。
fastpath=False # 内部优化参数(通常不建议使用)
)参数详细说明:
1. data (数据源)
功能: 构成 Series 的数据内容
可接受的数据类型:
序列类型: list, tuple, array, Series 等字典类型: dict, defaultdict 等标量值: int, float, str, bool 等None: 创建空 Series
示例:
import pandas as pd
import numpy as np
# 从列表创建
s1 = pd.Series([1, 2, 3, 4, 5])
# 从字典创建(键自动成为索引)
s2 = pd.Series({'a': 1, 'b': 2, 'c': 3})
# 从NumPy数组创建
s3 = pd.Series(np.array([1.0, 2.0, 3.0]))
# 从标量创建(需要指定index),下面的代码中,每个index对应同一个值,就是5
s4 = pd.Series(5, index=[0, 1, 2, 3])
# 创建空Series
s5 = pd.Series()2. index (索引)
功能: 指定 Series 的索引标签
参数要求:
必须是可哈希的、长度与 data 匹配的序列如果未提供,默认使用 RangeIndex(0, 1, 2, …, n-1)索引标签不必唯一,但建议保持唯一性以避免意外行为
示例:
import pandas as pd
# 自定义字符串索引
s = pd.Series([10, 20, 30], index=['x', 'y', 'z'])
# 自定义数字索引
s = pd.Series([10, 20, 30], index=[100, 200, 300])
# 与字典结合使用时,index可以重新排序或选择子集
data_dict = {'a': 1, 'b': 2, 'c': 3}
s = pd.Series(data_dict, index=['c', 'a']) # 只包含'c','a',按指定顺序
# print(s)结果为:
# c 3
# a 13. dtype (数据类型)
功能: 显式指定 Series 的数据类型
常用数据类型:
'int64', 'int32': 整数类型'float64', 'float32': 浮点数类型'object': 对象/字符串类型'bool': 布尔类型'datetime64[ns]': 日期时间类型None: 由 Pandas 自动推断
示例:
import pandas as pd
# 强制指定数据类型
s1 = pd.Series([1, 2, 3], dtype='float64') # 整数转为浮点数
s2 = pd.Series([1.1, 2.2, 3.3], dtype='int64') # 浮点数转为整数(截断)
s3 = pd.Series([1, 2, 3], dtype='object') # 转为Python对象
# 自动推断数据类型
s4 = pd.Series([1, 2, 3]) # 推断为int644. name (名称)
功能: 为 Series 指定一个名称
用途:
在将 Series 转换为 DataFrame 时作为列名在绘图时作为标签提高代码可读性
示例:
import pandas as pd
# 为Series命名
s = pd.Series([1, 2, 3], name='temperature')
print(s.name) # 输出: 'temperature'
# 将命名后的Series转换为DataFrame
df = s.to_frame()
print(df.columns) # 输出: Index(['temperature'], dtype='object')5. copy (复制)
功能: 控制是否复制输入数据
参数值:
False (默认): 尽可能不复制数据(视图)True: 总是复制数据
注意事项:
对于某些数据类型(如字典),总是会创建副本对于数组/列表,设置为 False 可能创建视图,修改原数据会影响 Series
示例:
import pandas as pd
import numpy as np
arr = np.array([1, 2, 3])
s1 = pd.Series(arr, copy=False) # 可能创建视图
s2 = pd.Series(arr, copy=True) # 总是创建副本
arr[0] = 999
print(s1[0]) # 可能输出 999(如果创建了视图)
print(s2[0]) # 总是输出 1(独立副本)2.1.3 创建Series对象综合应用示例
ndarray(数组)创建Series对象
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
#使用默认索引,创建 Series 序列对象
s1 = pd.Series(data)
print(f'默认索引
{s1}')
'''
默认索引
0 a
1 b
2 c
3 d
dtype: object
'''
#使用“显式索引”的方法自定义索引标签
s2 = pd.Series(data,index=[100,101,102,103])
print(f'自定义索引
{s2}')
'''
自定义索引
100 a
101 b
102 c
103 d
dtype: object
'''dict创建Series对象
import pandas as pd
import numpy as np
data = {'a' : 0, 'b' : 1, 'c' : 2}
#没有传递索引时 会按照字典的键来构造索引
s1_dict = pd.Series(data)
print(f'没有传递索引
{s1_dict}')
'''
没有传递索引
a 0
b 1
c 2
dtype: int64
'''
#字典类型传递索引时 索引时需要将索引标签与字典中的值一一对应 当传递的索引值无法找到与其对应的值时,使用 NaN(非数字)填充
s2_dict = pd.Series(data, index=['a','b','c','d'])
print(f'传递索引
{s2_dict}')
'''
传递索引
a 0
b 1
c 2
d NaN
dtype: int64
'''标量创建Series对象
#如果 data 是标量值,则必须提供索引: 标量值按照 index 的数量进行重复,并与其一一对应
s3 = pd.Series(6,index=[0,1,2,3])
print(f'标量值,则必须提供索引
{s3}')
'''
标量值,则必须提供索引
0 6
1 6
2 6
3 6
dtype: int64
'''特殊创建场景
创建带有时间索引的 Series
import pandas as pd
# 使用日期范围作为索引
dates = pd.date_range('20230101', periods=6)
time_series = pd.Series([1, 2, 3, 4, 5, 6], index=dates)
print(time_series)
"""
结果为:
2023-01-01 1
2023-01-02 2
2023-01-03 3
2023-01-04 4
2023-01-05 5
2023-01-06 6
Freq: D, dtype: int64
"""2.1.4 访问Series数据
分为两种访问方式,一种是位置索引访问;另一种是索引标签访问。
(1)位置索引访问
这种访问方式与 ndarray 和 list 相同,使用元素自身的下标进行访问。我们知道数组的索引计数从 0 开始,这表示第一个元素存储在第 0 个索引位置上,以此类推,就可以获得 Series 序列中的每个元素。示例:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[0]) #位置下标
print(s['a']) #标签下标
"""
输出结果:
1
1
"""通过切片的方式访问 Series 序列中的数据,示例如下:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[:3])
"""
输出结果:
a 1
b 2
c 3
dtype: int64
"""如果想要获取最后三个元素,也可以使用下面的方式:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])
"""
输出结果:
c 3
d 4
e 5
dtype: int64
"""(2) 索引标签访问
Series 类似于固定大小的 dict,把 index 中的索引标签当做 key,而把 Series 序列中的元素值当做 value,然后通过 index 索引标签来访问或者修改元素值。示例:
import pandas as pd
# 示例1,使用索标签访问单个元素值:
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s['a'])
"""
结果为:
6
"""
# 示例 2,使用索引标签访问多个元素值
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s[['a','c','d']])
"""
输出结果:
a 6
c 8
d 9
dtype: int64
"""
# 示例3,如果使用了 index 中不包含的标签,则会触发异常:
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
#不包含f值
print(s['f'])
"""
输出结果:
......
KeyError: 'f'
"""2.1.5 Series常用属性和方法
Series 对象的常用属性示例见下表,示例前统一的代码为:
import pandas as pd
import numpy as np| 名称 | 属性 | 示例 |
|---|---|---|
| axes | 以列表的形式返回所有行索引标签。 |
s = pd.Series(np.random.randn(5)) print (f”The axes are:{s.axes}”) 结果为: The axes are:[RangeIndex(start=0, stop=5, step=1)] |
| dtype | 返回对象的数据类型。 |
s = pd.Series(np.random.randn(5)) 结果为: The dtype is:float64 |
| empty | 返回一个空的 Series 对象。 |
s = pd.Series(np.random.randn(5)) 结果为: 是否为空对象?False |
| ndim | 返回输入数据的维数。 |
s = pd.Series(np.random.randn(5)) 结果为: 0 0.311485 |
| size | 返回输入数据的元素数量。 |
s = pd.Series(np.random.randn(3)) 结果为: 0 -1.866261 |
| values | 以 ndarray 的形式返回 Series 对象。 |
s = pd.Series(np.random.randn(6)) 结果为: 0 -0.502100 |
| index | 返回一个RangeIndex对象,用来描述索引的取值范围。 |
#显示索引 结果为: 显式索引: |
Series常用方法及示例见下表,示例前的统一说明代码如下:
import pandas as pd
import numpy as np| 方法 | 功能 | 示例 |
| head() |
查看数据 head() 返回前 n 行数据,默认显示前 5 行数据。 |
s = pd.Series(np.random.randn(5)) 结果为: 0 1.249679 0 1.249679 |
| tail() |
查看数据 tail()返回最后 n 行数据,默认显示最后 5 行数据。 |
s = pd.Series(np.random.randn(4)) 结果为: 原Series输出: |
| isnull() |
检测缺失值(值不存在、丢失、缺少)。 isnull():如果为值不存在或者缺失,则返回 True。 |
import pandas as pd 结果为: 0 False |
| notnull() |
检测缺失值(值不存在、丢失、缺少)。 notnull():如果值不存在或者缺失,则返回 False。 |
import pandas as pd 结果为: 0 True |
2.2 pandas DataFrame
2.2.1 pandas DataFrame结构
构造DataFrame最常用的方式是字典+列表,语句很简单,先是字典外括,然后依次打出每一列标题及其对应的列值(此处一定要用列表),这里列的顺序并不重要:
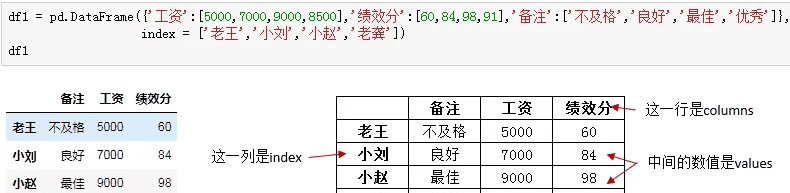
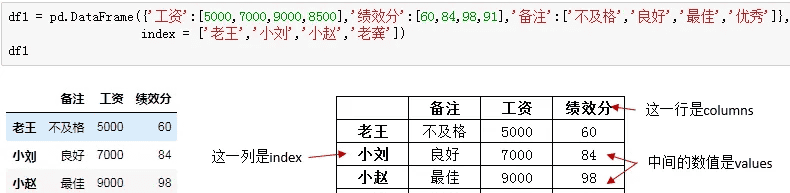
左边是Pycharm中dataframe的样子,如果对应到excel中,他就是右边表格的样子,通过改变columns,index和values的值来控制数据。
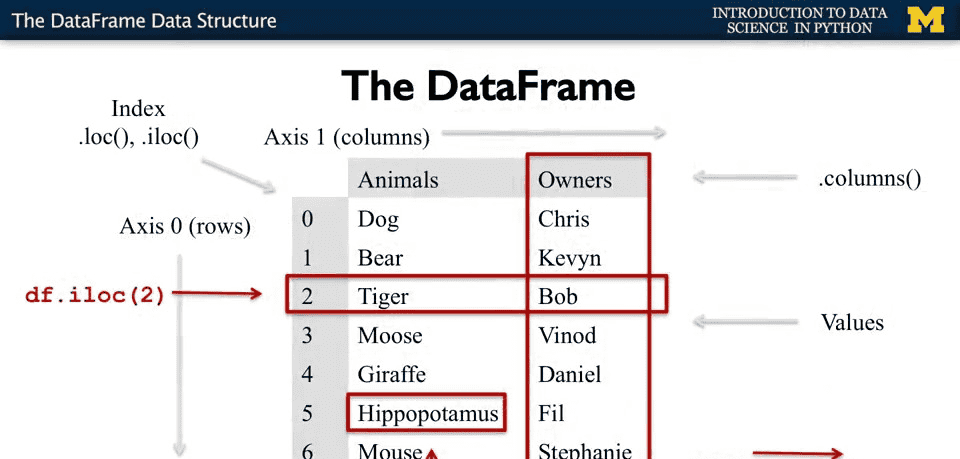
PS:如果我们在创建时不指定index,系统会自动生成从0开始的索引。
2.2.2 创建DataFrame对象语法及说明
完整语法:
pandas.DataFrame(
data=None, # 数据源
index=None, # 指定 DataFrame 的行索引标签
columns=None, # 指定 DataFrame 的列名/列索引
dtype=None, # 强制指定 DataFrame 中各列的数据类型
copy=None # 控制是否复制输入数据
)参数详细说明:
1. data (数据源)
功能: 构成 DataFrame 的数据内容
可接受的数据类型:
(1)字典类型:
{列名: 列数据},列数据可以是 list, Series, array 等{列名: 标量值},会自动广播到所有行
(2)二维结构:
list of lists (每个子列表代表一行)list of dicts (每个字典代表一行)NumPy 二维数组另一个 DataFrame
(3)Series: 创建单列 DataFrame
示例:
import pandas as pd
import numpy as np
# 从字典创建(最常用)
data_dict = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['Beijing', 'Shanghai', 'Guangzhou']
}
df1 = pd.DataFrame(data_dict)
# 从列表的列表创建(每行一个列表)
data_list = [
['Alice', 25, 'Beijing'],
['Bob', 30, 'Shanghai'],
['Charlie', 35, 'Guangzhou']
]
df2 = pd.DataFrame(data_list, columns=['Name', 'Age', 'City'])
# 从字典列表创建(每行一个字典)
data_dict_list = [
{'Name': 'Alice', 'Age': 25, 'City': 'Beijing'},
{'Name': 'Bob', 'Age': 30, 'City': 'Shanghai'},
{'Name': 'Charlie', 'Age': 35, 'City': 'Guangzhou'}
]
df3 = pd.DataFrame(data_dict_list)
# 从NumPy数组创建
data_array = np.array([
['Alice', 25, 'Beijing'],
['Bob', 30, 'Shanghai'],
['Charlie', 35, 'Guangzhou']
])
df4 = pd.DataFrame(data_array, columns=['Name', 'Age', 'City'])2. index (行索引)
功能: 指定 DataFrame 的行索引标签
参数要求:
类似数组的可迭代对象,长度必须与数据行数匹配如果未提供,默认使用 RangeIndex(0, 1, 2, …, n-1)
示例:
# 自定义行索引
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
custom_index = ['emp001', 'emp002', 'emp003']
df = pd.DataFrame(data, index=custom_index)
# 使用日期作为索引
dates = pd.date_range('20230101', periods=3)
df_time = pd.DataFrame(data, index=dates)3. columns (列索引)
功能: 指定 DataFrame 的列名/列索引
参数要求:
类似数组的可迭代对象,长度必须与数据列数匹配如果未提供,对于字典数据会使用字典键,其他情况使用 RangeIndex(0, 1, 2, …, n-1)
示例:
# 自定义列名
data_list = [
['Alice', 25, 'Beijing'],
['Bob', 30, 'Shanghai'],
['Charlie', 35, 'Guangzhou']
]
custom_columns = ['姓名', '年龄', '城市']
df = pd.DataFrame(data_list, columns=custom_columns)
# 重新排列列顺序(使用字典数据时)
data_dict = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['Beijing', 'Shanghai', 'Guangzhou']
}
# 改变列顺序
df_reordered = pd.DataFrame(data_dict, columns=['City', 'Name', 'Age'])
# 选择部分列
df_subset = pd.DataFrame(data_dict, columns=['Name', 'Age'])4. dtype (数据类型)
功能: 强制指定 DataFrame 中各列的数据类型
参数值:
单个数据类型:强制所有列使用同一类型字典:{列名: 数据类型},为不同列指定不同数据类型None:由 Pandas 自动推断
示例:
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Score': [85.5, 92.0, 78.5]
}
# 强制所有列为字符串类型
df_str = pd.DataFrame(data, dtype=str)
# 为不同列指定不同数据类型
dtype_dict = {
'Name': 'object',
'Age': 'int32',
'Score': 'float64'
}
df_mixed = pd.DataFrame(data, dtype=dtype_dict)5. copy (复制)
功能: 控制是否复制输入数据
参数值:
False (默认): 尽可能不复制数据(视图)True: 总是复制数据
示例:
import numpy as np
# 原始数据
original_data = np.array([
['Alice', 25, 'Beijing'],
['Bob', 30, 'Shanghai']
])
# 创建DataFrame时不复制数据
df_no_copy = pd.DataFrame(original_data, columns=['Name', 'Age', 'City'], copy=False)
# 创建DataFrame时复制数据
df_with_copy = pd.DataFrame(original_data, columns=['Name', 'Age', 'City'], copy=True)
# 修改原始数组会影响 df_no_copy,但不会影响 df_with_copy
original_data[0, 1] = '999'2.2.3 创建DataFrame对象综合应用示例
import pandas as pd
import numpy as np
# 综合示例:展示所有参数的使用
data = {
'EmployeeID': [101, 102, 103, 104],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Department': ['HR', 'Engineering', 'Marketing', 'Finance'],
'Salary': [50000, 75000, 60000, 80000],
'JoinDate': pd.date_range('20220101', periods=4)
}
# 使用所有参数创建DataFrame
df_comprehensive = pd.DataFrame(
data=data,
index=['EMP001', 'EMP002', 'EMP003', 'EMP004'], # 自定义行索引
columns=['EmployeeID', 'Name', 'Department', 'Salary', 'JoinDate'], # 指定列顺序
dtype={
'EmployeeID': 'int32',
'Name': 'object',
'Department': 'object',
'Salary': 'float64',
'JoinDate': 'datetime64[ns]'
},
copy=True
)特殊创建场景
1. 创建空 DataFrame
import pandas as pd
# 完全空的DataFrame
empty_df1 = pd.DataFrame()
# 指定列名的空DataFrame
empty_df2 = pd.DataFrame(columns=['Name', 'Age', 'City'])
# 指定索引和列名的空DataFrame
empty_df3 = pd.DataFrame(index=['row1', 'row2'], columns=['col1', 'col2'])2. 从 Series 创建 DataFrame
import pandas as pd
# 单个Series创建单列DataFrame
s = pd.Series([1, 2, 3], name='values')
df_single = pd.DataFrame(s)
# 多个Series创建多列DataFrame
s1 = pd.Series([1, 2, 3], name='A')
s2 = pd.Series([4, 5, 6], name='B')
df_multi = pd.DataFrame({'Col1': s1, 'Col2': s2})3. 使用标量值自动广播
import pandas as pd
# 使用标量值,会自动广播到所有行/列
df_scalar = pd.DataFrame(
0, # 标量值
index=['row1', 'row2', 'row3'],
columns=['col1', 'col2', 'col3']
)4. 从结构化数组创建
import pandas as pd
import numpy as np
# 创建结构化数组
structured_array = np.array([
('Alice', 25, 85.5),
('Bob', 30, 92.0),
('Charlie', 35, 78.5)
], dtype=[('Name', 'U10'), ('Age', 'i4'), ('Score', 'f8')])
df_structured = pd.DataFrame(structured_array)2.2.4 列索引操作DataFrame
1. 列索引选取数据列
#列索引操作DataFrame
data = [['java',10,9],['python',20,100],['C++',30,50]]
df1 = pd.DataFrame(data,columns=['name','age','number'])
print(f'数据df1
{df1}')
'''
数据df1
name age number
0 java 10 9
1 python 20 100
2 C++ 30 50
'''
#获取数据方式一:使用列索引,实现数据获取某一行数据 df[列名]等于df.列名
print(f'通过df1.name方式获取
{df1.name}')
'''
通过df1.name方式获取
0 java
1 python
2 C++
Name: name, dtype: object
'''
print(f'通过df1["name"]方式获取
{df1["name"]}')
'''
通过df1["name"]方式获取
0 java
1 python
2 C++
Name: name, dtype: object
'''
#获取数据方式二:使用列索引,实现数据获取某多列数据 df[list]
print(f'通过df[list]方式获取多列数据
{df1[["name","number"]]}')
'''
通过df[list]方式获取多列数据
name number
0 java 9
1 python 100
2 C++ 50
'''
#获取数据方式三:使用布尔值筛选 通过设置某列数据条件,筛选符合条件的行
# 不同的条件用()包裹起来,与或非分别使用&,|,~而非and,or,not
print(f'获取name=python的数据
{df1[df1["name"]=="python"]}')
'''
获取name=python的数据
name age number
1 python 20 100
'''
print(f'获取age大于等于20的数据
{df1[df1["age"]>=20]}')
'''
获取age大于等于20的数据
name age number
1 python 20 100
2 C++ 30 50
'''
print(f'获取name=python的数据或者是age等于30
{df1[(df1["name"]=="python") | (df1["age"]==30)]}')
'''
获取name=python的数据或者是age等于30
name age number
1 python 20 100
2 C++ 30 50
'''2. 列索引添加数据列
#列索引添加数据列
data = {'one':[1,2,3],'two':[2,3,4]}
df1 = pd.DataFrame(data,index=['a','b','c'])
print(f'原数据
{df1}')
'''
原数据
one two
a 1 2
b 2 3
c 3 4
'''
#方式一:使用df['列']=值,插入新的数据列
df1['three'] = pd.Series([10,20,30],index=list('abc'))
print(f'使用df["列"]=值,插入新的数据
{df1}')
'''
使用df["列"]=值,插入新的数据
one two three
a 1 2 10
b 2 3 20
c 3 4 30
'''
#方式二:#将已经存在的数据列做相加运算
df1['four'] = df1['one']+df1['three']
print(f'将已经存在的数据列做相加运算
{df1}')
'''
将已经存在的数据列做相加运算
one two three four
a 1 2 10 11
b 2 3 20 22
c 3 4 30 33
'''
#方式三:使用 insert() 方法插入新的列
"""
insert()函数说明如下:
DataFrame.insert(loc, column, value, allow_duplicates=False)
Args:
loc: 整数,表示新列插入的位置。必须满足 0 <= loc <= len(columns)。
column: 字符串或可哈希对象,表示新列的标签。
value: 标量、Series 或 array-like 对象,表示新列的内容。
allow_duplicates: 布尔值,默认为 False,表示是否允许重复的列标签。
"""
#数值4代表插入到columns列表的索引位置
df1.insert(4,column='score',value=[50,60,70])
print(f'使用insert()方法插入
{df1}')
'''
使用insert()方法插入
one two three four score
a 1 2 10 11 50
b 2 3 20 22 60
c 3 4 30 33 70
'''3. 列索引删除数据列
data = {'one':[1,2,3],'two':[20,30,40],'three':[20,30,40]}
df1 = pd.DataFrame(data,index=['a','b','c'])
print(f'原数据
{df1}')
"""
原数据
one two three
a 1 20 20
b 2 30 30
c 3 40 40
"""
#方式一 del 删除某一列
del df1["one"]
print(f'通过del df["列名"]删除
{df1}')
"""
通过del df["列名"]删除
two three
a 20 20
b 30 30
c 40 40
"""
#方式er pop() 删除某一列
df1.pop("two")
print(f'通过pop("列名")删除
{df1}')
"""
通过pop("列名")删除
three
a 20
b 30
c 40
"""2.2.5 行索引操作DataFrame
没有函数或方法来专门操作行索引,操作行索引一般用loc或iloc方法,这两个方法不仅能操作行索引,还能操作列索引。
引言:在数据分析过程中,很多时候需要从数据表中提取出相应的数据,而这么做的前提是需要先“索引”出这一部分数据。虽然通过 Python 提供的索引操作符
"[]"
"."
1. 标签索引选取 loc[],loc作为属性访问
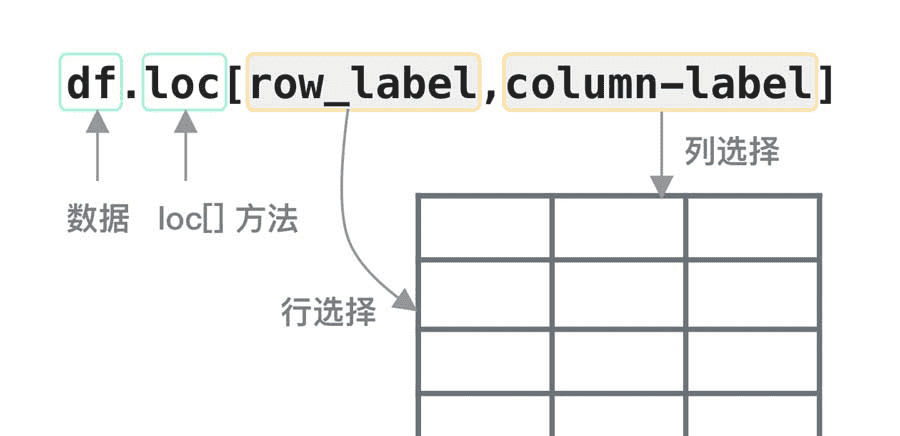
loc的形式为:
pandas.DataFrame.loc[row_lable, column_label]
注意:
1. loc 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引。对于loc,单个参数总是作用于行。要选择列,必须在第二个参数的位置上指定。
2. 在DataFrame上直接使用[](如df['School']或df[['School', 'Math']])通常用于选择列,而loc和iloc的单参数则用于选择行,这是初学者容易混淆的一个点。
data = {'one':[1,2,3,4],'two':[20,30,40,50],'three':[60,70,80,90]}
df1 = pd.DataFrame(data,index=['a','b','c','d'])
print(f'原数据
{df1}')
"""
#原数据
one two three
a 1 20 60
b 2 30 70
c 3 40 80
d 4 50 90
"""
#取某一行数据
print(f'取某一行数据
{df1.loc["a"]}')
"""
#取某一行数据
one 1
two 20
three 60
Name: a, dtype: int64
"""
#loc 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引
#去某一个单元格的数据
print(f"取某一个单元格的数据
{df1.loc['a','two']}")
"""
#取某一个单元格的数据
20
"""
#更改某一个单元格的数据
df1.loc['a','two']='abc'
print(f"更改后的数据
{df1}")
"""
#更改后的数据
one two three
a 1 abc 60
b 2 30 70
c 3 40 80
d 4 50 90
"""2. 整数索引选取 iloc[]
通过将数据行所在的索引位置传递给 iloc 函数,也可以实现数据行选取。
注意:iloc 允许接受两个参数分别是行和列,参数之间使用“逗号”隔开,但该函数只能接收整数索引。
data = {'one':[1,2,3,4],'two':[20,30,40,50],'three':[60,70,80,90]}
df1 = pd.DataFrame(data,index=['a','b','c','d'])
print(f'原数据
{df1}')
"""
原数据
one two three
a 1 20 60
b 2 30 70
c 3 40 80
d 4 50 90
"""
#取某一行的数据 索引是从0开始
print(f'取某一行的数据
{df1.iloc[0]}')
"""
取某一行的数据
one 1
two 20
three 60
Name: a, dtype: int64
"""3. 切片操作多行选取
loc 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引。
iloc 允许接受两个参数分别是行和列,参数之间使用“逗号”隔开,但该函数只能接收整数索引。
切片时,标签索引切片是前闭后闭,整数索引切片是前闭后开(顾头不顾腚)。
data = {'one':[1,2,3,4],'two':[20,30,40,50],'three':[60,70,80,90]}
df1 = pd.DataFrame(data,index=['a','b','c','d'])
print(f'原数据
{df1}')
"""
原数据
one two three
a 1 20 60
b 2 30 70
c 3 40 80
d 4 50 90
"""
#loc[] 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引
print(f"#loc[]方式获取第三行最后两列数据
{df1.loc['c','two':'three']}")
"""
#loc[]方式获取第三行最后两列数据
two 40
three 80
Name: c, dtype: int64
"""
#iloc[] 允许接受两个参数分别是行和列,参数之间使用“逗号”隔开,但该函数只能接收整数索引。
print(f"#iloc[]方式获取第三行最后两列数据
{df1.iloc[2,1:3]}")
"""
#iloc[]方式获取第三行最后两列数据
two 40
three 80
Name: c, dtype: int64
"""4. 添加数据行
使用 append() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数据行。
语法:
df.append(other, ignore_index=False, verify_integrity=False, sort=None)
参数说明:
other:要追加的数据,可以是dataframe,series,字典,列表ignore_index:两个表的index是否有实际含义,默认为False,若ignore_index=True,表根据列名对齐合并,生成新的indexverify_integrity:默认为False,若为True,创建具有重复项的索引时引发ValueErrorsort:默认为False,若为True如果’ self ‘和’ other '的列没有对齐,则对列进行排序。
注意:append方法用以在表尾中添加新的行,并返回追加后的数据对象,若追加的行中存在原数据没有的列,会新增一列,并用nan填充;若追加的行数据中缺少原数据某列,同样以nan填充。
import pandas as pd
data = {'one':[1,2,3,4],'two':[20,30,40,50],'three':[60,70,80,90]}
df1 = pd.DataFrame(data,index=['a','b','c','d'])
print(f'#原数据
{df1}')
"""
#原数据
one two three
a 1 20 60
b 2 30 70
c 3 40 80
d 4 50 90
"""
df2 = pd.DataFrame({'one':'Q','two':'W'},index=['e'])
#使用append()返回一个新的是DataFrame的对象
df = df1.append(df2)
print(f'#在行末追加新数据行
{df}')
"""
#在行末追加新数据行
one two three
a 1 20 60.0
b 2 30 70.0
c 3 40 80.0
d 4 50 90.0
e Q W NaN
"""
#再举一个例子
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
#在行末追加新数据行
df = df.append(df2)
print(df)
"""
结果:
a b
0 1 2
1 3 4
0 5 6
1 7 8
"""5. 删除数据行
可以用drop()或pop()函数,从 DataFrame 中删除数据。
drop() 既能删除行,又能删除列
pop(列名) 只能删除列,且只能是标签索引
pop()语法:
DataFrame.pop(item)
参数:
item:要移除并返回的列标签索引,它不能是整数索引。
说明:在堆栈中,pop不需要任何参数,它每次都会弹出最后一个元素。但是pandas的pop方法可以从数据框架中获取一个列的输入并直接弹出。
drop()函数 语法:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
参数:
labels:待删除的行名or列名; axis:删除时所参考的轴,0为行,1为列; index:待删除的行名 columns:待删除的列名 level:多级列表时使用,暂时不作说明 inplace:布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本 errors一般用不到,这里不作解释
pop()和drop()函数对比:
| 特性 | |
|
|---|---|---|
| 操作对象 | 主要针对列 (参数为列名) | 可删除行或列(通过 |
| 返回值 | 返回被移除的列(Series) | 默认返回操作后的新DataFrame(原数据不变),无返回值(当 |
| 原位修改 | 总是直接修改原DataFrame | 需通过 |
删除表中的某一行或者某一列更明智的方法是使用drop,它不改变原有的df中的数据,而是返回另一个dataframe来存放删除后的数据。
import pandas as pd
data = {'one':[1,2,3,4],'two':[20,30,40,50],'three':[60,70,80,90]}
df1 = pd.DataFrame(data,index=['a','b','c','d'])
print(f'原数据
{df1}')
"""
原数据
one two three
a 1 20 60
b 2 30 70
c 3 40 80
d 4 50 90
"""
#drop(行索引) 删除某一行
df = df1.drop('a')
print(f'drop(行索引) 删除某一行
{df}')
"""
drop(行索引) 删除某一行
one two three
b 2 30 70
c 3 40 80
d 4 50 90
"""
#pop(列名) 删除某一列
df1.pop("one")
print(f'#pop(列名) 删除某一列
{df1}')
"""
#pop(列名) 删除某一列
two three
a 20 60
b 30 70
c 40 80
d 50 90
"""2.2.6 DataFrame常用属性和方法
DataFrame 的属性和方法,与 Series 相差无几,如下所示:
| 名称 | 属性&方法描述 | 示例 |
| index | 返回行索引 | |
| coloumns | 返回列索引 | |
| values | 使用numpy数组表示Dataframe中的元素值 | |
| head() | 返回前 n 行数据。 | |
| tail() | 返回后 n 行数据。 | |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 | |
| dtypes | 返回每列数据的数据类型。 | |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True。 | |
| ndim | 轴的数量,也指数组的维数。 | |
| shape | DataFrame中的元素数量。 | |
| shift() | 将行或列移动指定的步幅长度 | |
| T | 行和列转置。 | 示例见下面代码 |
| replace() | 将DataFrame中的值进行替换 | 示例见下面代码 |
| info() | 返回相关的信息:行数 列数,列索引 列非空值个数, 列类型 |
转置示例代码:
import pandas as pd
data = {
'name:': pd.Series(['c语言中文网','编程帮',"百度",'360搜索','谷歌','微学苑','Bing搜索']),
'year': pd.Series([5,6,15,28,3,19,23]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])}
df = pd.DataFrame(data)
print(f'#原数据
{df}')
"""
#原数据
name: year Rating
0 c语言中文网 5 4.23
1 编程帮 6 3.24
2 百度 15 3.98
3 360搜索 28 2.56
4 谷歌 3 3.20
5 微学苑 19 4.60
6 Bing搜索 23 3.80
"""
# T(Transpose)转置 把行和列进行交换
print(f'#df.T把行和列进行交换
{df.T}')
"""
#df.T把行和列进行交换
0 1 2 3 4 5 6
name: c语言中文网 编程帮 百度 360搜索 谷歌 微学苑 Bing搜索
year 5 6 15 28 3 19 23
Rating 4.23 3.24 3.98 2.56 3.2 4.6 3.8
"""replace()示例代码如下:
import pandas as pd
df = pd.DataFrame({'one':[10,20,30,40,50,10], 'two':[99,0,30,40,50,60]})
print(f'#原始数据
{df}')
"""
#原始数据
one two
0 10 99
1 20 0
2 30 30
3 40 40
4 50 50
5 10 60
"""
df = df.replace({10:100,30:333,99:9})
print(f'#replace替换后的数据
{df}')
"""
#replace替换后的数据
one two
0 100 9
1 20 0
2 333 333
3 40 40
4 50 50
5 100 60
"""3. pandas数据分析
3.1 pandas描述性统计
描述统计学(descriptive statistics)是一门统计学领域的学科,Pandas 库正是对描述统计学知识完美应用的体现,可以说如果没有“描述统计学”作为理论基奠,那么 Pandas 是否存在犹未可知。下列表格对 Pandas 常用的统计学函数做了简单的总结:
示例代码前面统一的条件为:
import pandas as pd
data = {
'name:': pd.Series(['c语言中文网','编程帮',"百度",'360搜索','谷歌','微学苑','Bing搜索']),
'year': pd.Series([5,6,15,28,3,19,23]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])}
df = pd.DataFrame(data)
print(f'#原数据
{df}')
"""
#原数据
name: year Rating
0 c语言中文网 5 4.23
1 编程帮 6 3.24
2 百度 15 3.98
3 360搜索 28 2.56
4 谷歌 3 3.20
5 微学苑 19 4.60
6 Bing搜索 23 3.80
"""| 函数名称 | 描述说明 | 示例 |
| describe() | 计算基本统计信息,如均值、标准差、最小值、最大值等,,可以计算dataframe和series结构的数据。 |
df.describe() df[“name:”].describe() |
| count() | 统计某个非空值的数量,,可以计算dataframe和series结构的数据。 |
df.count() df[“name:”].count() |
| sum() | 求和 |
df.sum() df[“year”].sum() |
| mean() | 求均值,可以计算dataframe和series结构的数据 |
df.mean() df[“year”].mean() |
| median() | 求中位数 | |
| mode() | 求众数 | |
| std() | 求标准差 | |
| min() | 求最小值 |
df.min() df[“year”].min() |
| max() | 求最大值 |
df.max() df[“year”].max() |
| abs() | 求绝对值 | |
| prod() | 求所有数值的乘积。 | |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 | |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 | |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
3.2 pandas iteration遍历
如果想要遍历 DataFrame 的每一行,我们下列函数:
items():以键值对 (key,value) 的形式遍历列;注意:在pandas 2.0 以上版iteritems()本中,取消了iteritems()函数,items()函数具有相同的功能。iterrows():以 (row_index,row) 的形式遍历行;itertuples():使用已命名元组的方式遍历行。
1. items():以键值对 (key,value) 的形式遍历列
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3'])
print(f'#原始数据
{df}')
"""
#原始数据
col1 col2 col3
0 0.284440 -0.741417 0.232854
1 1.425886 -0.725062 -0.231505
2 -0.959947 -0.253215 0.972865
3 -1.675378 1.439948 -1.232833
"""
#items():以键值对 (key,value) 的形式遍历 以列标签为键,以对应列的元素为值
for key,value in df.items():
print (f'#key以列标签为键:{key}')
print(f'#value以对应列的元素为值
{value}')
"""
结果为:
#key以列标签为键:col1
#value以对应列的元素为值
0 0.284440
1 1.425886
2 -0.959947
3 -1.675378
Name: col1, dtype: float64
#key以列标签为键:col2
#value以对应列的元素为值
0 -0.741417
1 -0.725062
2 -0.253215
3 1.439948
Name: col2, dtype: float64
#key以列标签为键:col3
#value以对应列的元素为值
0 0.232854
1 -0.231505
2 0.972865
3 -1.232833
Name: col3, dtype: float64
"""2. iterrows():以 (row_index,row) 的形式遍历行
该方法按行遍历,返回一个迭代器,以行索引标签为键,以每一行数据为值。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3'])
print(f'#原始数据
{df}')
"""
#原始数据
col1 col2 col3
0 0.691124 -0.726609 -1.163696
1 -1.143281 0.008123 -0.496127
2 -0.677804 -1.307235 -0.926160
3 0.280503 -0.777648 0.970424
"""
#该方法按行遍历,返回一个迭代器,以行索引标签为键,以每一行数据为值
for row_index, row in df.iterrows():
print(f'#行索引标签为键row_index:{row_index}')
print(f'#每一行数据为值row:
{row}')
print(f'#每一行转成字典(列表签:value):
{row.to_dict()}')
"""
结果为:
#行索引标签为键row_index:0
#每一行数据为值row:
col1 0.691124
col2 -0.726609
col3 -1.163696
Name: 0, dtype: float64
#每一行转成字典(列标签:value):
{'col1': 0.6911237932116442, 'col2': -0.7266085751270223, 'col3': -1.1636955887400091}
#行索引标签为键row_index:1
#每一行数据为值row:
col1 -1.143281
col2 0.008123
col3 -0.496127
Name: 1, dtype: float64
#每一行转成字典(列标签:value):
{'col1': -1.143281153387153, 'col2': 0.008123105611642303, 'col3': -0.4961267413779065}
#行索引标签为键row_index:2
#每一行数据为值row:
col1 -0.677804
col2 -1.307235
col3 -0.926160
Name: 2, dtype: float64
#每一行转成字典(列标签:value):
{'col1': -0.6778043873693782, 'col2': -1.3072345379948949, 'col3': -0.926160102004644}
#行索引标签为键row_index:3
#每一行数据为值row:
col1 0.280503
col2 -0.777648
col3 0.970424
Name: 3, dtype: float64
#每一行转成字典(列标签:value):
{'col1': 0.2805031017555484, 'col2': -0.7776480571277457, 'col3': 0.9704240438056065}
"""3. itertuples():使用已命名元组的方式遍历行
itertuples() 同样将返回一个迭代器,该方法会把 DataFrame 的每一行生成一个元组。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3'])
print(f'#原始数据
{df}')
"""
#原始数据
col1 col2 col3
0 -0.059090 -0.159421 -0.474316
1 -0.736043 0.747226 0.171213
2 -0.380318 1.080828 -1.653805
3 -0.457426 0.737069 -1.045649
"""
for row in df.itertuples():
print(f'#每一行生成一个元组
{row}')
"""
结果为:
#每一行生成一个元组
Pandas(Index=0, col1=-0.05909003053453285, col2=-0.15942088983693178, col3=-0.4743159410530973)
#每一行生成一个元组
Pandas(Index=1, col1=-0.736042848878659, col2=0.7472261708453659, col3=0.17121325299305076)
#每一行生成一个元组
Pandas(Index=2, col1=-0.3803178814594451, col2=1.0808276756692548, col3=-1.6538049580807752)
#每一行生成一个元组
Pandas(Index=3, col1=-0.4574258113524991, col2=0.737068849037987, col3=-1.0456494326191845)
"""3.3 pandas sorting排序
pandas中排序函数有sort_index()和sort_values()两个函数,python更推荐用只用df. sort_index()对“根据行标签”和“根据列标签”排序,其他排序方式用df.sort_values()。
作用:默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
sort_index()函数及语法为:
sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None)
参数说明:
axis: 0按照行名排序;1按照列名排序level: 默认None,指定按照多级索引的哪一级进行排序。ascending: 默认True升序排列;False降序排列inplace: 默认False,指定是否在原 DataFrame 上修改;默认为 False,不在原 DataFrame 上修改。kind: 排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。na_position:缺失值默认排在最后{“first”,”last”}by: 按照某一列或几列数据进行排序,但是by参数貌似不建议使用
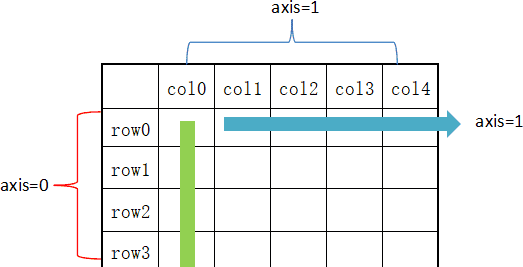
从图上可以看出,axis=0 表示按垂直方向进行计算,而 axis=1 则表示按水平方向。
1. axis=0, ascending=True 默认按“行标签”升序排列
import numpy as np
import pandas as pd
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
print(f'#原始数据
{df}')
"""
#原始数据
b a c
2 1 4 1
0 2 3 3
1 2 2 8
3 3 1 2
"""
print(f'#默认按“行标签”升序排序,或df.sort_index(axis=0, ascending=True)
{df.sort_index()}')
"""
#默认按“行标签”升序排序,或df.sort_index(axis=0, ascending=True)
b a c
0 2 3 3
1 2 2 8
2 1 4 1
3 3 1 2
"""2. axis=1 按“列标签”升序排列
import numpy as np
import pandas as pd
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
print(f'#原始数据
{df}')
"""
#原始数据
b a c
2 1 4 1
0 2 3 3
1 2 2 8
3 3 1 2
"""
print(f'#按“列标签”升序排序,或df.sort_index(axis=1, ascending=True)
{df.sort_index(axis=1)}')
"""
#按“列标签”升序排序,或df.sort_index(axis=1, ascending=True)
a b c
2 4 1 1
0 3 2 3
1 2 2 8
3 1 3 2
"""sort_values()函数语法:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数说明:
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。by:str or list of str;如果axis=0,那么by=”列名”;如果axis=1,那么by=”行名”。ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。inplace:布尔型,是否用排序后的数据框替换现有的数据框。kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
"""
b a c
2 1 4 1
0 2 3 3
1 3 2 8
3 2 1 2
"""
# 1.按b列升序排序
df.sort_values(by='b') #等同于df.sort_values(by='b',axis=0)
"""
b a c
2 1 4 1
0 2 3 3
3 2 1 2
1 3 2 8
"""
# 2.先按b列降序,再按a列升序排序
df.sort_values(by=['b','a'],axis=0,ascending=[False,True])
# 等同于df.sort_values(by=['b','a'],axis=0,ascending=[False,True])
"""
b a c
1 3 2 8
3 2 1 2
0 2 3 3
2 1 4 1
"""
# 3.按行3升序排列
df.sort_values(by=3,axis=1) #必须指定axis=1
"""
a b c
2 4 1 1
0 3 2 3
1 2 3 8
3 1 2 2
"""
# 4.按行3升序,行0降排列
df.sort_values(by=[3,0],axis=1,ascending=[True,False])
"""
a c b
2 4 1 1
0 3 3 2
1 2 8 3
3 1 2 2
"""4 pandas数据清洗
4.1 pandas去重
在数据分析中,去除重复数据是常见的操作。Pandas 提供了强大的 drop_duplicates() 方法,可以高效地对 DataFrame 进行去重。
drop_duplicates()语法:
df.drop_duplicates(subset=['A','B','C'],keep='first',inplace=False)
参数说明如下:
subset:表示要去重的列名,默认为 None。 keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。 inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
示例:
import pandas as pd
data = {
'A':[1,0,1,1],
'B':[0,2,5,0],
'C':[4,0,4,4],
'D':[1,0,1,1]
}
df = pd.DataFrame(data)
print(f'#原始数据
{df}')
"""
#原始数据
A B C D
0 1 0 4 1
1 0 2 0 0
2 1 5 4 1
3 1 0 4 1
"""
# 1.保留第一次出现的行重复项
#默认是keep=first 保留第一次出现的重复项 inplace=False 删除后返回一个副本
df_drop = df.drop_duplicates()
#或者写出df_drop = df.drop_duplicates(keep='first', inplace=False)
print(f'#去重后的数据
{df_drop}')
"""
#去重后的数据
A B C D
0 1 0 4 1
1 0 2 0 0
2 1 5 4 1
"""
# 2. subset删除指定的单列去重
#subset:表示要去重的列名,默认为 None。
##去除所有重复项,对于B列来说两个0是重复项
df_drop = df.drop_duplicates(subset=['B'], inplace=False, keep=False)
#简写,省去subset参数
#df.drop_duplicates(['B'],keep=False)
print(f'#删除指定的列
{df_drop}')
"""
#原始数据
A B C D
0 1 0 4 1
1 0 2 0 0
2 1 5 4 1
3 1 0 4 1
#删除指定的列
A B C D
1 0 2 0 0
2 1 5 4 1
"""
# 删除重复项后,行标签使用的数字是原来的,并没有从 0 重新开始
# 要想从 0 重置索引,Pandas 提供了 reset_index() 函数,用法为:
# df_drop = df.drop_duplicates(subset=['B'],inplace=False, keep=False)
# df_reset = df_drop.reset_index(drop=True)
# 3. subset指定多列同时去重
df = pd.DataFrame({'C_ID':[1,1,2,12,34,23,45,34,23,12,2,3,4,1],
'Age':[12,12,15,18, 12, 25, 21, 25, 25, 18, 25,12,32,18],
'G_ID':['a','a','c','a','b','s','d','a','b','s','a','d','a','a']})
print(f'#原始数据
{df}')
"""
#原始数据
C_ID Age G_ID
0 1 12 a
1 1 12 a
2 2 15 c
3 12 18 a
4 34 12 b
5 23 25 s
6 45 21 d
7 34 25 a
8 23 25 b
9 12 18 s
10 2 25 a
11 3 12 d
12 4 32 a
13 1 18 a
"""
#last只保留最后一个重复项 去除重复项后并不更改行索引
df_drop = df.drop_duplicates(['Age', 'G_ID'], keep='last')
print(f'#去除指定多列的数据
{df_drop}')
"""
#去除指定多列的数据
C_ID Age G_ID
1 1 12 a
2 2 15 c
4 34 12 b
5 23 25 s
6 45 21 d
8 23 25 b
9 12 18 s
10 2 25 a
11 3 12 d
12 4 32 a
13 1 18 a
"""4.2 Pandas缺失值处理
1.缺失值判断
检测缺失值,Pandas 提供了 isnull() 和 notnull() 两个函数,它们同时适用于 Series 和 DataFrame 对象。
(1) Dataframe.isnull()语法
Pandas.isnull(“DataFrame Name”) 或 DataFrame.isnull()
参数:用于检查空值的对象。返回类型:布尔值的数据帧,对NaN值来说是真。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'原始数据
{df}')
"""
#原始数据
one two three
a -0.792201 0.659663 1.412614
c -1.204695 0.566436 -2.052258
e 0.829130 1.896560 -0.321445
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a -0.792201 0.659663 1.412614
b NaN NaN NaN
c -1.204695 0.566436 -2.052258
d NaN NaN NaN
e 0.829130 1.896560 -0.321445
f NaN NaN NaN
"""
#isnull() 检查是否是缺失值,若是则返回True 反之返回False
print(f'#isnull()判断第one列的每个元素是否是缺失值
{df["one"].isnull()}')
"""
#isnull()判断第one列的每个元素是否是缺失值
a False
b True
c False
d True
e False
f True
Name: one, dtype: bool
"""(2) Dataframe.notnull()语法
Pandas.notnull(“DataFrame Name”) 或 DataFrame.notnull()
参数: 检查空值的对象返回值 : 对NaN值来说是假的布尔值的数据帧.
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'原始数据
{df}')
"""
#原始数据
one two three
a -1.211702 0.977706 0.684588
c -0.042288 1.814968 -0.755887
e 1.144412 0.206859 -1.498902
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a -1.211702 0.977706 0.684588
b NaN NaN NaN
c -0.042288 1.814968 -0.755887
d NaN NaN NaN
e 1.144412 0.206859 -1.498902
f NaN NaN NaN
"""
#notnull() 检查是否不是缺失值,若不是则返回True 反之返回False
print(f'判断是第one列的每个元素是否不是缺失值
{df["one"].notnull()}')
"""
#判断是第one列的每个元素是否不是缺失值
a True
b False
c True
d False
e True
f False
Name: one, dtype: bool
"""2. 缺失数据计算
计算缺失数据时,需要注意两点:首先数据求和时,将 NA 值视为 0 ,其次,如果要计算的数据为 NA,那么结果就是 NA。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'#原始数据
{df}')
"""
#原始数据
one two three
a 2.570816 0.489973 -1.334633
c -0.277604 0.691039 -3.298916
e 0.651539 0.145426 0.197667
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a 2.570816 0.489973 -1.334633
b NaN NaN NaN
c -0.277604 0.691039 -3.298916
d NaN NaN NaN
e 0.651539 0.145426 0.197667
f NaN NaN NaN
"""
# 计算缺失数据时,需要注意两点:首先数据求和时,将 NA 值视为 0
# 其次,如果要计算的数据为 NA,那么结果就是 NA
print(df['one'].sum())
"""
#第one列求和结果:
2.944751293477092
"""3. 清理并填充缺失值
(1)fillna()标量替换NaN
fillna()函数语法:
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数:
value:用于填充的空值的值。method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。'bfill'和'ffill'的用法在pycharm3.12版本中已无法编译通过,已被bfill()和'ffill()函数取代。axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'#原始数据
{df}')
"""
#原始数据
one two three
a 0.252345 0.429046 -2.552799
c -2.404367 -1.042196 0.655366
e -0.254975 0.224454 -0.493185
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a 0.252345 0.429046 -2.552799
b NaN NaN NaN
c -2.404367 -1.042196 0.655366
d NaN NaN NaN
e -0.254975 0.224454 -0.493185
f NaN NaN NaN
"""
#用fillna(6)标量替换NaN
print(f'用fillna(6)标量替换NaN后的数据
{df.fillna(6)}')
"""
#用fillna(6)标量替换NaN后的数据
one two three
a 0.252345 0.429046 -2.552799
b 6.000000 6.000000 6.000000
c -2.404367 -1.042196 0.655366
d 6.000000 6.000000 6.000000
e -0.254975 0.224454 -0.493185
f 6.000000 6.000000 6.000000
"""(2) ffill() 向前填充和 bfill() 向后填充
向前填充(ffill)使用前面的有效值填充后面的缺失值,先后填充(bfill)则相反,使用后面的有效值填充前面的缺失值。
为什么需要特殊的填充方法?
1.时间序列数据中,相邻数据点通常具有连续性,如传感器读数;2.某些场景下,缺失值具有明确的填充逻辑;3.相比简单填充固定值,前向/后向填充能更好地保持数据趋势。
ffill()函数语法:
DataFrame.ffill(axis=None, inplace=False, limit=None, downcast=None)
参数:
axis:{0,索引,1,栏}inplace:如果为True,则填写。注意:这将修改此对象的任何其他视图(例如,DataFrame中列的no-copy切片)。limit:如果指定了method,则这是要向前/向后填充的连续NaN值的最大数量。换句话说,如果存在连续的NaN数量大于此数量的缺口,它将仅被部分填充。如果未指定method,则这是将填写NaN的整个轴上的最大条目数。如果不为None,则必须大于0。Downcast:item-> dtype决定是否向下转换的内容,或字符串“ infer”将尝试向下转换为适当的相等类型(例如,如果可能,将float64转换为int64)
返回:fill:DataFrame
bfill()函数语法:
DataFrame.bfill(axis=None, inplace=False, limit=None, downcast=None)
参数:
axis: 可以是'index'(或0)或'columns'(或1),指定填充的方向。inplace: 布尔值,如果为True,则直接修改原始数据。limit: 整数,指定连续填充的最大数量。downcast: 可选,用于控制结果的数据类型。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'#原始数据
{df}')
"""
#原始数据
one two three
a -0.657623 0.003340 0.866407
c 0.668809 -0.155485 -0.065128
e -0.303612 -0.119558 1.671199
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a -0.657623 0.003340 0.866407
b NaN NaN NaN
c 0.668809 -0.155485 -0.065128
d NaN NaN NaN
e -0.303612 -0.119558 1.671199
f NaN NaN NaN
"""
import numpy as np
import pandas as pd
print(f"#.fillna(method='ffill')向前填充后的数据
{df.ffill()}")
"""
#.fillna(method='ffill')向前填充后的数据
one two three
a -0.657623 0.003340 0.866407
b -0.657623 0.003340 0.866407
c 0.668809 -0.155485 -0.065128
d 0.668809 -0.155485 -0.065128
e -0.303612 -0.119558 1.671199
f -0.303612 -0.119558 1.671199
"""
print(f"#.bfillna()向后填充后的数据
{df.bfill()}")
"""
#.bfill()向后填充后的数据 如果最后面没有数据就不会填充
one two three
a -0.657623 0.003340 0.866407
b 0.668809 -0.155485 -0.065128
c 0.668809 -0.155485 -0.065128
d -0.303612 -0.119558 1.671199
e -0.303612 -0.119558 1.671199
f NaN NaN NaN
"""4. 删除缺失值
如果想删除缺失值,那么使用 dropna() 函数与参数 axis 可以实现。在默认情况下,按照 axis=0 来按行处理,这意味着如果某一行中存在 NaN 值将会删除整行数据。
dropna()方法,能够找到DataFrame类型数据的空值(缺失值),将空值所在的行/列删除后,将新的DataFrame作为返回值返回。
dropna()函数语法:
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
示例:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(3, 3), index=list("ace"), columns=['one', 'two', 'three'])
print(f'#原始数据
{df}')
"""
#原始数据
one two three
a -1.706917 0.169167 -1.149683
c -0.132433 -0.003184 -0.562634
e -0.865398 -0.877156 1.870602
"""
#通过使用 reindex(重构索引),创建了一个存在缺少值的 DataFrame对象
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(f'#使用 reindex(重构索引)后的数据
{df}')
"""
#使用 reindex(重构索引)后的数据
one two three
a -1.706917 0.169167 -1.149683
b NaN NaN NaN
c -0.132433 -0.003184 -0.562634
d NaN NaN NaN
e -0.865398 -0.877156 1.870602
f NaN NaN NaN
"""
#dropna() axis=0如果某一行中存在 NaN 值将会删除整行数据
print(f'#dropna()删除后的数据
{df.dropna()}')
"""
#dropna()删除后的数据
one two three
a -1.706917 0.169167 -1.149683
c -0.132433 -0.003184 -0.562634
e -0.865398 -0.877156 1.870602
"""5. Excel读写操作
5.1 读Excel文件
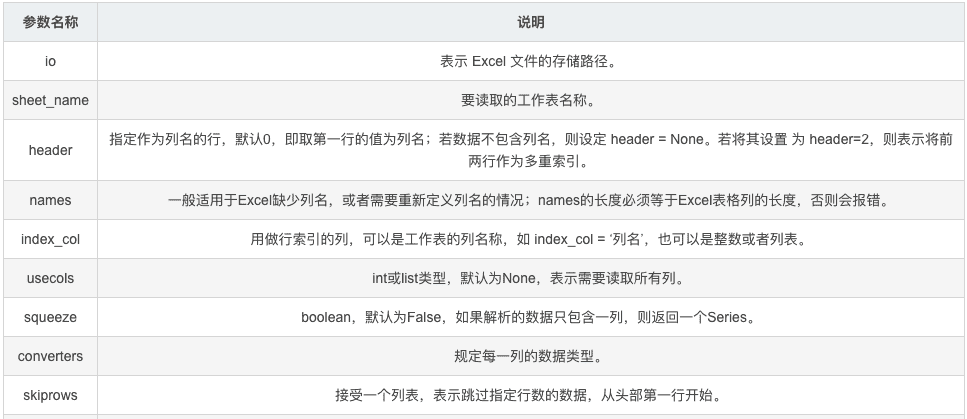
read_excel()函数读取 Excel 表格中的数据,语法格式如下:
pd.read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
parse_cols=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
**kwds)
简要参数说明:
详细参数说明:
(1) io (必需参数)
说明: Excel文件路径或类文件对象
可以是文件路径字符串、URL或文件对象支持本地路径和网络路径
示例:
import pandas as pd
# 读取本地文件
df1 = pd.read_excel('data.xlsx')
df2 = pd.read_excel('/path/to/data.xls')
# 读取URL
df3 = pd.read_excel('https://example.com/data.xlsx')
# 读取文件对象
with open('data.xlsx', 'rb') as f:
df4 = pd.read_excel(f)(2)sheet_name
说明: 指定要读取的工作表
0 或 'Sheet1': 读取第一个工作表(默认)None: 读取所有工作表,返回字典字符串: 按名称读取特定工作表整数: 按索引读取工作表(0-based)列表: 读取多个工作表
示例:
import pandas as pd
# 读取第一个工作表(默认)
df1 = pd.read_excel('data.xlsx')
# 按名称读取特定工作表
df2 = pd.read_excel('data.xlsx', sheet_name='Sales')
# 按索引读取(第二个工作表,索引为1)
df3 = pd.read_excel('data.xlsx', sheet_name=1)
# 读取多个工作表,返回字典
dfs = pd.read_excel('data.xlsx', sheet_name=[0, 'Sales'])
# 访问: dfs[0] 和 dfs['Sales']
# 读取所有工作表
all_sheets = pd.read_excel('data.xlsx', sheet_name=None)(3) header
说明: 指定列名所在行
None: 没有列名,自动生成数字列名0: 第一行作为列名(默认)整数: 指定行索引作为列名列表: 多级列名(用于MultiIndex)
示例:
import pandas as pd
# 第一行作为列名(默认)
df1 = pd.read_excel('data.xlsx', header=0)
# 没有列名,自动生成0,1,2...
df2 = pd.read_excel('data.xlsx', header=None)
# 第三行作为列名(索引为2)
df3 = pd.read_excel('data.xlsx', header=2)
# 多级列名(第0行和第1行)
df4 = pd.read_excel('data.xlsx', header=[0, 1])(4) names
说明: 自定义列名列表
覆盖原有的列名必须与列数匹配
示例:
import pandas as pd
# 自定义列名
custom_columns = ['ID', 'Name', 'Age', 'Salary']
df = pd.read_excel('data.xlsx', names=custom_columns)
# 结合header=None使用
df = pd.read_excel('data.xlsx', header=None, names=custom_columns)(5)index_col
说明: 将指定的列作为行标签
None: 不使用任何列作为索引(默认)整数: 指定列(整数值)作为行标签列表: 多级索引
示例:
import pandas as pd
# 不使用索引(默认)
df1 = pd.read_excel('data.xlsx', index_col=None)
# 第一列作为索引
df2 = pd.read_excel('data.xlsx', index_col=0)
# 前两列作为多级索引
df3 = pd.read_excel('data.xlsx', index_col=[0, 1])(6)usecols
说明: 指定要读取的列
None: 读取所有列(默认)整数列表: 指定列索引字符串: Excel列名范围(如'A:C')列名列表: 指定要读取的列名可调用函数: 根据列名筛选
示例:
import pandas as pd
# 读取所有列(默认)
df1 = pd.read_excel('data.xlsx')
# 读取前3列(索引0,1,2)
df2 = pd.read_excel('data.xlsx', usecols=[0, 1, 2])
# 读取A到C列
df3 = pd.read_excel('data.xlsx', usecols='A:C')
# 读取指定列名
df4 = pd.read_excel('data.xlsx', usecols=['Name', 'Age'])
# 使用函数筛选(列名包含'a'的列)
df5 = pd.read_excel('data.xlsx', usecols=lambda x: 'a' in x.lower())(7)dtype
说明: 指定列的数据类型
字典形式: {列名: 数据类型}
示例:
import pandas as pd
# 指定特定列的数据类型
dtype_dict = {'ID': str, 'Age': float, 'Salary': int}
df = pd.read_excel('data.xlsx', dtype=dtype_dict)(8) skiprows
说明: 跳过指定行
整数: 跳过前n行列表: 跳过指定行号可调用函数: 根据行索引筛选
示例:
import pandas as pd
# 跳过前3行
df1 = pd.read_excel('data.xlsx', skiprows=3)
# 跳过第0, 2, 4行
df2 = pd.read_excel('data.xlsx', skiprows=[0, 2, 4])
# 跳过偶数行
df3 = pd.read_excel('data.xlsx', skiprows=lambda x: x % 2 == 0)(9)nrows
说明: 读取的行数
示例:
import pandas as pd
# 只读取前100行
df = pd.read_excel('data.xlsx', nrows=100)(10)na_values
说明: 指定哪些值应被视为NaN
示例:
import pandas as pd
# 将'N/A', 'NULL', '缺失'视为NaN
na_vals = ['N/A', 'NULL', '缺失', '']
df = pd.read_excel('data.xlsx', na_values=na_vals)(11)parse_dates 和 date_parser
说明: 尝试将列解析为日期。parse_dates 和 date_parser 是一对协同工作的参数,它们共同决定了如何将Excel中的数据转换为日期时间对象。简单来说,parse_dates负责“解析哪些”,而date_parser负责“如何解析”。
注意:parse_dates指定列后,默认将自动用会使用pd.to_datetime()函数作为默认的日期解析器进行解析,这个函数可以自动推断格式或处理多种格式,可以独立使用;date_parser必须与parse_dates配合才能使用。
parse_dates:
布尔值: 尝试解析索引列表: 指定要解析的列字典: 组合多列作为日期
示例:
import pandas as pd
from datetime import datetime
# 一、parse_dates 参数详解
# 1.单列解析:将一个单独的列解析为日期。
# 解析名为 'date_column' 的列
df = pd.read_excel('file.xlsx', parse_dates=['date_column'])
# 解析第0列(第一列)
df = pd.read_excel('file.xlsx', parse_dates=[0])
# 2.多列解析:同时将多个列解析为独立的日期列。
# 解析名为 'start_date' 和 'end_date' 的列
df = pd.read_excel('file.xlsx', parse_dates=['start_date', 'end_date'])
# 解析第0列和第2列
df = pd.read_excel('file.xlsx', parse_dates=[0, 2])
# 3.多列合并解析:将多列合并起来共同解析为一个日期列。这在日期时间成分分散在不同列
# 时(如年、月、日分别在三列)特别有用
# 将 'Year', 'Month', 'Day' 三列合并解析为一个日期列
df = pd.read_excel('file.xlsx', parse_dates=[['Year', 'Month', 'Day']])
# 合并解析,并为生成的新列命名
df = pd.read_excel('file.xlsx', parse_dates={'event_date': ['Year', 'Month', 'Day']})
# 二、date_parser 参数详解
# date_parser 用于处理非标准或复杂的日期格式。Pandas内置的解析器已经很强大,但当你遇到它无法
# 自动识别的格式时,就需要date_parser出场了。
# 1. 解析特定格式的日期
# 假设日期格式为 "日/月/年 时:分",例如 "25/12/2023 14:30"
date_parser = lambda x: datetime.strptime(x, '%d/%m/%Y %H:%M')
df = pd.read_excel('file.xlsx', parse_dates=['datetime_column'], date_parser=date_parser)
# 2. 解析包含特殊字符的日期:
# 处理如 "公元2021年2月26日" 这样的格式
date_parser = lambda x: datetime.strptime(x, "公元%Y年%m月%d日")
df = pd.read_excel('file.xlsx', parse_dates=['上市日期'], date_parser=date_parser)(12) thousands / decimal(这个参数在CSV文件读取中用)
说明:参数用于指定千位分隔符,并移除千位分隔符,将字符串列解析为数字。默认情况下,数据为字符串类型,如果Excel文件中有一列数据使用逗号作为千位分隔符,可以设置thousands参数,将字符串解析为数字。
示例:
import pandas as pd
# 欧洲格式:千位分隔符为'.',小数点为','
df = pd.read_excel('data.xlsx', thousands=',')(13)engine
说明: 指定解析引擎
'xlrd': 用于.xls文件'openpyxl': 用于.xlsx文件None: 自动选择
示例:
import pandas as pd
# 明确指定引擎
df1 = pd.read_excel('data.xls', engine='xlrd')
df2 = pd.read_excel('data.xlsx', engine='openpyxl')(14) converters
说明: 列转换函数字典,指定列的转换函数
示例:
import pandas as pd
# 自定义转换函数
def clean_salary(x):
if isinstance(x, str):
return float(x.replace('$', '').replace(',', ''))
return x
converters = {
'Name': lambda x: x.strip().title(),
'Salary': clean_salary
}
df = pd.read_excel('data.xlsx', converters=converters)(15)skipfooter
说明: 跳过文件末尾的行数
示例:
import pandas as pd
# 跳过最后5行
df = pd.read_excel('data.xlsx', skipfooter=5)综合运用示例:
import pandas as pd
# 复杂读取场景
df = pd.read_excel(
'sales_data.xlsx',
sheet_name='Monthly Sales', # 指定工作表
header=0, # 第一行作为列名
usecols=['Date', 'Product', 'Sales', 'Region'], # 只读取指定列
parse_dates=['Date'], # 解析日期列
dtype={'Product': 'category'}, # 产品列作为分类数据
skiprows=1, # 跳过第一行(可能是标题)
nrows=1000, # 只读取前1000行
na_values=['N/A', 'Missing'], # 自定义缺失值
thousands=',', # 千位分隔符
engine='openpyxl' # 指定引擎
)
print(df.head())
print(f"数据形状: {df.shape}")
print(f"列数据类型:
{df.dtypes}")5.2 写Excel文件
to_excel() 函数可以将 Dataframe 中的数据写入到 Excel 文件。
如果想要把单个对象写入 Excel 文件,那么必须指定目标文件名;如果想要写入到多张工作表中,则需要创建一个带有目标文件名的ExcelWriter对象,并通过sheet_name参数依次指定工作表的名称。
to_ecxel() 语法格式如下:
DataFrame.to_excel(excel_writer,
sheet_name = 'Sheet1',
na_rep = '',
float_format = None,
columns = None,
header = True,
index = True,
index_label = None,
startrow = 0,
startcol = 0,
engine = None,
merge_cells = True,
encoding = None,
inf_rep = 'inf',
verbose = True,
freeze_panes = None)
| 参数名称 | 描述说明 |
|---|---|
| excel_wirter | 文件路径或ExcelWriter对象。例: |
| sheet_name | 工作表名称,默认为 |
| na_rep | 缺失值的表示字符串,默认为空字符串。例: |
| float_format | 浮点数格式字符串。例: |
| columns | 指定要写入的列。传入一个列名的列表。例:columns=['Name', 'Age']。 |
| header | 是否写入列名,默认为 |
| index | 是否写入行索引,默认为True。通常设为False以避免将索引作为一列数据写入。 |
| index_label | 引用索引列的列标签。如果未指定,并且 hearder 和 index 均为为 True,则使用索引名称。如果 DataFrame使用 MultiIndex,则需要给出一个序列。 |
| startrow |
数据写入的起始行,从0开始。例: |
| startcol |
数据写入的起始列,从0开始。例:startcol=2从第三列开始写入。 |
| engine | 指定写入引擎,如 |
| merge_cells | 将多索引写入为合并的单元格,默认为 |
示例如下:
# 一、简单示例
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'Name': ['Tom', 'Nick', 'John'], 'Age': [28, 32, 25]})
# 写入Excel文件,不保存行索引
df.to_excel('output.xlsx', index=False)
# 二、进阶使用方法示例
# 1.写入多个工作表
# 如果需要将多个DataFrame写入同一个Excel文件的不同工作表,需要使用 pandas.ExcelWriter
# 作为上下文管理器
df1 = pd.DataFrame({'A': [1, 2, 3]})
df2 = pd.DataFrame({'B': [4, 5, 6]})
with pd.ExcelWriter('output_multi.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet1')
df2.to_excel(writer, sheet_name='Sheet2')
# 2.追加数据到现有文件
# ExcelWriter 还可以用于追加数据到已存在的Excel文件中。这时需要将 mode 参数设置为 'a'。
# 假设 'output.xlsx' 已存在,我们追加一个新的工作表
with pd.ExcelWriter('output.xlsx', mode='a') as writer:
df_new.to_excel(writer, sheet_name='追加的工作表')6.时间序列
Pandas提供了强大的时间序列处理功能,比Python内置的datetime模块更强大。时间序列分析帮助我们理解数据的趋势、周期性和异常点,从而做出更好的预测和决策。
6.1 时间序列是什么
6.1.1 用生活例子理解时间序列
想象你每天记录体重,连续记录一个月,这些按日期排列的体重数据就是时间序列。时间序列就是按时间顺序排列的一系列数据点。
生活中的时间序列例子:
每天的温度记录
每月的工资收入
每小时的股票价格
每年的身高变化
6.1.2 为什么要用Pandas处理时间序列?
如果没有专门的时间序列工具,处理时间数据会很麻烦:
计算”3天前的数据”需要复杂的日期计算
分析”每月的平均值”需要手动分组
处理”不同时区”需要转换公式
Pandas让这些操作变得简单直观!
6.2 时间数据类型详解
6.2.1 三种核心时间类型
Timestamp(时间戳):
是什么:代表一个具体的时间点,比如”2024年1月15日上午10点30分”
相当于:日历上的某一个具体日期和时间
DatetimeIndex(时间索引):
是什么:多个时间戳组成的索引,专门用来给数据贴时间标签
相当于:日记本的日期栏,每天对应一页
Timedelta(时间间隔):
是什么:表示一段时间长度,比如”3天5小时”
相当于:计算两个日期之间相差多久
6.2.2 创建时间序列的具体方法
import pandas as pd
import numpy as np
# 1. 创建单个时间点(Timestamp)
# 就像在日历上圈出某一天
birthday = pd.Timestamp('2024-05-20') # 创建一个日期
meeting_time = pd.Timestamp('2024-01-15 14:30:00') # 创建具体时间点
print("生日日期:", birthday)
print("会议时间:", meeting_time)
print("会议所在的年份:", meeting_time.year)
print("会议所在的月份:", meeting_time.month)
# 2. 创建时间索引(DatetimeIndex)
# 就像制作一个连续的时间表格
# 方法一:直接指定开始和结束日期,自动填充
week_dates = pd.date_range(start='2024-01-01', end='2024-01-07', freq='D')
print("
一周的日期:")
print(week_dates)
# 方法二:指定开始日期和数量
first_5_days = pd.date_range(start='2024-01-01', periods=5, freq='D')
print("
前5天日期:")
print(first_5_days)
# 3. 创建时间间隔(Timedelta)
# 就像计算假期有多长
vacation = pd.Timedelta(days=7) # 7天假期
work_shift = pd.Timedelta(hours=8) # 8小时工作制
print(f"
假期长度: {vacation}")
print(f"工作时间: {work_shift}")函数说明(有关内容熟悉后可以不看):
1. pd.Timestamp()
pd.Timestamp(ts_input, freq=None, tz=None, unit=None, year=None, month=None, day=None, hour=None, minute=None, second=None, microsecond=None)
参数详解:
ts_input
freq
tz
unit
year, month, day, hour, minute, second, microsecond
示例如下:
import pandas as pd
# 多种创建Timestamp的方式
ts1 = pd.Timestamp('2024-01-15') # 从字符串
ts2 = pd.Timestamp(2024, 1, 15, 14, 30, 45) # 分别指定年月日时分秒
ts3 = pd.Timestamp(1705314600, unit='s') # 从时间戳(秒)
ts4 = pd.Timestamp('2024-01-15 14:30:00', tz='Asia/Shanghai') # 带时区
print("从字符串创建:", ts1)
print("分别指定参数创建:", ts2)
print("从时间戳创建:", ts3)
print("带时区的时间:", ts4)
# 访问Timestamp的属性
print(f"年份: {ts2.year}")
print(f"月份: {ts2.month}")
print(f"日期: {ts2.day}")
print(f"小时: {ts2.hour}")
print(f"星期几: {ts2.dayofweek}") # 周一=0, 周日=6
print(f"一年中的第几天: {ts2.dayofyear}")2.
pd.date_range()
pd.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
参数详解:
start
end
periods
freq
tz
normalize
name
closed
频率字符串freq常用值:
'D'
'H'
'T'
'min'
'S'
'M'
'MS'
'W'
'Q'
'QS'
'A'
'Y'
'AS'
'YS'
示例:
# 多种创建时间范围的方式
# 1. 指定开始和结束日期
dates1 = pd.date_range(start='2024-01-01', end='2024-01-10', freq='D')
print("指定起止日期:")
print(dates1)
# 2. 指定开始日期和数量
dates2 = pd.date_range(start='2024-01-01', periods=7, freq='D')
print("
指定开始日期和数量:")
print(dates2)
# 3. 指定结束日期和数量
dates3 = pd.date_range(end='2024-01-10', periods=5, freq='D')
print("
指定结束日期和数量:")
print(dates3)
# 4. 不同频率的时间序列
hourly = pd.date_range('2024-01-01', periods=24, freq='H')
monthly = pd.date_range('2024-01-01', periods=12, freq='M')
weekly = pd.date_range('2024-01-01', periods=4, freq='W')
print(f"
每小时数据(前5个): {hourly[:5]}")
print(f"每月数据: {monthly}")
print(f"每周数据: {weekly}")
# 5. 带时区的时间序列
tz_dates = pd.date_range('2024-01-01', periods=5, freq='D', tz='Asia/Shanghai')
print(f"
带时区的时间序列: {tz_dates}")3. Timedelta – 时间间隔
pd.Timedelta(value=None, unit=None, **kwargs)
参数详解:
value
unit
**kwargs
示例:
# 多种创建Timedelta的方式
td1 = pd.Timedelta(days=5) # 5天
td2 = pd.Timedelta(days=2, hours=3) # 2天3小时
td3 = pd.Timedelta('1 days 2 hours 3 minutes 4 seconds') # 从字符串
td4 = pd.Timedelta(weeks=2) # 2周
td5 = pd.Timedelta(1.5, unit='h') # 1.5小时
print("5天:", td1)
print("2天3小时:", td2)
print("从字符串创建:", td3)
print("2周:", td4)
print("1.5小时:", td5)
# Timedelta运算
start_time = pd.Timestamp('2024-01-01')
end_time = start_time + pd.Timedelta(days=7)
time_diff = end_time - start_time
print(f"
开始时间: {start_time}")
print(f"结束时间: {end_time}")
print(f"时间差: {time_diff}")
print(f"时间差天数: {time_diff.days}")
print(f"时间差总秒数: {time_diff.total_seconds()}")6.3 时间索引的妙用
6.3.1 什么是时间索引?
时间索引就是用时间作为数据的标签,就像给日记的每一页标上日期。
优势:
按时间查找数据特别快
可以用自然语言选择数据(比如”给我1月份的数据”)
自动处理闰年、月份天数等问题
6.3.2 创建带时间索引的数据
# 创建一周的温度数据
dates = pd.date_range('2024-01-01', periods=7, freq='D')
temperatures = [15, 16, 14, 18, 17, 16, 19]
# 创建Series,用日期作为索引
temperature_series = pd.Series(temperatures, index=dates)
print("一周温度记录:")
print(temperature_series)
print(f"
数据类型: {type(temperature_series)}")
print(f"索引类型: {type(temperature_series.index)}")6.3.3 智能的时间数据选择
# 创建一周的温度数据
dates = pd.date_range('2024-01-01', periods=7, freq='D')
temperatures = [15, 16, 14, 18, 17, 16, 19]
# 创建Series,用日期作为索引
temperature_series = pd.Series(temperatures, index=dates)
# 1. 按具体日期选择(就像翻到日记的某一页)
print("1月3日的温度:", temperature_series['2024-01-03'])
# 2. 按月份选择(就像查看整个月的日记)
print("
1月份的所有数据:")
print(temperature_series['2024-01'])
# 3. 按日期范围选择(就像查看一段时间内的日记)
print("
1月2日到1月5日的温度:")
print(temperature_series['2024-01-02':'2024-01-05'])
# 4. 按条件选择
cold_days = temperature_series[temperature_series < 16]
print("
温度低于16度的日子:")
print(cold_days)6.4 重采样:改变观察数据的时间尺度
6.4.1 什么是重采样?
想象你每天记录零花钱:
原始数据:每天记录(1月1日:10元,1月2日:15元,1月3日:12元…)
重采样:把每天的数据变成每周或每月的数据
重采样就是改变看数据的时间间隔:
降采样:从细时间变粗时间(每天→每周)
升采样:从粗时间变细时间(每周→每天)
6.4.2 降采样
1. 创建简单的每日零花钱记录
import pandas as pd
# 创建一周的每日零花钱记录
dates = pd.date_range('2024-01-01', periods=7, freq='D') # 7天,每天
allowance = [10, 15, 12, 8, 20, 5, 18] # 每天的零花钱
daily_allowance = pd.Series(allowance, index=dates)
print("每天的零花钱记录:")
print(daily_allowance)
"""
输出结果:
每天的零花钱记录:
2024-01-01 10
2024-01-02 15
2024-01-03 12
2024-01-04 8
2024-01-05 20
2024-01-06 5
2024-01-07 18
Freq: D, dtype: int64
"""2. 降采样:从每天到每周
import pandas as pd
# 把每天的数据变成每周的数据
weekly_total = daily_allowance.resample('W').sum() # 计算每周总和
weekly_avg = daily_allowance.resample('W').mean() # 计算每周平均
print("每周零花钱总和:")
print(weekly_total)
print("
每周零花钱平均:")
print(weekly_avg)
"""
每周零花钱总和:
2024-01-07 88
Freq: W-SUN, dtype: int64
每周零花钱平均:
2024-01-07 12.571429
Freq: W-SUN, dtype: float64
"""解释:
我们把7天的数据汇总成了一周的数据
resample('W')
.sum()
.mean()
3. 进一步的降采样的例子
import pandas as pd
# 创建两周的零花钱数据
dates_2weeks = pd.date_range('2024-01-01', periods=14, freq='D')
allowance_2weeks = [10, 15, 12, 8, 20, 5, 18, # 第一周
12, 17, 9, 11, 25, 6, 16] # 第二周
two_week_data = pd.Series(allowance_2weeks, index=dates_2weeks)
print("两周的每日零花钱:")
print(two_week_data)
"""
两周的每日零花钱:
2024-01-01 10
2024-01-02 15
2024-01-03 12
2024-01-04 8
2024-01-05 20
2024-01-06 5
2024-01-07 18
2024-01-08 12
2024-01-09 17
2024-01-10 9
2024-01-11 11
2024-01-12 25
2024-01-13 6
2024-01-14 16
Freq: D, dtype: int64
"""
# 按周重采样,计算每周总和
weekly_totals = two_week_data.resample('W').sum()
print("
每周零花钱总和:")
print(weekly_totals)
"""
每周零花钱总和:
2024-01-07 88
2024-01-14 96
Freq: W-SUN, dtype: int64
"""
# 按周重采样,计算每周平均
weekly_averages = two_week_data.resample('W').mean()
print("
每周零花钱平均:")
print(weekly_averages)
"""
每周零花钱平均:
2024-01-07 12.571429
2024-01-14 13.714286
Freq: W-SUN, dtype: float64
"""6.4.3 重采样resample()函数详解
1. resample() 函数基本用法
语法:
时间序列.resample(频率).聚合函数()
常用频率:
'D'
'W'
'M'
'Q'
'Y'
常用聚合函数:
.sum()
.mean()
.min()
.max()
.count()
2. 示例
一、重采样的聚合函数示例:
import pandas as pd
import numpy as np
# 创建简单的销售数据
dates = pd.date_range('2024-01-01', periods=10, freq='D')
sales = [100, 150, 80, 200, 120, 180, 90, 160, 140, 170]
sales_series = pd.Series(sales, index=dates)
print("原始销售数据:")
print(sales_series)
"""
原始销售数据:
2024-01-01 100
2024-01-02 150
2024-01-03 80
2024-01-04 200
2024-01-05 120
2024-01-06 180
2024-01-07 90
2024-01-08 160
2024-01-09 140
2024-01-10 170
Freq: D, dtype: int64
"""
# 不同的重采样方式
# 1. 默认方式(周结束在周日)
weekly_default = sales_series.resample('W').sum()
print("
按周重采样(默认,周日结束):")
print(weekly_default)
"""
按周重采样(默认,周日结束):
2024-01-07 920
2024-01-14 470
Freq: W-SUN, dtype: int64
"""
# 2. 指定周一开始
weekly_monday = sales_series.resample('W-MON').sum()
print("
按周重采样(周一开始):")
print(weekly_monday)
"""
按周重采样(周一开始):
2024-01-01 100
2024-01-08 980
2024-01-15 310
Freq: W-MON, dtype: int64
"""
# 3. 按月重采样(月末)
monthly_end = sales_series.resample('M').sum()
print("
按月重采样(月末):")
print(monthly_end)
"""
按月重采样(月末):
2024-01-31 1390
Freq: ME, dtype: int64
"""
# 4. 按月重采样(月初)
monthly_start = sales_series.resample('MS').sum()
print("
按月重采样(月初):")
print(monthly_start)
"""
按月重采样(月初):
2024-01-01 1390
Freq: MS, dtype: int64
"""二、多种聚合函数同时使用
import pandas as pd
import numpy as np
print("=== Pandas重采样多种聚合函数示例 ===
")
# 1. 创建数据
dates = pd.date_range('2024-01-01', periods=21, freq='D') # 3周数据
sales_data = np.random.randint(100, 300, size=21) # 随机生成销售额
# 创建Series
sales_series = pd.Series(sales_data, index=dates, name='daily_sales')
print("1. 原始每日销售额数据(Series):")
print(sales_series.head())
print(f"数据类型: {type(sales_series)}")
"""
=== Pandas重采样多种聚合函数示例 ===
1. 原始每日销售额数据(Series):
2024-01-01 186
2024-01-02 144
2024-01-03 135
2024-01-04 122
2024-01-05 239
Freq: D, Name: daily_sales, dtype: int32
数据类型: <class 'pandas.core.series.Series'>
"""
# 2. 将Series转换为DataFrame
sales_df = sales_series.to_frame(name='sales')
print("
2. 转换为DataFrame:")
print(sales_df.head())
print(f"数据类型: {type(sales_df)}")
"""
2. 转换为DataFrame:
sales
2024-01-01 186
2024-01-02 144
2024-01-03 135
2024-01-04 122
2024-01-05 239
数据类型: <class 'pandas.core.frame.DataFrame'>
"""
# 3. 多种聚合方法演示
print("
3. 多种聚合方法演示:")
# 方法A: Series使用列表格式
print("
A. Series使用列表格式:")
stats_series = sales_series.resample('W').agg(['sum', 'mean', 'min', 'max'])
print(stats_series)
"""
3. 多种聚合方法演示:
A. Series使用列表格式:
sum mean min max
2024-01-07 1179 168.428571 116 239
2024-01-14 1589 227.000000 171 283
2024-01-21 1335 190.714286 110 291
"""
# 方法B: DataFrame使用字典格式
print("
B. DataFrame使用字典格式:")
stats_df_dict = sales_df.resample('W').agg({
'sales': ['sum', 'mean', 'min', 'max']
})
print(stats_df_dict)
"""
B. DataFrame使用字典格式:
sales
sum mean min max
2024-01-07 1179 168.428571 116 239
2024-01-14 1589 227.000000 171 283
2024-01-21 1335 190.714286 110 291
"""
# 方法C: 使用命名聚合(更清晰)
print("
C. 使用命名聚合:")
stats_named = sales_df.resample('W').agg(
total_sales=('sales', 'sum'),
avg_sales=('sales', 'mean'),
min_sales=('sales', 'min'),
max_sales=('sales', 'max')
)
print(stats_named)
"""
C. 使用命名聚合:
total_sales avg_sales min_sales max_sales
2024-01-07 1179 168.428571 116 239
2024-01-14 1589 227.000000 171 283
2024-01-21 1335 190.714286 110 291
"""
# 4. 结果分析
print("
4. 结果分析:")
print(f"Series方法结果类型: {type(stats_series)}")
print(f"DataFrame字典方法结果类型: {type(stats_df_dict)}")
print(f"命名聚合方法结果类型: {type(stats_named)}")
"""
4. 结果分析:
Series方法结果类型: <class 'pandas.core.frame.DataFrame'>
DataFrame字典方法结果类型: <class 'pandas.core.frame.DataFrame'>
命名聚合方法结果类型: <class 'pandas.core.frame.DataFrame'>
"""关键总结
Series vs DataFrame:
DataFrame:可以使用字典格式
.agg({'列名': ['函数1', '函数2']})
.agg(['sum', 'mean', ...])
推荐做法:
对于简单的单列数据,使用Series和列表格式
对于多列数据或需要更清晰列名的情况,使用DataFrame
6.4.4 升采样
升采样就是把粗时间数据变成细时间数据,比如:
把每月数据变成每天数据
把每周数据变成每天数据
注意:升采样会产生缺失值,需要用某种方法填充。
import pandas as pd
# 创建月度零花钱数据(使用月初)
monthly_dates = pd.date_range('2024-01-01', periods=3, freq='MS') # 3个月初
monthly_allowance = [300, 350, 400] # 每月总零花钱
monthly_data = pd.Series(monthly_allowance, index=monthly_dates)
print("月度零花钱数据:")
print(monthly_data)
"""
月度零花钱数据:
2024-01-01 300
2024-02-01 350
2024-03-01 400
Freq: MS, dtype: int64
"""
# 升采样:从月到天
# 方法1:前向填充(用前一个月的值填充)
# 正确做法:先重采样,然后用ffill()填充
daily_forward = monthly_data.resample('D').ffill()
print("
升采样到每天(前向填充)- 只看1月份:")
print(daily_forward['2024-01'])
"""
升采样到每天(前向填充)- 只看1月份:
2024-01-01 300
2024-01-02 300
2024-01-03 300
2024-01-04 300
2024-01-05 300
2024-01-06 300
2024-01-07 300
2024-01-08 300
2024-01-09 300
2024-01-10 300
2024-01-11 300
2024-01-12 300
2024-01-13 300
2024-01-14 300
2024-01-15 300
2024-01-16 300
2024-01-17 300
2024-01-18 300
2024-01-19 300
2024-01-20 300
2024-01-21 300
2024-01-22 300
2024-01-23 300
2024-01-24 300
2024-01-25 300
2024-01-26 300
2024-01-27 300
2024-01-28 300
2024-01-29 300
2024-01-30 300
2024-01-31 300
Freq: D, dtype: int64
"""
# 方法2:用固定值填充缺失值
# 正确做法:先重采样,然后用fillna()填充
daily_filled = monthly_data.resample('D').asfreq().fillna(0)
print("
升采样到每天(用0填充缺失值)- 只看1月份:")
print(daily_filled['2024-01'].head(10)) # 只看前10天
"""
升采样到每天(用0填充缺失值)- 只看1月份:
2024-01-01 300.0
2024-01-02 0.0
2024-01-03 0.0
2024-01-04 0.0
2024-01-05 0.0
2024-01-06 0.0
2024-01-07 0.0
2024-01-08 0.0
2024-01-09 0.0
2024-01-10 0.0
Freq: D, dtype: float64
"""6.4.5 时间频率转换利器asfreq()函数详解
asfreq()
DataFrame.asfreq(freq, method=None, how=None, normalize=False, fill_value=None)
主要参数说明:
freq
method
how
normalize
fill_value
这个函数返回一个新的DataFrame,其索引符合指定的新频率。
1. 深入理解asfreq()的工作原理
要真正掌握asfreq()的使用,我们需要深入理解它的工作原理。asfreq()主要完成以下几个步骤:
检查原始DataFrame的索引是否为DatetimeIndex或PeriodIndex根据指定的新频率创建一个新的时间索引将原始数据重新索引到新的时间索引上根据参数设置处理缺失值和频率转换细节
示例1:从周频率转换为日频率
import pandas as pd
import numpy as np
# 创建周频率的示例数据
dates = pd.date_range('2023-01-01', periods=5, freq='W')
sales = pd.Series([1000, 1200, np.nan, 1500, 1800], index=dates)
df = pd.DataFrame({'Sales': sales})
print(df)
"""
Sales
2023-01-01 1000.0
2023-01-08 1200.0
2023-01-15 NaN
2023-01-22 1500.0
2023-01-29 1800.0
"""
# 现在,我们想将其转换为日频率数据:
daily_df = df.asfreq('D', fill_value=0)
print(daily_df)
"""
Sales
2023-01-01 1000.0
2023-01-02 0.0
2023-01-03 0.0
2023-01-04 0.0
2023-01-05 0.0
...
2023-01-29 1800.0
2023-01-30 0.0
2023-01-31 0.0
"""在上面这个例子中,
asfreq()
示例2: 处理不规则时间序列
import pandas as pd
import numpy as np
# 创建不规则时间序列数据
irregular_dates = pd.to_datetime(['2023-01-01', '2023-01-03', '2023-01-07', '2023-01-10'])
irregular_data = pd.Series([100, 150, 200, 180], index=irregular_dates)
irregular_df = pd.DataFrame({'Value': irregular_data})
print(irregular_df)
"""
Value
2023-01-01 100
2023-01-03 150
2023-01-07 200
2023-01-10 180
"""
# 使用asfreq()将其转换为规则的日频率数据:
regular_df = irregular_df.asfreq('D', method='ffill')
print(regular_df)
"""
Value
2023-01-01 100
2023-01-02 100
2023-01-03 150
2023-01-04 150
2023-01-05 150
2023-01-06 150
2023-01-07 200
2023-01-08 200
2023-01-09 200
2023-01-10 180
"""上面的例子使用了
method='ffill'
示例3: 频率上采样与下采样
asfreq()
import pandas as pd
import numpy as np
# 创建月度数据
monthly_data = pd.DataFrame({
'Revenue': [10000, 12000, 9500, 11500, 13000, 15000]
}, index=pd.date_range('2023-01-01', periods=6, freq='M'))
# 下采样到季度数据
quarterly_data = monthly_data.asfreq('Q', method='mean')
# 上采样到每日数据
daily_data = monthly_data.asfreq('D', fill_value=None)
print("Monthly data:
", monthly_data)
print("
Quarterly data:
", quarterly_data)
print("
Daily data (first 10 rows):
", daily_data.head(10))
"""
Monthly data:
Revenue
2023-01-31 10000
2023-02-28 12000
2023-03-31 9500
2023-04-30 11500
2023-05-31 13000
2023-06-30 15000
Quarterly data:
Revenue
2023-03-31 9500
2023-06-30 15000
Daily data (first 10 rows):
Revenue
2023-01-31 10000.0
2023-02-01 NaN
2023-02-02 NaN
2023-02-03 NaN
2023-02-04 NaN
2023-02-05 NaN
2023-02-06 NaN
2023-02-07 NaN
2023-02-08 NaN
2023-02-09 NaN
"""注意:asfreq()与resample()都可以用于频率转换, 区别如下:
1. asfreq()
2. resample()
resample()函数返回的是
聚合计算(降采样):
.resample('D').mean()
.resample('D').sum()
单纯改变频率(升采样):
.resample('D').asfreq()
示例比较:
import pandas as pd
import numpy as np
# 创建示例数据
dates = pd.date_range('2023-01-01', periods=10, freq='D')
data = pd.Series(np.random.randn(10), index=dates)
# 使用asfreq()
asfreq_result = data.asfreq('2D')
# 使用resample()
resample_result = data.resample('2D').mean()
print("asfreq result:
", asfreq_result)
print("
resample result:
", resample_result)
"""
asfreq result:
2023-01-01 0.244674
2023-01-03 1.369831
2023-01-05 -0.331232
2023-01-07 -0.380232
2023-01-09 -0.052973
Freq: 2D, dtype: float64
resample result:
2023-01-01 0.550307
2023-01-03 0.343799
2023-01-05 -0.228232
2023-01-07 -0.371683
2023-01-09 -0.183018
Freq: 2D, dtype: float64
"""© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











