
1 引言
Qwen LLM 系列的最新版本 Qwen3 在自然语言处理和多模态功能方面均实现了显著的突破。在继承前代产品优势的基础上,Qwen3 模型凭借更庞大的数据集、优化的架构以及精细的微调,能够高效应对复杂多样的推理、语言理解和生成任务。此外,通过扩展标记限制,Qwen3 能够生成更长且连贯的响应,并有效管理复杂的对话流程。
作为 Qwen 系列的最新力作,Qwen3 提供了全面的密集型和混合专家(MoE)模型阵容。基于广泛的训练,Qwen3 在推理、指令遵循、智能体功能以及多语言支持等多个方面均取得了重大进展,具体包括:
- 支持 100 多种语言和方言,在多语言教学跟踪和翻译方面表现出色。
- 在同一模型内,能够无缝切换思维模式(适用于复杂的逻辑推理、数学和编码任务)与非思维模式(用于高效的通用对话),从而针对不同任务实现性能优化。
- 在推理能力方面取得显著提升,在数学、代码生成和常识性逻辑推理等领域的表现优于前代 QwQ 模型(思维模式下)和 Qwen2.5 指令模型(非思维模式下)。
- 在人类偏好一致性方面表现出色,擅长创意写作、角色扮演、多轮对话和指令遵循,能够提供更自然、更具吸引力且身临其境的对话体验。
- 高级智能体功能使其在思考和非思考模式下均能与外部工具进行准确交互,在开源模型中针对复杂智能体驱动任务实现了最先进的成果。
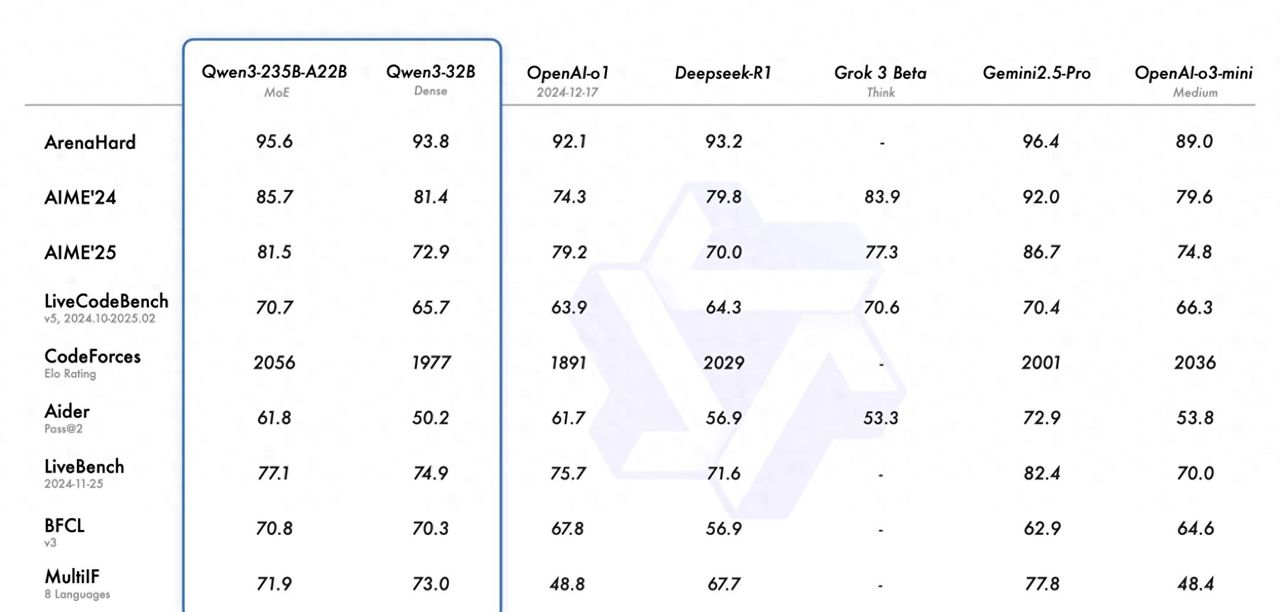
在编码、数学和通用功能等基准测试中,Qwen3-235B-A22B 展现出了极具竞争力的性能,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等其他领先型号不相上下。与此同时,较小的 MoE 模型 Qwen3-30B-A3B 虽然激活参数数量仅为前者的十分之一,却在性能上超越了 QwQ-32B。即使是紧凑的 Qwen3-4B,其性能也与更大的 Qwen2.5-72B-Instruction 模型相当。
Qwen3-235B-A22B

Qwen3-30B-A3B
Qwen3-235B-A22B 是一款大型模型,拥有 2350 亿个总参数和 220 亿个激活参数;而 Qwen3-30B-A3B 则是一款较小的 MoE 模型,拥有 300 亿个总参数和 30 亿个激活参数。此外,六种密集型模型(Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B)已开放权重,并在 Apache 2.0 许可下发布。
Qwen3-30B-A3B 等后训练模型及其预训练版本(例如 Qwen3-30B-A3B-Base)现已在 Hugging Face、ModelScope 和 Kaggle 等平台上提供。对于部署,提议使用 SGLang 和 vLLM 等框架;对于本地使用,强烈推荐使用 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。这些选项使用户能够轻松地将 Qwen3 集成到其跨研究、开发和生产环境的工作流程中。
我们坚信,Qwen3 的发布和开源将有力推动大型基础模型研发的重大进展。我们的使命是让全球的研究人员、开发人员和组织能够利用这些最先进的模型,创造出更具创新性的解决方案。
您可以通过 Qwen Chat Web(chat.qwen.ai)和 Qwen 移动应用程序(Qwen Chat APP)亲身体验 Qwen3 的强劲功能!
2 主要特点
2.1 混合思维模式
Qwen3 模型通过支持两种不同的模式,引入了一种灵活的问题解决方法:
- 思维模式:在这种模式下,模型会进行逐步推理后再提供答案,适合需要深入分析的复杂问题。
- 非思维模式:此模式提供快速、近乎即时的响应,适用于简单任务,其中速度比详细推理更重大。
这种灵活性使用户能够根据特定任务调整模型的“思考”程度。复杂的挑战可以通过扩展推理来解决,而简单的查询可以迅速得到回应。
重大的是,这两种模式的集成显著提升了模型管理思维预算的能力。Qwen3 的性能与分配的计算推理预算直接相关,呈现出可扩展且平滑的性能提升。这种设计使用户能够更轻松地为特定任务配置预算,从而在成本效率和推理质量之间实现最佳平衡。

2.2 多语言支持
Qwen3 模型支持 119 种语言和方言,极大地扩展了其在全球应用程序中的可用性。这种广泛的多语言功能使世界各地的用户能够在不同的语言和文化背景下充分利用 Qwen3 的潜力。
语系和覆盖范围:
|
语系 |
语言和方言 |
|
印欧语系 |
英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、博克马尔语挪威语、新诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克西坦语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔希语、阿瓦迪语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克阿尔巴尼亚语、林堡语、达里语、南非荷兰语、马其顿语、僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
|
汉藏语系 |
中文(简体、繁体、粤语)、缅甸语 |
|
亚非语系 |
阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、Ta’izzi-Adeni、突尼斯语)、希伯来语、马耳他语 |
|
南岛语系 |
印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班贾尔语、邦阿西楠语、伊洛科语、瓦赖语(菲律宾) |
|
德拉威语系 |
泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
|
突厥语系 |
土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
|
泰侍岱语系 |
泰语、老挝语 |
|
乌拉尔语系 |
芬兰语、爱沙尼亚语、匈牙利语 |
|
南亚语系 |
越南语、高棉语 |
|
其他 |
日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮亚门托语、Kabuverdianu、Tok Pisin、斯瓦希里语 |
2.3 改善的智能体功能
Qwen3 模型在编码和智能体驱动任务方面进行了显著优化。此外,对模型上下文协议(MCP)的支持也得到了进一步加强。
以下是一些示例,展示了 Qwen3 模型如何进行推理、与其环境交互以及在复杂的智能体工作流中执行任务。
3 预训练(Pre-training)阶段
预训练阶段指的是在模型开始针对特定任务或应用进行微调(fine-tuning)之前所进行的初始训练阶段。预训练阶段对于模型的性能和能力至关重大,由于它为模型提供了处理语言和知识的基础能力。
预训练是大语言模型开发过程中的基础阶段,它为模型提供了处理和理解语言所需的核心能力。预训练的效果直接影响到模型在后续微调和其他任务上的表现。
3.1 预训练阶段的关键方面
以下是预训练阶段的一些关键方面:
1)大规模数据训练:
- 预训练涉及在大量多样化的数据集上训练模型,这些数据集可能包括文本、代码、对话、文章等多种形式的内容。
- 这一阶段的目标是让模型学习语言的基本结构、模式和概念,以及广泛的世界知识。
2)通用表明学习:
- 预训练的模型学习捕捉语言的通用表明,这有助于模型理解和生成自然语言。
- 这些表明可以用于各种下游任务,如文本分类、情感分析、机器翻译等。
3)无监督学习:
- 预训练一般采用无监督学习方法,这意味着模型在没有明确标签或注释的情况下学习数据中的模式。
- 模型通过预测下一个词、掩码语言模型(Masked Language Modeling,MLM)等技术来学习语言结构。
4)计算资源密集:
- 预训练需要大量的计算资源,包括高性能的GPU或TPU。
- 这一阶段可能需要数天、数周甚至数月的时间,取决于模型的大小和数据集的规模。
5)模型架构设计:
- 在预训练之前,需要设计和选择模型的架构,包括层数、隐藏单元数、注意力机制等。
- 架构的选择会影响模型的容量、效率和最终的性能。
6)损失函数和优化:
- 预训练使用特定的损失函数来衡量模型预测和实际输出之间的差异,并指导模型的学习过程。
- 优化算法(如Adam、SGD等)用于更新模型权重,以最小化损失函数。
7)模型规模:
- 预训练的模型规模可以从数百万到数千亿参数不等,更大的模型一般能够捕获获更丰富的语言表明,但也更难以训练和部署。
8)伦理和偏见:
- 在预训练过程中,需要注意数据集的质量和多样性,以减少模型学习到的潜在偏见和不当内容。
- 需要确保模型不会复制或放大训练数据中的歧视性或有害信息。
3.2 Qwen3 的预训练
与 Qwen2.5 相比,Qwen3 的预训练数据集显著扩展。Qwen2.5 使用 18 万亿个标记进行训练,而 Qwen3 使用的数据量几乎是其两倍,达到 36 万亿个标记,涵盖 119 种语言和方言。
为了构建这个大规模数据集,阿里不仅从网页获取数据,还从类似 PDF 的文档中提取数据。使用 Qwen2.5-VL 从文档中提取文本,同时利用 Qwen2.5 提高提取内容的质量。为了丰富数据聚焦的数学和编码示例,阿里使用 Qwen2.5-Math 和 Qwen2.5-Coder 生成了合成数据,包括教科书、问答对和代码片段。
预训练过程分为三个阶段:
- 第1阶段(S1):模型在超过 30 万亿个标记上进行预训练,上下文长度为 4K 标记,建立了强劲的基本语言技能和一般知识。
- 第2阶段(S2):通过增加知识密集型内容的比例,例如 STEM 主题、编码挑战和推理任务,数据集得到进一步细化。随后,模型在另外 5 万亿个标记上进行预训练。
- 最后阶段:使用高质量的长上下文数据,将模型的上下文窗口扩展到 32K 标记,确保其能够有效处理更长的输入。
得益于模型架构的改善、扩展的训练数据和更高效的训练技术,Qwen3 密集基础模型目前与大型 Qwen2.5 基础模型的性能相当,在某些情况下甚至超过了它们。
例如,
Qwen3-1.7B/4B/8B/14B/32B-Base 模型的性能分别与
Qwen2.5-3B/7B/14B/32B/72B-Base 模型相当。特别是,Qwen3 密集基础模型在 STEM、编码和推理任务方面显示出优于 Qwen2.5 模型的显著优势。
同时,Qwen3-MoE 基础模型实现了与 Qwen2.5 密集型模型相当的性能,而仅使用 10% 的活动参数,从而显著节省了训练和推理成本。
4 训练后(Post-training)阶段
训练后阶段指的是模型在完成初始训练阶段后所进行的各种活动和过程。这些活动可以包括模型的评估、部署、微调(fine-tuning)、持续学习、模型监控和更新等。
训练后阶段是模型生命周期中至关重大的一部分,它确保模型不仅在训练期间表现良好,而且在实际应用中也能持续提供高质量的服务。
4.1 训练后阶段的关键活动
以下是训练后阶段可能涉及的一些关键活动:
1)评估(Evaluation):
- 在独立测试集上评估模型的性能,以确保模型在看不见的数据上也能表现良好。
- 进行错误分析和性能调优,以确定模型的强项和弱项。
2)微调(Fine-tuning):
- 针对特定任务或领域,使用较小的数据集对模型进行额外训练,以提高其在该任务或领域的表现。
- 可以调整模型以适应特定的行业术语、风格或数据分布。
3)部署(Deployment):
- 将模型集成到应用程序、服务或生产环境中,使其能够处理实时请求或批量任务。
- 确保模型在部署环境中的稳定性、可扩展性和安全性。
4)监控(Monitoring):
- 跟踪模型在实际使用中的表现,包括准确性、延迟、资源使用情况等。
- 检测模型在实际应用中可能出现的任何性能下降或异常行为。
5)更新和维护(Updates and Maintenance):
- 定期更新模型以包含最新的数据、知识和改善。
- 修复可能在实际使用中发现的错误或漏洞。
6)持续学习(Continual Learning):
- 使模型能够持续从新数据中学习,以适应不断变化的环境和数据分布。
- 有助于模型长期保持相关性和有效性。
7)知识蒸馏(Knowledge Distillation):
- 将大型复杂模型的知识转移到较小的模型中,以提高效率和降低资源消耗。
- 常用于将大型模型的知识迁移到轻量级模型中。
8)伦理和合规性(Ethics and Compliance):
- 确保模型的使用符合伦理标准和法律法规。
- 定期评估模型的决策过程和输出,以识别和减轻潜在的偏见和风险。
混合模型训练管道
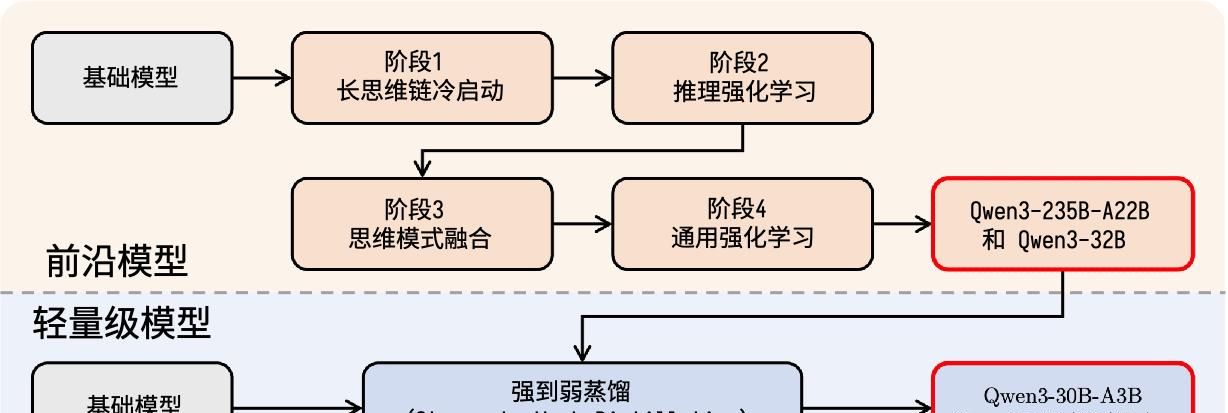
4.2 Qwen3 的训练后阶段:混合模型训练管道
为了开发一个能够进行分步推理和快速响应生成的混合模型,阿里巴巴开发团队设计了一个四阶段的训练管道:
- 阶段1:长思维链(CoT)冷启动:在初始阶段,模型在涵盖数学、编码、逻辑推理和 STEM 挑战等任务的各种长 CoT 数据集上进行微调。这种训练确立了模型的基础推理能力。
- 阶段2:基于推理的强化学习(RL):第二阶段的重点是通过在强化学习期间扩展计算资源和应用基于规则的奖励机制,增强模型的探索和利用能力。
- 阶段3:思维模式融合:在这个阶段,非思考(快速反应)能力被整合到推理模型中。这是通过对长 CoT 数据和标准指令调整数据集的混合进行微调来实现的,这些数据集由第 2 阶段的增强模型生成。这种融合实现了深度推理和快速响应模式之间的无缝切换。
- 阶段4:通用强化学习(General RL):最后,强化学习被应用于 20 多个通用域任务,进一步提高了模型的整体能力并减轻了不良行为。这些任务包括指令遵循、格式遵守、智能体行为等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














Qwen3突破真不少呀👏
收藏了,感谢分享