近日,Yuliang-Liu团队在GitHub上开源了一款轻量级基于LLM的文档解析模型:MonkeyOCR!
支持高效地将非结构化文档内容转换为结构化信息。基于准确的布局分机,显著提升文档解析的准确性和效率。

主要功能:
文档解析与结构化:将各种格式的文档(如PDF、图像等)中的非结构化内容(包括文本、表格、公式、图像等)转换为结构化的机器可读信息。
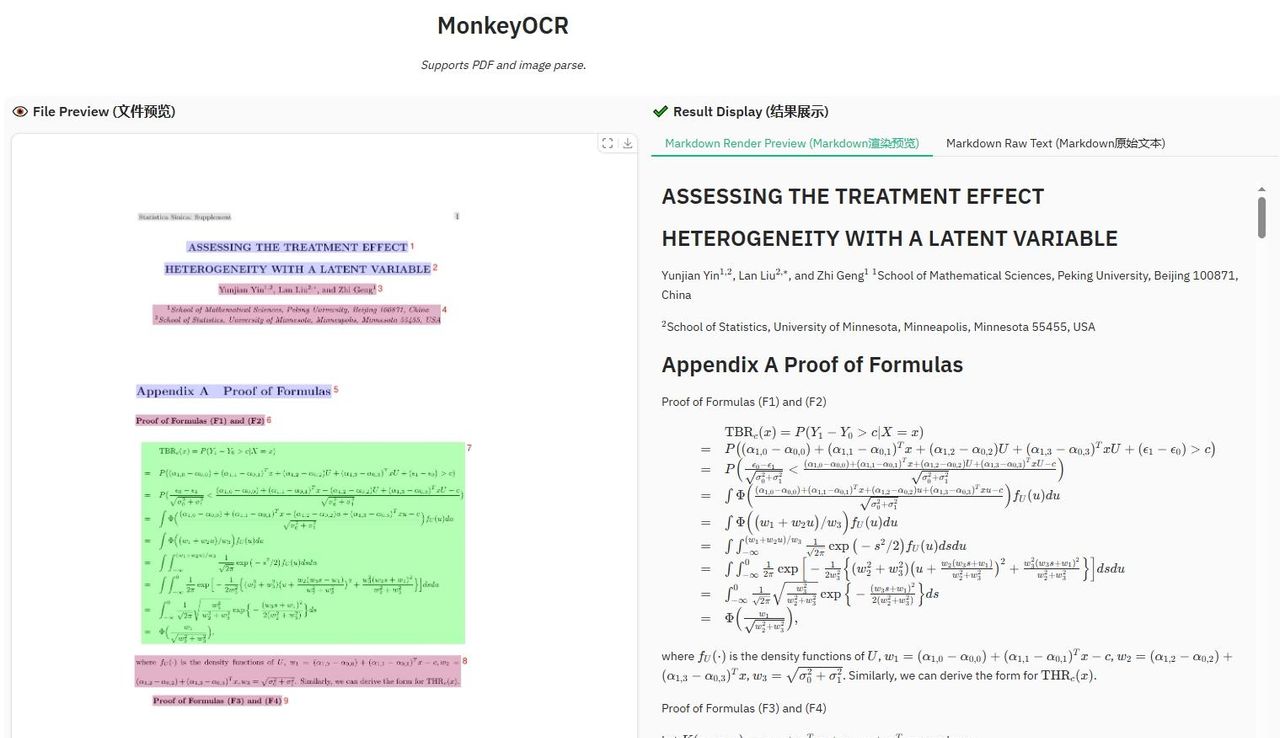
多语言支持:支持多种语言,包括中文和英文。
高效处理复杂文档:在处理复杂文档(如包含公式、表格、多栏布局等)时表现出色。
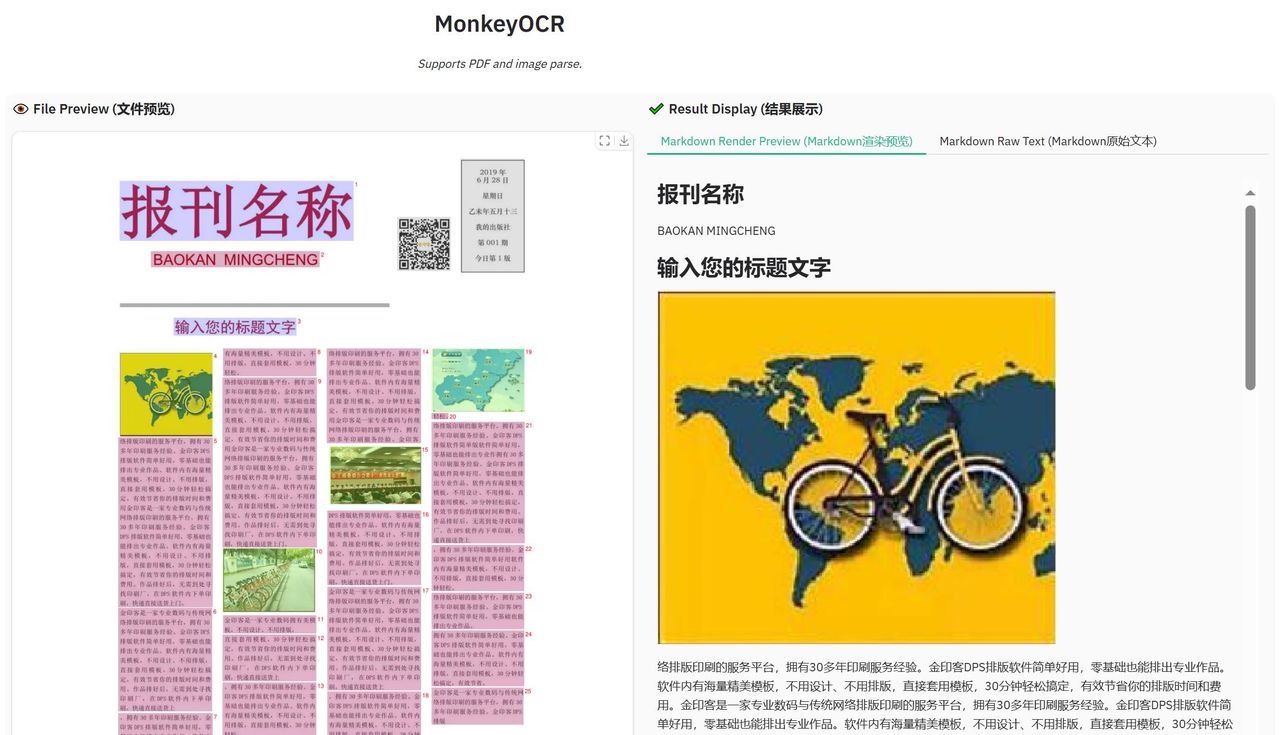
快速多页文档处理:高效处理多页文档,处理速度达到每秒0.84页,显著优于其他工具(如MinerU每秒0.65页,Qwen2.5-VL-7B每秒0.12页)。
灵活的部署与扩展:支持在单个NVIDIA3090GPU上高效部署,满足不同规模的需求。
技术原理:
结构-识别-关系(SRR)三元组范式:基于YOLO的文档布局检测器,识别文档中的关键元素(如文本块、表格、公式、图像等)的位置和类别,确保高精度。
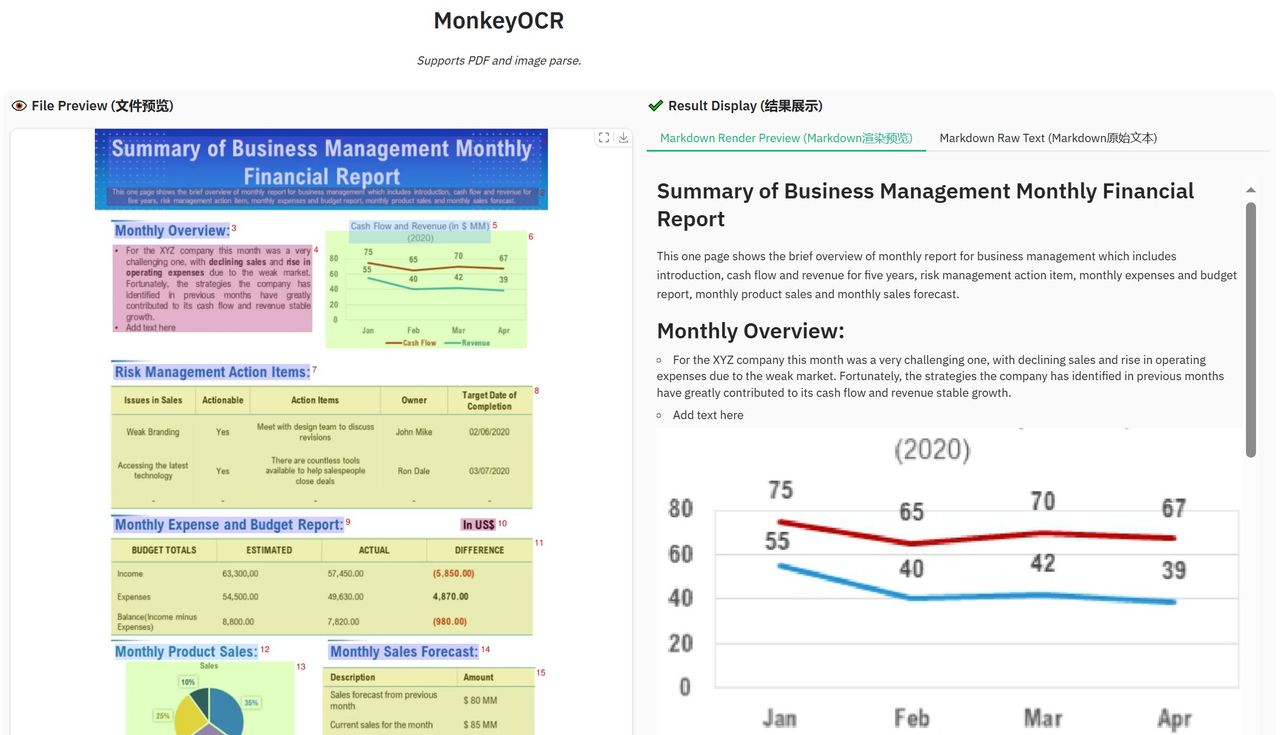
MonkeyDoc数据集:MonkeyDoc是迄今为止最全面的文档解析数据集,包含390万个实例,涵盖中文和英文的十多种文档类型。

模型优化与部署:用AdamW优化器和余弦学习率调度,结合大规模数据集进行训练,确保模型在精度和效率之间的平衡。
GitHub:https://github.com/Yuliang-Liu/MonkeyOCR
在线体验:
http://vlrlabmonkey.xyz:7685/
#AI开源项目推荐##github##AI技术##开源OCR#OCR模型
© 版权声明
文章版权归作者所有,未经允许请勿转载。











收藏了,感谢分享