1234567891011121314151617
1234567891011121314151617
Flink与Hadoop集成:大数据生态的无缝对接



目录
1. 引言:大数据处理的范式演进与融合趋势2. Flink与Hadoop生态系统深度剖析
2.1 Hadoop生态系统:大数据的基石2.2 Flink:新一代流处理与批处理引擎2.3 技术融合的必然性:为什么选择Flink+Hadoop架构 3. 集成架构设计:原理与核心组件交互
3.1 整体架构概览:分层视角3.2 核心集成点解析3.3 数据流通模型:从批处理到流批一体3.4 资源协调机制:YARN与Flink的协同工作 4. 环境搭建与配置:从零开始的集成之路
4.1 环境规划与组件版本选择4.2 硬件与操作系统要求4.3 详细部署步骤:Hadoop集群搭建4.4 Flink集群部署与Hadoop集成配置4.5 关键配置文件详解4.6 集成验证与环境测试 5. Flink on YARN:资源管理深度整合
5.1 YARN架构与Flink部署模型解析5.2 Session模式:共享集群资源5.3 Per-Job模式:作业隔离与资源优化5.4 Application模式:应用级部署新范式5.5 三种部署模式的对比与适用场景5.6 资源配置最佳实践5.7 高可用部署与故障自动恢复 6. Flink与HDFS集成:分布式存储的高效交互
6.1 HDFS集成原理与架构6.2 Flink FileSystem接口与HDFS实现6.3 批处理场景:高效读取HDFS文件6.4 流处理场景:监控HDFS目录与实时数据摄入6.5 高级特性:HDFS作为状态后端存储6.6 读写性能优化策略 7. Flink与Hive集成:数据仓库的无缝对接
7.1 Hive集成架构与原理7.2 环境准备与依赖配置7.3 Flink SQL查询Hive表实战7.4 Hive作为Flink的数据源与数据汇7.5 实时数仓构建:Flink+Hive最佳实践7.6 分区表与分桶表操作7.7 元数据一致性与事务支持 8. Flink与HBase集成:实时NoSQL数据交互
8.1 HBase数据模型与访问模式8.2 Flink-HBase连接器实现原理8.3 读取HBase数据:Scan与Get操作8.4 写入HBase数据:Put与Delete操作8.5 案例:构建实时特征存储服务8.6 性能优化与连接池配置 9. 项目实战:构建端到端实时数据处理平台
9.1 项目背景与架构设计9.2 数据流程与组件交互9.3 环境准备与配置详解9.4 核心模块实现9.5 完整代码实现与详细解读9.6 部署与运行验证9.7 监控与运维实践 10. 性能优化与调优指南
10.1 资源配置优化策略10.2 数据处理性能调优10.3 网络与I/O优化10.4 状态管理优化10.5 监控指标与性能瓶颈识别10.6 调优案例分析 11. 生产环境最佳实践与案例分析
11.1 版本选型与兼容性策略11.2 高可用架构设计11.3 数据一致性保障措施11.4 容灾备份与恢复策略11.5 典型企业应用案例解析 12. 常见问题诊断与解决方案
12.1 集成配置问题排查12.2 性能问题诊断流程12.3 资源竞争与调度问题12.4 数据一致性与完整性问题12.5 社区常见问题与官方解决方案 13. 未来趋势与技术演进
13.1 Flink与Hadoop生态的融合方向13.2 云原生环境下的新挑战与机遇13.3 实时湖仓一体架构展望13.4 AI与大数据融合:Flink+Hadoop在机器学习中的应用 14. 总结与展望附录:工具与资源推荐
1. 引言:大数据处理的范式演进与融合趋势
在数字经济时代,数据已成为企业最核心的战略资产之一。根据IDC预测,到2025年,全球数据圈将增长至175ZB,其中80%以上将是非结构化数据,且实时数据占比将持续提升。面对爆炸式增长的数据量和多样化的数据处理需求,单一技术体系已难以满足企业的全面需求。
大数据技术栈的演进经历了几个关键阶段:
批处理时代(2006-2012):以Hadoop MapReduce为代表,主要解决海量数据的离线处理问题。其核心思想是”分而治之”,将大规模计算任务分解为小任务并行处理。
交互式查询时代(2011-2015):随着Hive、Impala、Presto等技术的出现,用户开始追求更快的查询响应时间,SQL-on-Hadoop技术蓬勃发展。
流处理时代(2013-至今):随着实时数据价值的凸显,Storm、Spark Streaming、Flink等流处理框架相继涌现,实时数据处理能力成为企业竞争力的关键指标。
流批一体时代(2018-至今):单一的批处理或流处理已无法满足复杂场景需求,Flink、Spark等框架开始向统一批流处理方向发展,实现”一次开发,处处运行”。
在这一演进过程中,Hadoop生态系统作为大数据技术的奠基者,构建了完整的数据存储、处理和管理体系;而Flink作为新一代计算引擎,以其卓越的流处理能力和低延迟特性,逐渐成为实时数据处理的首选。将Flink与Hadoop生态无缝集成,不仅能够充分利用Hadoop成熟稳定的存储和资源管理能力,还能发挥Flink强大的实时计算能力,形成”1+1>2″的技术协同效应。
本文将深入探讨Flink与Hadoop生态系统集成的方方面面,从基础原理到架构设计,从环境搭建到实战案例,从性能优化到生产实践,为读者提供一份全面、系统、深入的技术指南。无论你是大数据初学者还是资深架构师,都能从本文中找到有价值的信息和实践指导。
2. Flink与Hadoop生态系统深度剖析
2.1 Hadoop生态系统:大数据的基石
Hadoop生态系统是一个庞大而复杂的技术体系,自2006年由Apache基金会发起以来,已发展成为大数据处理的事实标准。它不仅提供了分布式存储和计算能力,还构建了一套完整的数据处理流水线,涵盖数据采集、存储、处理、分析、挖掘等各个环节。
Hadoop生态系统的核心组件可分为以下几类:
1. 分布式存储组件
HDFS(Hadoop Distributed File System):Hadoop的分布式文件系统,设计用于在 commodity hardware 上存储超大文件,具有高容错性、高吞吐量的特点。HDFS采用主从架构,包含一个NameNode和多个DataNode,支持数据的冗余存储(默认3副本)以保证可靠性。
HDFS的关键特性:
适合存储大文件(GB/TB级别)一次写入,多次读取(WORM)模型块(Block)级别的存储和管理(Hadoop 3.x默认块大小为128MB)跨机架、跨节点的数据副本策略
HBase:基于HDFS的分布式NoSQL列族数据库,提供实时随机读写能力,适合存储非结构化和半结构化数据。HBase采用面向列的存储方式,支持海量数据的高并发读写,是实时数据存储的理想选择。
2. 资源管理与调度组件
YARN(Yet Another Resource Negotiator):Hadoop的集群资源管理系统,负责协调集群中的计算资源(CPU、内存等),并为应用程序分配资源。YARN采用双层调度架构,包含一个ResourceManager和多个NodeManager,以及为每个应用程序分配的ApplicationMaster。
YARN的核心优势:
资源隔离与多租户支持灵活的调度策略(FIFO、Capacity Scheduler、Fair Scheduler)动态资源分配与多种计算框架兼容(MapReduce、Spark、Flink等)
3. 数据处理组件
MapReduce:Hadoop的分布式计算框架,基于”Map”和”Reduce”两个核心操作实现并行计算。尽管MapReduce在性能上已被Spark、Flink等新一代框架超越,但其思想深刻影响了后续计算框架的设计。
Hive:基于Hadoop的数据仓库工具,提供类SQL查询语言(HQL),将SQL语句转换为MapReduce或Tez作业执行。Hive专注于批处理分析,支持复杂的数据分析、聚合和报表生成。
Pig:面向数据流的脚本语言,用于描述数据转换过程,适合非结构化和半结构化数据的处理。Pig Latin脚本会被转换为MapReduce作业执行。
4. 数据集成与传输组件
Sqoop:用于在关系型数据库和Hadoop之间高效传输数据的工具,支持批量数据导入导出。
Flume:分布式日志收集系统,用于从多个数据源收集、聚合和传输大量日志数据到HDFS或其他存储系统。
Kafka:高吞吐量的分布式发布-订阅消息系统,最初由LinkedIn开发,现已成为流数据管道的核心组件,广泛用于实时数据采集和传输。
5. 协调与管理组件
ZooKeeper:分布式协调服务,提供分布式锁、配置管理、命名服务等功能,保证分布式系统的一致性和可靠性。
Oozie:Hadoop工作流调度系统,用于定义、调度和监控Hadoop作业流程。
Ambari:Hadoop集群管理工具,提供Web界面用于集群部署、配置、监控和管理。
Hadoop生态系统的架构如图所示:
2.2 Flink:新一代流处理与批处理引擎
Apache Flink是一个开源的分布式流处理和批处理框架,由柏林工业大学的研究项目发展而来,于2014年进入Apache孵化器,2015年成为Apache顶级项目。Flink以其卓越的流处理性能、低延迟和高吞吐量特性,迅速成为实时数据处理领域的佼佼者。
Flink的核心架构
Flink采用分层架构设计,从下到上包括:
部署层:支持在各种环境中部署Flink集群,包括 standalone、YARN、Mesos、Kubernetes,以及云平台(AWS、GCP、Azure等)。
核心层:包含Flink的分布式执行引擎、内存管理和检查点机制,是Flink的核心竞争力所在。
API层:提供面向开发者的编程接口,包括:
低级别的ProcessFunction API核心的DataStream API(流处理)和DataSet API(批处理)高级别的SQL & Table API
库与应用层:提供面向特定场景的高级库,如Flink ML(机器学习)、Flink Graph(图处理)、Flink CEP(复杂事件处理)等。
Flink的关键技术特性
真正的流处理模型:Flink基于无限数据流模型设计,将批处理视为流处理的一种特殊情况(有界流)。这与Spark Streaming的微批处理模式形成鲜明对比,带来更低的延迟和更好的实时性。
基于状态的计算:Flink提供强大的状态管理能力,支持多种状态后端(MemoryStateBackend、FsStateBackend、RocksDBStateBackend),能够高效存储和访问计算过程中的状态数据。
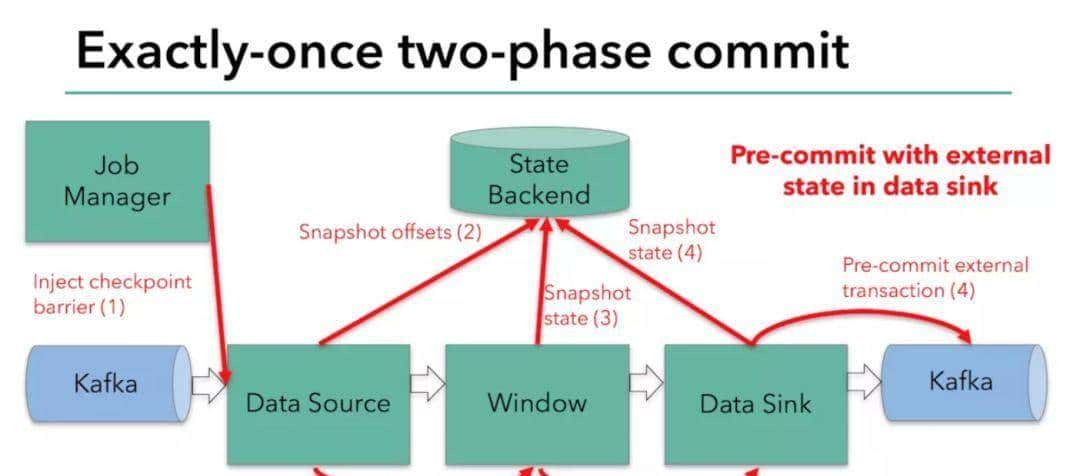
精确一次(Exactly-Once)语义:通过实现Chandy-Lamport算法的变体(异步屏障快照),Flink能够在故障恢复时保证数据处理的精确一次语义,确保数据一致性。
事件时间(Event Time)处理:支持基于事件产生时间的窗口计算,能够处理乱序事件和延迟数据,通过Watermark机制追踪事件时间进度。
强大的窗口机制:支持多种窗口类型,包括滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window)以及自定义窗口,满足复杂的时间序列分析需求。
高效的内存管理:Flink实现了自己的内存管理机制,能够高效利用堆内和堆外内存,减少GC压力,提高系统稳定性和性能。
灵活的部署和集成能力:可部署在各种资源管理器上(YARN、Kubernetes等),并能与Hadoop生态系统的各种组件无缝集成。
Flink架构组件
Flink集群由两类进程组成:
JobManager(JM):负责作业的调度和协调,包含:
Dispatcher:接收作业提交,启动JobMasterJobMaster:每个作业一个,负责作业的执行计划和资源申请ResourceManager:负责资源申请和管理( standalone模式下)
TaskManager(TM):负责实际的计算任务执行,包含多个TaskSlot,每个Slot可运行一个或多个子任务(Subtask)。
Flink执行流程如图所示:
2.3 技术融合的必然性:为什么选择Flink+Hadoop架构
在大数据技术百花齐放的今天,为什么我们需要将Flink与Hadoop生态系统集成?这种技术融合不是简单的”新框架取代旧框架”,而是基于各自优势的战略互补。以下从多个维度分析Flink与Hadoop集成的必然性和价值:
1. 存储与计算分离的最佳实践
Hadoop生态提供了成熟、稳定、可扩展的分布式存储解决方案(HDFS、HBase),而Flink专注于提供高效的计算能力。将两者结合,实现了”存储与计算分离”的现代架构理念:
HDFS提供高可靠、高吞吐的持久化存储HBase提供实时随机读写能力Flink提供高效的批流一体化计算引擎
这种分离架构带来多重优势:
存储资源和计算资源可独立扩展,优化资源利用率数据可以被多个计算框架共享访问简化数据管理和数据治理降低总体拥有成本(TCO)
2. 资源管理的统一与优化
YARN作为Hadoop生态的资源管理器,能够为Flink提供统一的资源调度和管理:
资源利用率最大化:YARN的资源调度机制可以根据作业需求动态分配资源,避免资源浪费多租户隔离:不同团队和应用可以共享集群资源,同时保持隔离统一监控与运维:通过YARN可以统一监控和管理所有运行在集群上的计算框架灵活的调度策略:可根据业务需求选择合适的调度策略(Capacity、Fair等)
3. 数据处理全链路覆盖
现代数据处理需求日益复杂,单一计算模型已无法满足所有场景。Flink与Hadoop的集成,能够覆盖从数据采集到最终分析的全链路需求:
数据采集:通过Flume、Kafka等组件采集数据数据存储:存储在HDFS、HBase等系统中实时处理:使用Flink进行低延迟流处理批处理分析:使用Flink或Hive进行批量数据处理数据服务:通过HBase提供实时数据服务
4. 投资保护与技术演进
对于已投入Hadoop生态的企业,引入Flink无需替换现有基础设施,而是基于现有投资进行增强:
保护已有硬件和软件投资利用现有运维团队的Hadoop技能平滑过渡到实时数据处理架构逐步演进而非颠覆性变革
5. 性能与功能的平衡
Flink与Hadoop的组合在性能和功能上实现了卓越平衡:
低延迟与高吞吐并存:Flink的流处理能力提供毫秒级延迟,同时保持高吞吐量丰富的API生态:从低级别的ProcessFunction到高级别的SQL,满足不同场景需求完整的生态系统:Hadoop生态提供了数据处理所需的各种工具和服务企业级可靠性:两者都经过了大规模生产环境验证,具备企业级稳定性和可靠性
6. 典型应用场景
Flink与Hadoop集成架构特别适合以下场景:
实时ETL:从Kafka等源系统实时抽取数据,经过Flink处理后写入HDFS/Hive/HBase实时监控与告警:实时分析系统日志和指标数据,及时发现异常并告警实时报表:基于实时数据生成业务报表,支持决策分析个性化推荐:实时分析用户行为,生成个性化推荐结果欺诈检测:实时分析交易数据,识别欺诈行为流批一体数据仓库:构建同时支持实时和批量分析的数据仓库
通过Flink与Hadoop的深度集成,企业能够构建一个统一、高效、灵活的数据处理平台,同时满足实时和批量数据处理需求,释放数据的全部价值。
3. 集成架构设计:原理与核心组件交互
3.1 整体架构概览:分层视角
Flink与Hadoop的集成是一个多层次、多维度的系统工程,涉及计算、存储、资源管理等多个层面。从分层视角来看,整体架构可分为以下几层:
1. 基础设施层
物理硬件:服务器、网络设备、存储设备操作系统:Linux(推荐CentOS/Ubuntu)基础软件:Java环境、SSH、NTP等
2. 存储层
HDFS:分布式文件系统,存储大规模数据集HBase:分布式NoSQL数据库,提供实时随机访问其他存储系统:Kafka(流数据存储)、Alluxio(分布式缓存)等
3. 资源管理层
YARN:集群资源管理和调度ZooKeeper:分布式协调服务,提供配置管理、命名服务、分布式锁等容器化技术:Docker(可选),提供环境隔离
4. 计算处理层
Flink:流处理和批处理引擎MapReduce/Hive:传统批处理(用于历史数据处理或遗留系统)
5. 数据接入层
Kafka:高吞吐量消息系统,连接数据源和处理系统Flume:日志收集系统Sqoop:关系型数据库数据导入导出
6. 应用与接口层
Flink API:DataStream API、DataSet API、Table API/SQL外部系统接口:JDBC、REST API等可视化工具:Grafana、Superset等
整体架构如图所示:
3.2 核心集成点解析
Flink与Hadoop生态系统的集成通过多个关键集成点实现,这些集成点共同构成了完整的技术链路:
1. Flink on YARN集成
集成目标:在YARN上部署和运行Flink集群,利用YARN的资源管理能力核心组件:Flink YARN客户端、YARN ResourceManager、NodeManager集成方式:通过YARN的ApplicationMaster机制,Flink可以作为YARN应用运行关键特性:资源动态分配、多种部署模式、高可用性支持
2. Flink与HDFS集成
集成目标:Flink能够读写HDFS上的数据,并利用HDFS存储检查点和状态数据核心组件:Flink FileSystem接口、Hadoop FileSystem实现集成方式:通过Flink的FileSystem抽象,适配HDFS的文件系统接口关键特性:支持多种文件格式、高效并行读写、作为状态后端存储
3. Flink与Hive集成
集成目标:Flink能够查询Hive表数据,将处理结果写入Hive,并共享Hive元数据核心组件:Flink Hive Catalog、Hive Metastore、Hive SerDe集成方式:通过实现Hive Metastore客户端,访问Hive元数据;通过Hive SerDe解析数据格式关键特性:支持Flink SQL查询Hive表、批流写入Hive、分区表操作
4. Flink与HBase集成
集成目标:Flink能够高效读写HBase中的数据核心组件:Flink HBase Connector、HBase Client、HBase Coprocessor集成方式:基于HBase Client API实现Flink数据源和数据汇关键特性:支持Put/Get/Scan/Delete操作、批量写入优化、连接池管理
5. Flink与ZooKeeper集成
集成目标:利用ZooKeeper实现Flink集群的高可用和协调服务核心组件:Flink HA Services、ZooKeeper Curator客户端集成方式:通过Curator客户端访问ZooKeeper,存储集群元数据和状态信息关键特性:JobManager高可用、元数据持久化、分布式锁
6. Flink与Kafka集成
集成目标:实现Flink与Kafka的高效数据交互核心组件:Flink Kafka Connector、Kafka Producer/Consumer API集成方式:基于Kafka Client API实现Flink数据源和数据汇关键特性:Exactly-Once语义支持、分区发现、动态topic订阅
这些集成点相互协同,共同构成了Flink与Hadoop生态系统的完整集成架构。在实际应用中,可以根据业务需求选择相应的集成点,构建定制化的数据处理解决方案。
3.3 数据流通模型:从批处理到流批一体
数据流通是Flink与Hadoop集成架构的核心,决定了数据如何在各个组件之间流动和处理。随着技术发展,数据流通模型经历了从批处理到流批一体的演进过程。
1. 传统批处理模型
在传统Hadoop架构中,数据流通主要采用批处理模型:
数据定期从源系统批量抽取(如每日一次)存储在HDFS中,按批次进行处理(MapReduce/Hive)处理结果写入HDFS或数据仓库最终用于报表生成或离线分析
这种模型的特点是:
简单可靠,易于实现和维护适合历史数据分析和报表生成数据时效性差,通常为T+1级别资源利用率低,处理集中在特定时间段
2. 流处理模型
随着实时数据价值的凸显,流处理模型逐渐兴起:
数据实时产生并流入系统(如Kafka)Flink实时处理流数据处理结果实时写入目标系统(HBase、Kafka等)支持实时监控、实时推荐等场景
流处理模型的特点是:
数据时效性高,延迟可达毫秒级资源持续利用,系统负载平稳适合实时决策和响应场景实现复杂度高,需处理乱序、延迟等问题
3. 流批一体模型
现代数据处理需求既需要实时性,又需要处理历史数据,流批一体模型应运而生:
实时数据通过流处理管道处理,提供低延迟结果历史数据通过批处理管道处理,提供完整分析两种处理方式共享数据存储和元数据通过统一的API和框架实现开发效率提升
Flink与Hadoop集成架构特别适合构建流批一体数据处理平台,其核心优势在于:
统一的计算引擎:Flink同时支持流处理和批处理,避免多引擎维护成本统一的存储层:HDFS/Hive/HBase等存储系统同时支持流批数据读写统一的元数据:通过Hive Metastore实现元数据共享,保证数据一致性统一的API:Flink提供统一的DataStream/DataSet API和SQL接口,降低开发复杂度
流批一体数据流通模型如图所示:
在这个模型中,Flink作为统一计算引擎,既处理实时流数据,也处理HDFS上的批数据,最终将结果写入Hive等存储系统形成统一视图。这种架构实现了:
实时数据处理的低延迟历史数据处理的完整性数据模型和语义的一致性开发和运维成本的降低
4. 数据流通优化策略
为提高数据流通效率,Flink与Hadoop集成架构可采用以下优化策略:
数据本地化:Flink任务尽量调度到数据所在节点,减少数据传输批流融合:热数据通过流处理,冷数据通过批处理,实现资源优化分层存储:热数据存储在HBase/Kafka,温数据存储在HDFS,冷数据归档增量处理:基于Checkpoint和Savepoint实现增量计算,减少重复处理数据压缩:传输和存储过程中采用压缩技术,减少I/O和存储开销预计算与缓存:对热点数据进行预计算和缓存,加速查询响应
通过合理设计数据流通模型和优化策略,可以充分发挥Flink与Hadoop集成架构的优势,构建高效、灵活、实时的数据处理平台。
3.4 资源协调机制:YARN与Flink的协同工作
在Flink与Hadoop集成架构中,资源协调是保证系统高效运行的关键。YARN作为资源管理器,与Flink的协同工作决定了集群资源的分配效率和作业执行性能。
1. YARN资源管理模型
YARN采用主从架构,核心组件包括:
ResourceManager(RM):集群资源的总管理器,负责资源分配和调度
Scheduler:负责资源调度,不关心应用监控和状态ApplicationsManager:负责接收作业提交,启动ApplicationMaster,以及故障恢复
NodeManager(NM):运行在每个节点上的资源管理器,负责节点资源管理和任务监控
管理节点上的CPU、内存等资源启动和监控Container向ResourceManager汇报节点状态
ApplicationMaster(AM):每个应用一个,负责应用的资源申请和任务调度
向ResourceManager申请资源(Container)与NodeManager通信,启动和停止任务监控任务执行,处理任务失败
Container:资源分配的基本单位,包含CPU、内存等资源,是任务执行的环境
YARN资源调度流程如图所示:
2. Flink on YARN资源协调机制
Flink on YARN的资源协调机制基于YARN的应用模型,通过以下组件实现:
Flink YARN客户端:负责与YARN交互,提交Flink应用Flink ApplicationMaster:负责Flink集群的资源申请和管理Flink ResourceManager:与YARN协调资源,请求和释放ContainerFlink TaskManager:运行在YARN Container中,执行Flink任务
Flink on YARN的资源协调流程如下:
客户端提交:Flink客户端向YARN ResourceManager提交应用,包括Flink配置和Jar包AM启动:YARN分配一个Container启动Flink ApplicationMasterTM资源申请:ApplicationMaster向YARN申请资源以启动TaskManagerTM启动:YARN分配Container,ApplicationMaster在这些Container中启动TaskManager任务执行:TaskManager启动后,向ApplicationMaster注册,开始接收和执行任务动态资源调整:根据作业需求,ApplicationMaster可动态申请或释放资源
3. Flink资源模型
Flink定义了自己的资源模型,与YARN资源模型映射:
TaskSlot:Flink资源分配的基本单位,代表TaskManager上的一组资源Slot共享:多个不同任务可以共享一个Slot,提高资源利用率资源配置:可配置每个Slot的CPU和内存资源,与YARN Container资源对应
Flink TaskManager资源模型如图所示:
graph TD subgraph TaskManager (YARN Container) subgraph Slot 1 Task1[任务A - Subtask 1] Task2[任务B - Subtask 1] end subgraph Slot 2 Task3[任务A - Subtask 2] Task4[任务B - Subtask 2] end subgraph Slot 3 Task5[任务C - Subtask 1] end subgraph Slot 4 Task6[任务C - Subtask 2] end endmermaid1234567891011121314151617
4. 动态资源分配
Flink on YARN支持动态资源分配(Dynamic Resource Allocation),能够根据作业需求自动调整资源:
资源扩容:当作业需要更多资源时(如数据量增加),自动申请更多Container资源缩容:当资源利用率低时,自动释放闲置Container触发机制:基于TaskManager的Backlog和Idle状态触发资源调整
动态资源分配的优势在于:
提高集群资源利用率自动适应工作负载变化减少人工干预降低运营成本
5. 资源调度策略优化
为提高Flink on YARN的资源利用效率,可采用以下优化策略:
资源隔离策略:合理设置YARN的资源隔离级别,平衡隔离性和资源利用率调度策略选择:根据业务需求选择合适的YARN调度器(Capacity/Fair)任务调度优化:启用Flink的本地化调度,减少数据传输内存配置优化:合理配置Flink内存(堆内/堆外),避免OOM或资源浪费并行度调整:根据数据量和集群规模调整作业并行度
6. 高可用资源协调
为实现高可用,Flink on YARN的资源协调机制还包括:
JobManager HA:通过ZooKeeper实现JobManager故障自动恢复状态持久化:Checkpoint和Savepoint存储在HDFS,保证故障后可恢复资源重分配:故障恢复后,ApplicationMaster重新向YARN申请资源任务重调度:在新分配的资源上重新调度任务,恢复作业执行
通过精细的资源协调机制,Flink与YARN能够高效协同工作,实现资源的动态分配和优化利用,为大数据处理提供强大的计算能力支撑。
4. 环境搭建与配置:从零开始的集成之路
4.1 环境规划与组件版本选择
在开始搭建Flink与Hadoop集成环境之前,需要进行详细的环境规划和组件版本选择,这直接影响系统的稳定性、兼容性和性能。
1. 集群规模规划
根据业务需求和数据量,可选择不同规模的集群配置:
开发测试环境:3-5节点,适合学习和功能测试小型生产环境:6-10节点,适合中小规模数据处理大型生产环境:10+节点,适合大规模数据处理
2. 节点角色规划
典型的节点角色规划如下(以5节点集群为例):
| 节点 | 角色 | 主要组件 |
|---|---|---|
| node1 | 主节点 | NameNode, ResourceManager, Hive Metastore, Flink JobManager |
| node2 | 备用主节点 | SecondaryNameNode, Zookeeper |
| node3 | 工作节点 | DataNode, NodeManager, HBase RegionServer, Flink TaskManager |
| node4 | 工作节点 | DataNode, NodeManager, HBase RegionServer, Flink TaskManager |
| node5 | 工作节点 | DataNode, NodeManager, HBase RegionServer, Flink TaskManager |
3. 组件版本选择
版本选择需考虑兼容性、稳定性和功能需求,以下是推荐的组件版本组合:
| 组件 | 推荐版本 | 说明 |
|---|---|---|
| Hadoop | 3.3.4 | 稳定版,支持Erasure Coding、Shell脚本改进等新特性 |
| Flink | 1.18.1 | 最新稳定版,支持Hadoop 3.x,性能和稳定性较好 |
| Hive | 3.1.3 | 与Hadoop 3.x兼容,支持ACID事务 |
| HBase | 2.4.15 | 稳定版,与Hadoop 3.x兼容 |
| ZooKeeper | 3.8.1 | 稳定版,提供分布式协调服务 |
| Kafka |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...