
从 DeepSeek R1 那一代出来之后,我们就很清楚的知道 DeepSeek一直不是智能程度最高的模型。由于它前面往往都还有一个 OpenAI 或者是 Anthropic 的模型,有时候也可能是谷歌或者其他模型。总之,它绝对不是最机智的一个。
同时我们也发现,DeepSeek 永远不是最便宜的模型。由于最便宜的模型往往都有很大的短板,列如:
1. 上下文长度没达到要求(之前是 256K,目前是一个 Million)
2. 智能程度太低
3. 吞吐太慢等
但 DeepSeek 往往都能达到一个平衡点,我称之为“智能密度”。
什么是智能密度?就列如说我们用 Artificial Analysis 的数据来看,它有一个指标叫 Intelligence Index,还有一个指标是价格。那么我们就用这个智能程度除以价格。
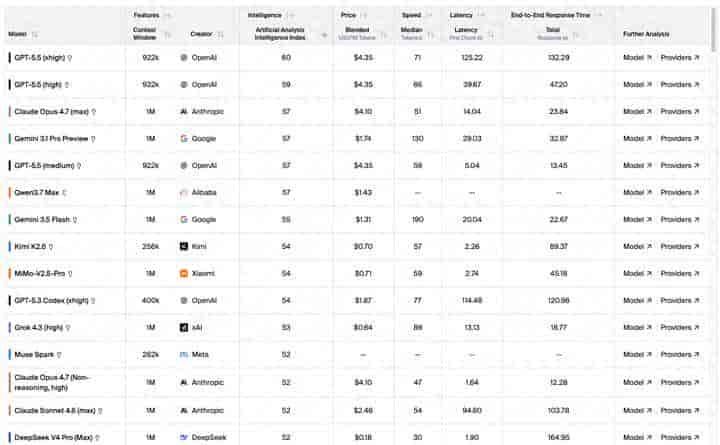
DeepSeek V4 Pro 的 Intelligence Index 为 39,blended price 为 $0.18 / 百万 tokens;High 模式为 50,Max 模式为 52,价格同样显示为 $0.18 / 百万 tokens。用一个粗略指标“智能指数 ÷ 每百万 tokens 价格”来算,V4 Pro 是 216.7,High 是 277.8,Max 是 288.9。
对比一下,GPT-5.5 high 是 59 / $4.35,智能价格比约 13.6;Claude Opus 4.7 max 是 57 / $4.10,约 13.9;Gemini 3.1 Pro Preview 是 57 / $1.74,约 32.8。也就是说,DeepSeek V4 Pro 的优势不是绝对智力天花板,而是单位美元能买到的有效智能超级高。
第二,缓存命中。DS V4 Pro 官方价格里,缓存未命中输入是 $0.435 / 百万 tokens,缓存命中输入是 $0.003625 / 百万 tokens。换句话说,命中缓存后的输入价格只有未命中的 1/120。对于长文档问答、代码库分析、固定 system prompt、Agent 工作流这种上下文反复复用的场景,缓存命中会把实际边际成本继续往下压。
|
输入缓存命中率 |
有效输入价格 |
200 美元可买输入量 |
|
0% |
$0.435 / M |
约 4.60 亿输入 tokens |
|
25% |
$0.3272 / M |
约 6.11 亿输入 tokens |
|
50% |
$0.2193 / M |
约 9.12 亿输入 tokens |
|
75% |
$0.1115 / M |
约 17.94 亿输入 tokens |
|
90% |
$0.0468 / M |
约 42.77 亿输入 tokens |
|
100% |
$0.003625 / M |
约 551.72 亿输入 tokens |
据说DS的缓存命中不高概率高,且保存时间长,所以实际上的缓存命中率超级的高,10块钱可以中等烈度的玩几天。
DeepSeek-V4 Pro 完全符合一个阶梯式模型该有的强度,就是对高端模型的定价有冲击,对比它弱的模型有全面的碾压效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。















[db:评论]