一个被许多人忽略的数据,可能比任何模型跑分都更能说明问题。
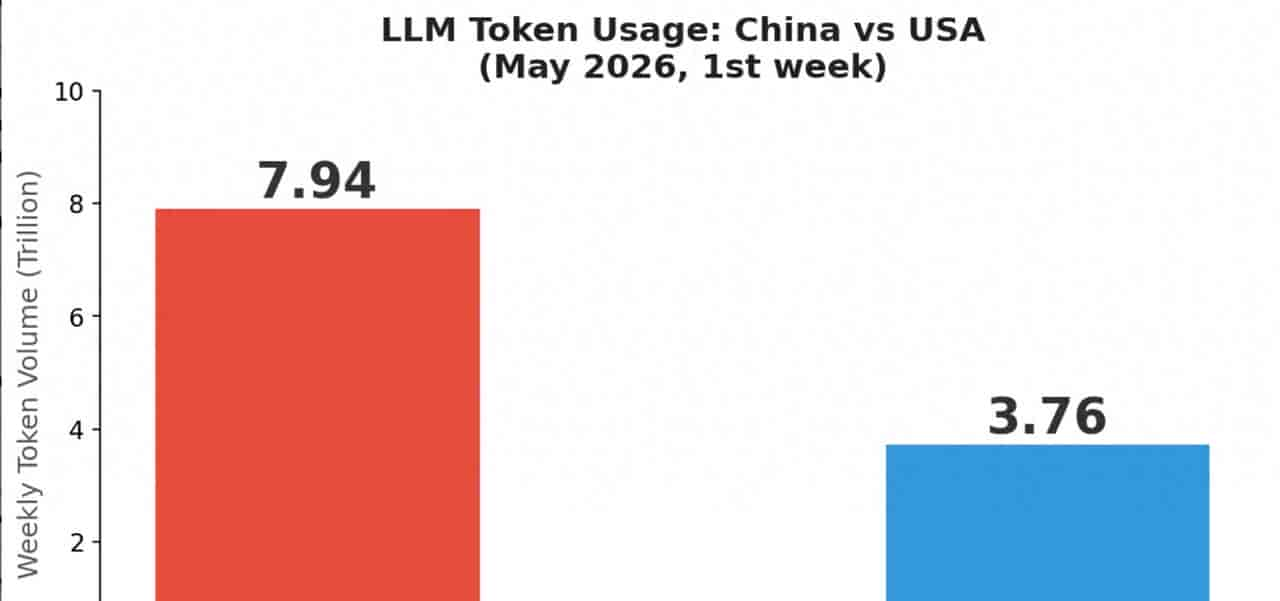
据央视网报道,截至2026年5月第一周,中国主要大模型周调用量达7.94万亿Token,而美国模型同期数据为3.76万亿Token。中国首次以超过2倍的优势反超美国。
Token是什么?它是AI的”燃料”。每当你和AI对话、让它写文章、生成代码、分析数据,都在消耗Token。Token调用量本质上反映了一个国家AI应用的真实活跃度。
这个数据告知我们一件很重大的事:中国AI的竞争力不在模型参数榜上,而在应用层。
想一想:过去两年,AI行业的大部分注意力都聚焦在”谁的模型更强”上。GPT-4、Claude、Gemini、DeepSeek、通义千问……排行榜上你追我赶。但量子位智库5月20日发布的《2026中国AI应用全景图谱报告》显示了一个更关键的信号:2026年4月,国内AI应用网页端月访问量突破9亿次,App端日活用户同比暴涨223%。
这些数字意味着,AI在中国已经从”尝鲜”变成了”日常”。
为什么中国的应用层跑得更快?有几个缘由。
第一,中国的移动互联网生态全球最发达。当AI能力嵌入微信、支付宝、抖音这些超级App时,用户不需要”学习使用AI”,AI直接变成了原有体验的升级。美国用户要专门去下载一个ChatGPT App,而中国用户在刷短视频时AI已经帮你生成了字幕和特效。
第二,中国的商业竞争倒逼效率。”百模大战”打了两年,结果不是拼出了最强模型,而是把模型推理成本打到了全球最低。成本一降,应用就爆了。
第三,中国有全球最完整的产业链。AI在制造业、物流、零售这些实体经济场景中的渗透,产生了海量的Token消耗。而美国AI的应用更多地聚焦在软件和信息服务领域。
但硬币有另一面。调用量领先不等于技术领先。美国在基础模型研发、芯片制造、学术前沿等底层能力上依旧有明显优势。中国应用层跑得快的背后,算力芯片自给率、基础模型原创性、高质量数据集建设这些”暗功夫”还需要补课。
未来的AI竞争,可能不再是单一的”模型对决”,而是”技术创新+生态构建+应用落地”的三线作战。中国在第三条线上暂时领先,但这场马拉松才刚跑完第一公里。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









