大家好,我是小辉。
许多人刚开始学AI,第一道坎不是工具不会用,而是术语太多。
打开一个教程,里面全是 Prompt、Token、RAG、Agent、Embedding、MCP、Vibe Coding。再看几篇行业文章,又冒出多模态、上下文窗口、微调、蒸馏、GPU、量化。
看着很专业,实则许多词换成人话并不难。
今天这篇文章,我不按字母表讲,也不堆技术定义。我按学习难度分成7层,帮你把60个常见AI术语串起来。
你不用一次全背会。先知道它属于哪一层、解决什么问题,后来看到这些词就不会被劝退。
先记住这张地图
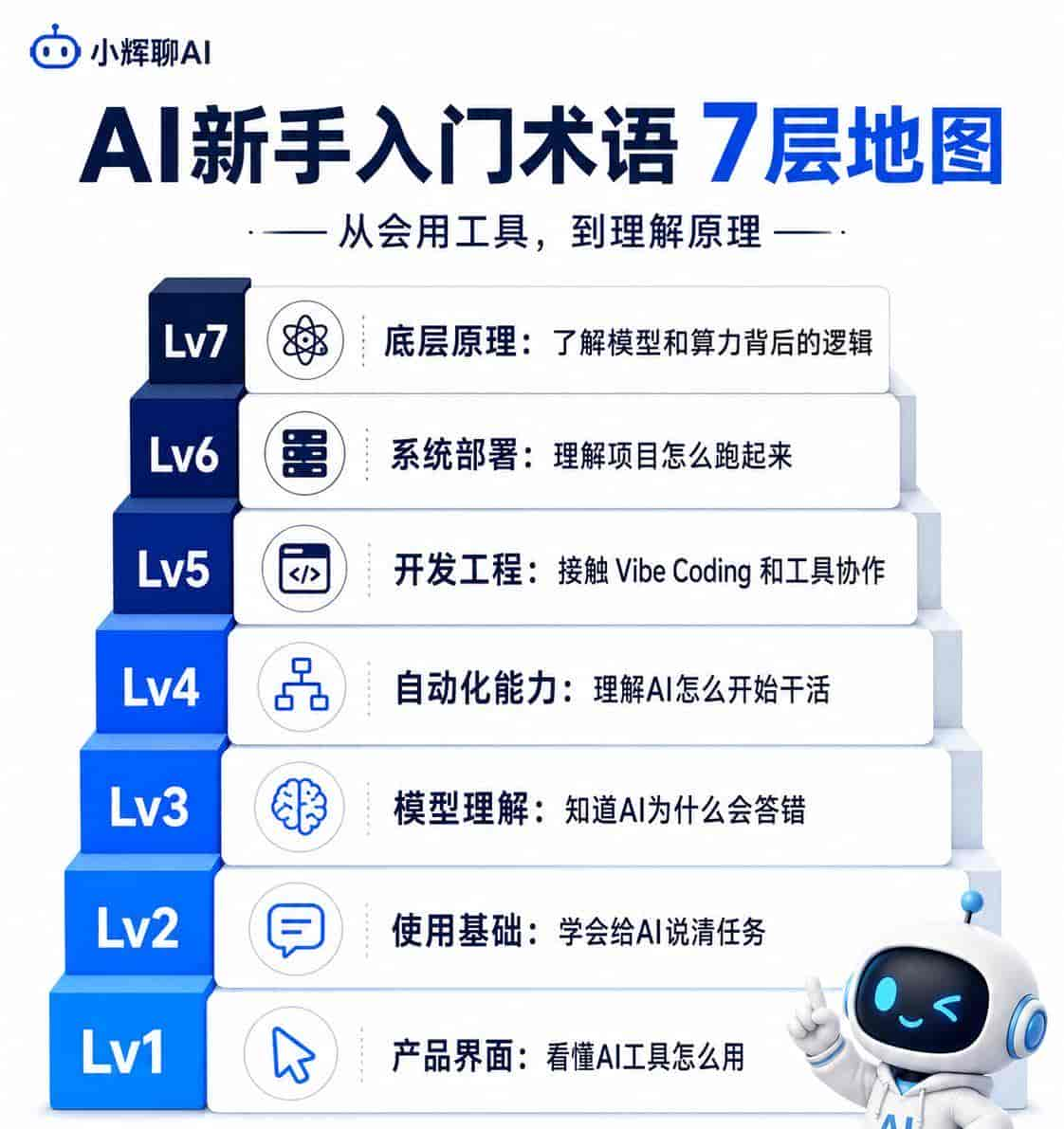
新手最应该先学前4层。后面3层不用急,等你真的想做小工具、跑项目、看技术教程时再补。
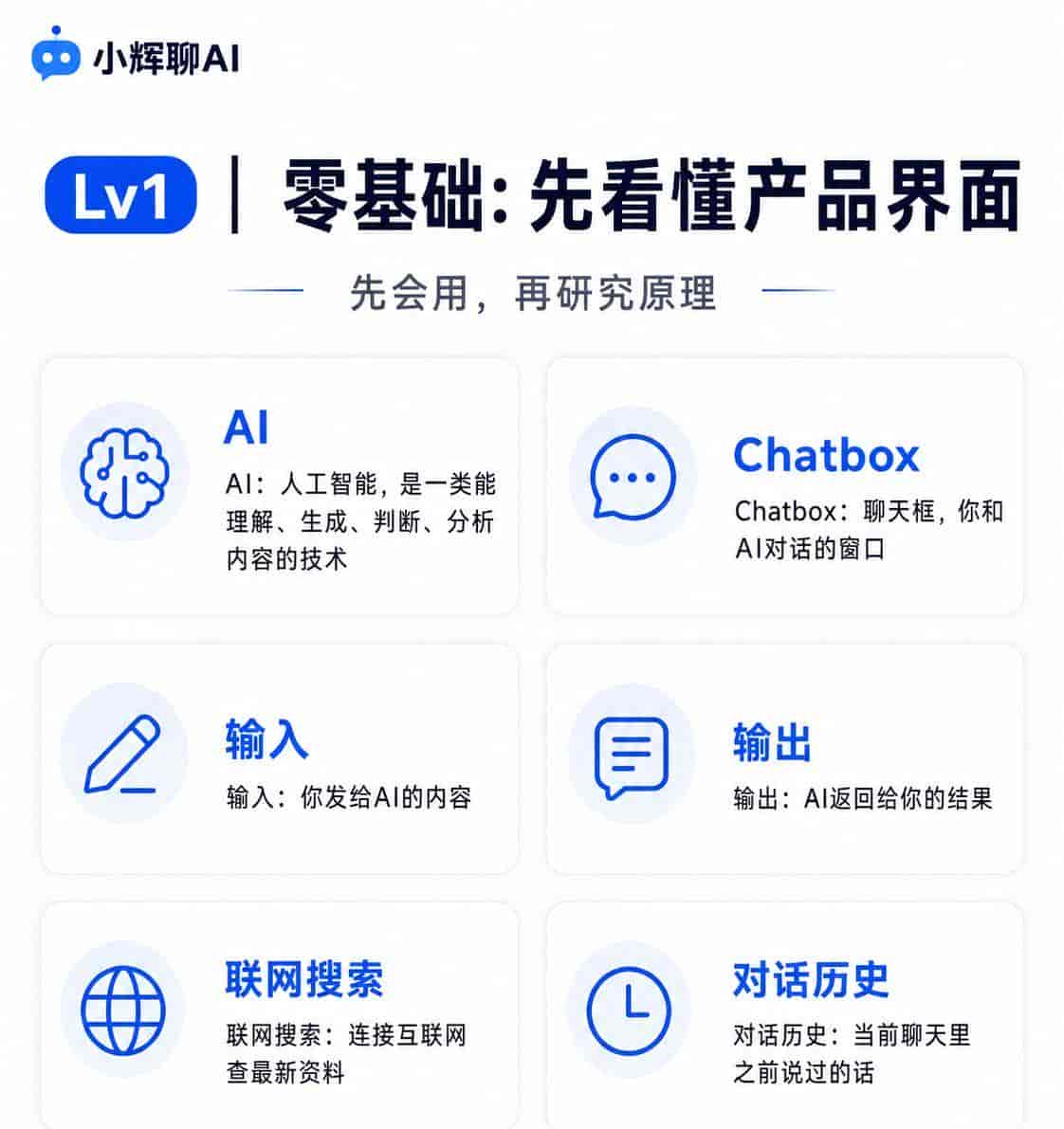
AI:人工智能,不是某一个软件,而是一类能理解、生成、判断、分析内容的技术。ChatGPT、豆包、Kimi、文心一言,都是AI产品。
Chatbox:聊天框,也就是你和AI对话的窗口。你输入问题,AI在这里回复你。
输入:你发给AI的内容。可以是一句话、一段资料、一张图片、一个文件,或者一组要求。
输出:AI返回给你的结果。列如文章、总结、代码、图片提示词、表格、方案。
联网搜索:让AI连接互联网查最新资料。适合查新闻、价格、工具更新、政策变化,但结果依旧需要核对来源。
对话历史:当前聊天里之前说过的话。AI会参考它,但不代表永远记得,也不代表每次都能准确引用。
这一层的重点是:先别急着研究原理,先知道你在界面里点的每个功能大致是什么意思。

Prompt:提示词,就是你给AI的任务说明。列如“帮我写一篇小红书笔记”。提示词越清楚,AI越容易给出能用的结果。
模型:AI背后的“大脑”或“发动机”。不同模型能力不同,有的擅长写作,有的擅长代码,有的擅长图片理解。
AIGC:AI Generated Content,意思是AI生成内容,列如AI文章、AI图片、AI视频、AI音乐。
上下文:你给AI的背景信息。列如你是谁、写给谁看、发布在哪个平台、语气要怎样。
多模态:AI不只处理文字,还能理解图片、音频、视频、文件等内容。
角色设定:让AI扮演某个角色。列如“你是一名公众号编辑”“你是一名短视频策划”“你是一名英语老师”。
提示词模板:可以反复使用的一套指令结构。常见格式是:角色 + 任务 + 背景 + 要求 + 输出格式。
改写:让AI把原文换一种表达方式。列如更口语化、更专业、更适合小红书。
总结:让AI把长内容提炼成重点。适合文章阅读、会议纪要、资料整理。
翻译:让AI把一种语言转换成另一种语言,也可以顺便润色和本地化表达。
这一层最重大的是 Prompt。新手不要只说“帮我写一篇文章”,要把目标、读者、场景和输出格式说清楚。
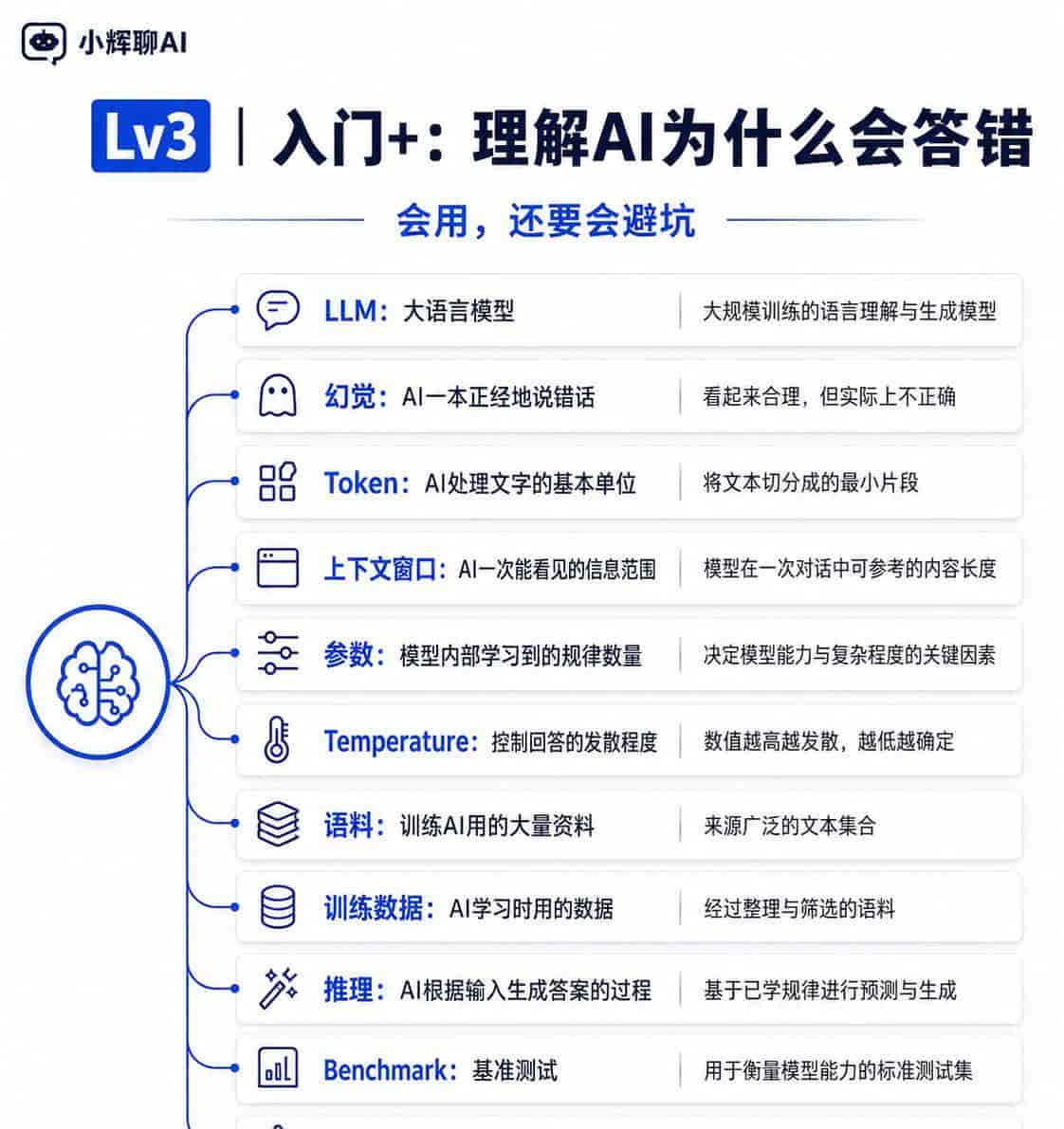
LLM:大语言模型,专门处理语言任务,列如聊天、写作、翻译、总结、写代码。
幻觉:AI一本正经地说错话,列如编数据、编来源、编案例。写文章、做资料时必定要核查。
Token:AI处理文字的基本单位。它不完全等于一个字或一个词。你输入和AI输出都会消耗Token。
上下文窗口:AI一次能“看见”的信息范围。窗口越大,能处理的资料越多,但不代表永远不会遗漏。
参数:模型内部学习到的规律数量。参数多不必定绝对更好,但一般说明模型更复杂。
Temperature:控制AI回答的发散程度。低一点更稳定,高一点更有创意。
语料:训练AI用的大量资料,包括文本、图片、代码等。
训练数据:AI学习时用的数据。数据质量会影响模型表现。
推理:AI根据你的输入生成答案的过程。它看起来像思考,但不是人类意义上的真正思考。
Benchmark:基准测试,用统一题目比较不同AI模型的能力。
评测:测试AI在写作、数学、代码、推理、安全等方面表现怎么样。
这一层是为了帮你避坑。AI说得流畅,不代表必定正确;越涉及数据、政策、价格、专业结论,越要查来源。
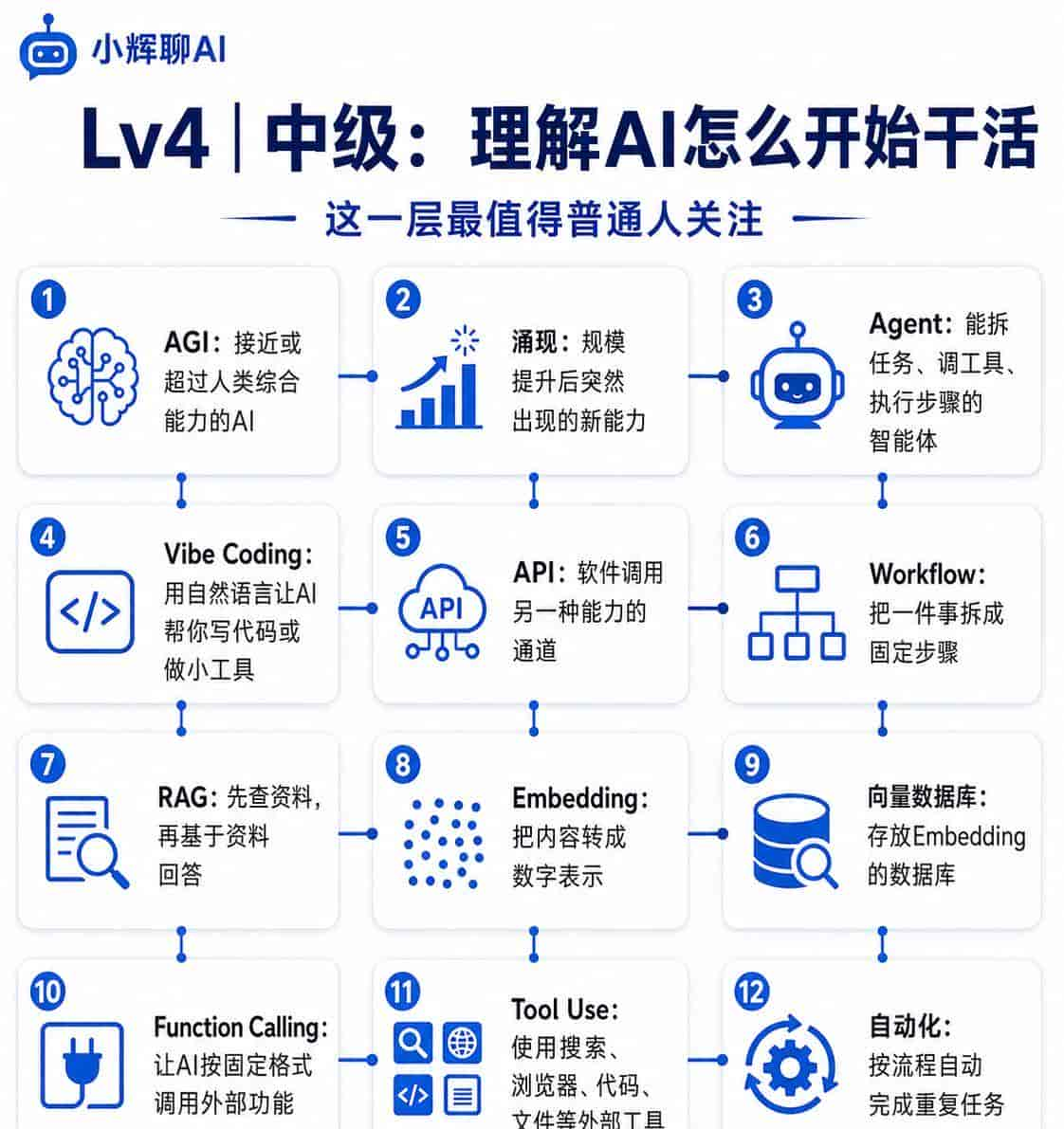
AGI:通用人工智能,指接近或超过人类综合能力的AI。目前还没有真正公认实现。
涌现:模型规模或训练水平提升后,突然表现出一些以前不明显的能力。
Agent:智能体,不只是回答问题,还能拆任务、调用工具、执行步骤。
Vibe Coding:用自然语言告知AI你想做什么,让AI帮你写代码、做网页、小工具。适合做原型,但正式上线仍要检查安全和稳定性。
API:接口。简单理解,就是让一个软件调用另一个软件能力的通道。
Workflow:工作流,把一件事拆成固定步骤,让AI参与其中。列如选题、写大纲、写初稿、改标题、生成配图提示词。
RAG:检索增强生成。先查资料,再让AI基于资料回答,能减少瞎编。
Embedding:把文字、图片等内容转成数字,方便机器判断“意思像不像”。
向量数据库:存放Embedding的数据库,常用于知识库问答、类似内容搜索。
Function Calling:让AI按固定格式调用外部功能。列如查天气、查订单、生成表格。
Tool Use:工具调用。AI可以使用搜索、浏览器、代码、文件等外部工具完成任务。
自动化:让AI或软件按流程自动完成重复任务。列如定时整理热点、生成文章大纲、汇总表格。
这一层是目前最值得普通人关注的。由于AI的价值不只是回答问题,而是开始进入流程,帮你推进任务。
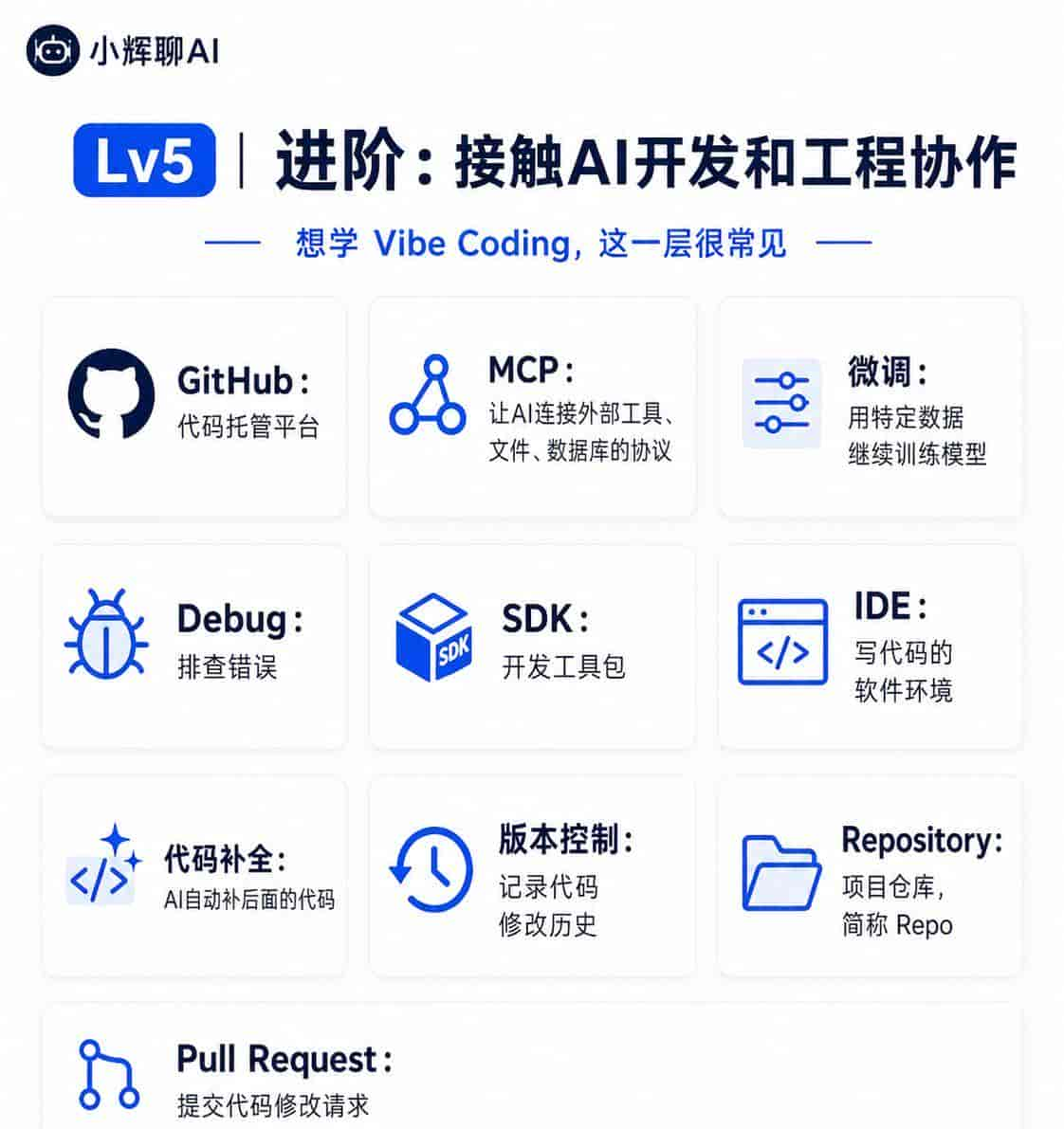
GitHub:代码托管平台。许多开源项目、AI工具、代码教程都放在这里。
MCP:Model Context Protocol,一种让AI连接外部工具、文件、数据库的协议。可以理解为AI接插件的标准接口之一。
微调:用特定数据继续训练模型,让它更适合某个场景。列如客服、法律文书、医学问答。
Debug:排查错误。代码报错、工具跑不起来时,就需要Debug。
SDK:开发工具包。开发者用它更方便地调用某个平台的能力。
IDE:写代码的软件环境,列如 VS Code、Cursor。
代码补全:AI根据你写到一半的代码,自动补后面的内容。
版本控制:记录代码修改历史,方便回退和协作。Git就是常见工具。
Repository:仓库,简称Repo。一个项目的代码、文档、配置一般都放在一个仓库里。
Pull Request:提交代码修改请求,常用于团队协作或开源项目。
这一层适合想学Vibe Coding的人。你不用一开始全会,但看到教程里出现这些词,至少知道它们在讲开发流程。
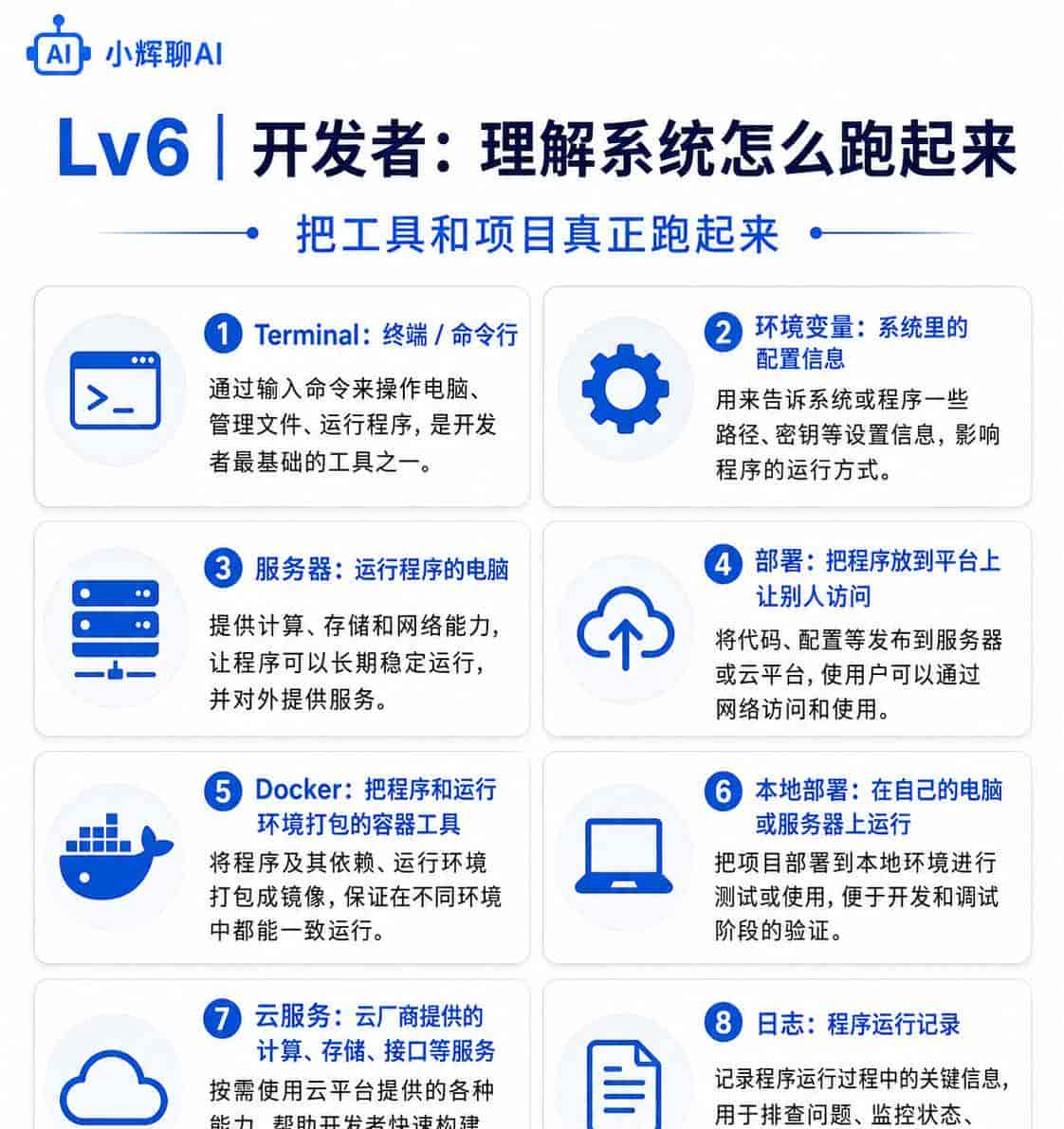
Terminal:终端/命令行。用文字命令操作电脑,列如安装工具、运行项目。
环境变量:系统里的配置信息,列如API Key、数据库地址。程序运行时会读取它。
服务器:运行程序的电脑。可以是云服务器,也可以是本地机器。
部署:把程序放到服务器或平台上,让别人可以访问使用。
Docker:容器工具。可以把程序和运行环境打包,减少“我电脑能跑,你电脑不能跑”的问题。
本地部署:把AI模型或工具安装在自己的电脑或服务器上运行。
云服务:云厂商提供的计算、存储、数据库、AI接口等服务。
日志:程序运行记录。出问题时看日志,可以知道哪里报错。
这一层更偏技术。普通用户不用马上学,但如果你后来想把AI工具跑起来,就会常常遇到。
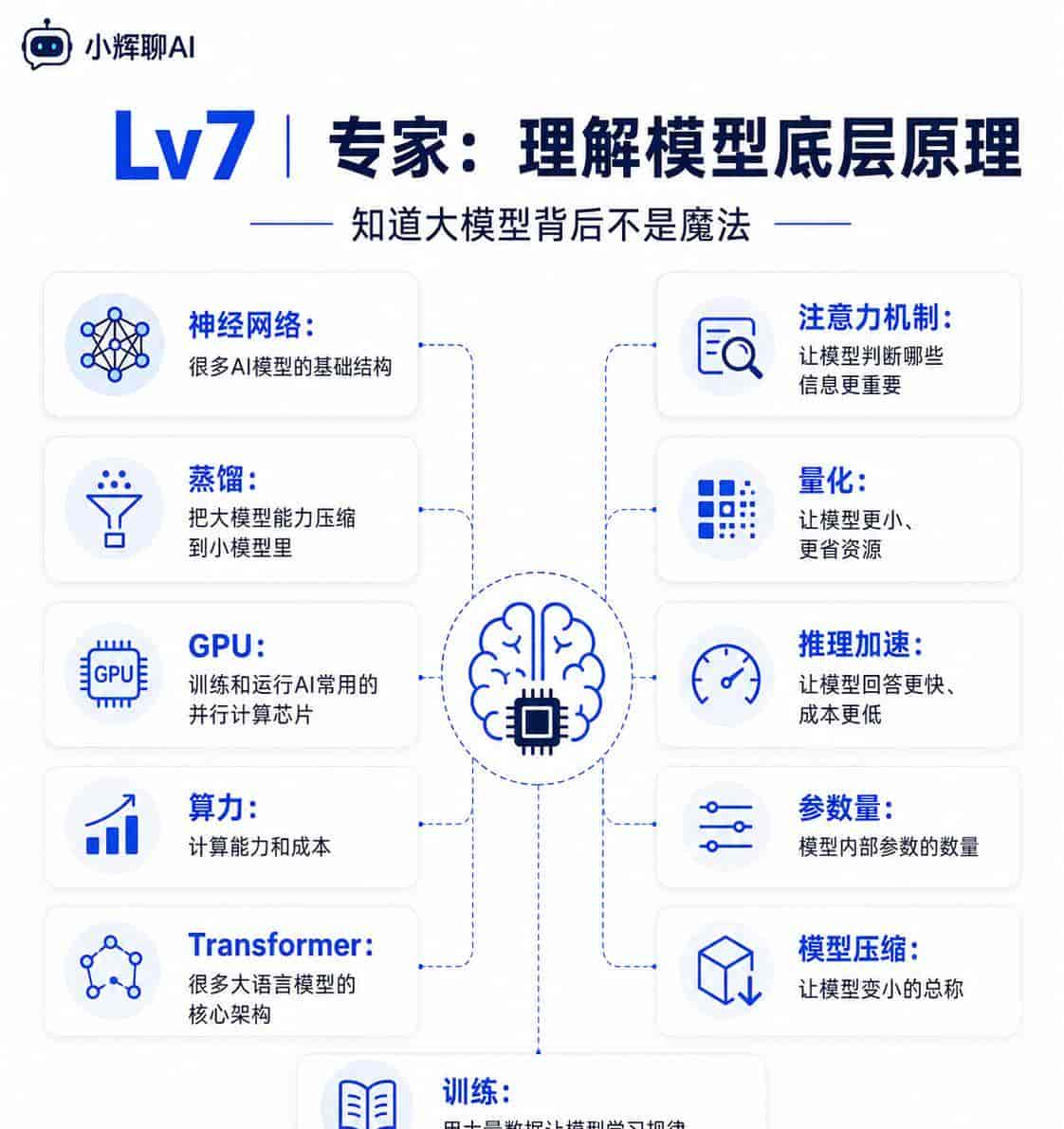
神经网络:模仿人脑神经连接的一种计算结构,是许多AI模型的基础。
蒸馏:把大模型的能力“压缩”到小模型里,让小模型更轻、更便宜。
GPU:图形处理器。训练和运行AI模型常用它,由于它适合大量并行计算。
算力:计算能力。训练大模型需要很强算力,所以行业里常常讨论算力成本。
Transformer:目前许多大语言模型的核心架构,擅长处理语言和序列信息。
注意力机制:Transformer里的关键机制,让模型判断哪些信息更重大。
量化:把模型变得更小、更省资源,方便部署,但可能略微影响效果。
推理加速:让模型回答更快、成本更低的一系列优化方法。
参数量:模型内部参数的数量。常见说法如几十亿、几百亿参数。
模型压缩:让模型变小,包括蒸馏、量化、剪枝等方法。
训练:用大量数据让模型学习规律的过程。
这一层不用急着掌握。你只需要知道:大模型背后不是魔法,而是数据、算法和算力一起作用的结果。
新手最该先记哪几个?
如果你刚开始学AI,我提议先记这8个:
Prompt、上下文、Token、幻觉、RAG、Agent、Workflow、Vibe Coding。
为什么是这8个?
由于它们最贴近日常使用。

小辉的提议
AI术语不是拿来装懂的,而是学习路上的路标。
你每遇到一个新词,只需要问自己三个问题:
它属于哪一层?
它解决什么问题?
我目前用不用得上?
能回答这三个问题,术语就不再是黑话。
刚开始学AI,不要被英文词吓住。先从使用开始,再慢慢理解背后的逻辑。
我是小辉,之后会继续用普通人能听懂的方式,带大家拆AI工具、AI工作流和Vibe Coding。
关注小辉聊AI,每个月一起复习一次AI关键词。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...