省流版,image生成
伴随着人工智能(AI)在这几年的发展,人们不断对AI产生新的认识:它是如何在短短几秒内作出复杂的回答?AI怎么怎么这么懂我,AI会不会产生自我意识,甚至于有人开始但是智械危机了,我认为,“战锤40K”的时代还是难以到来,从AI的运行逻辑上可以看出来。
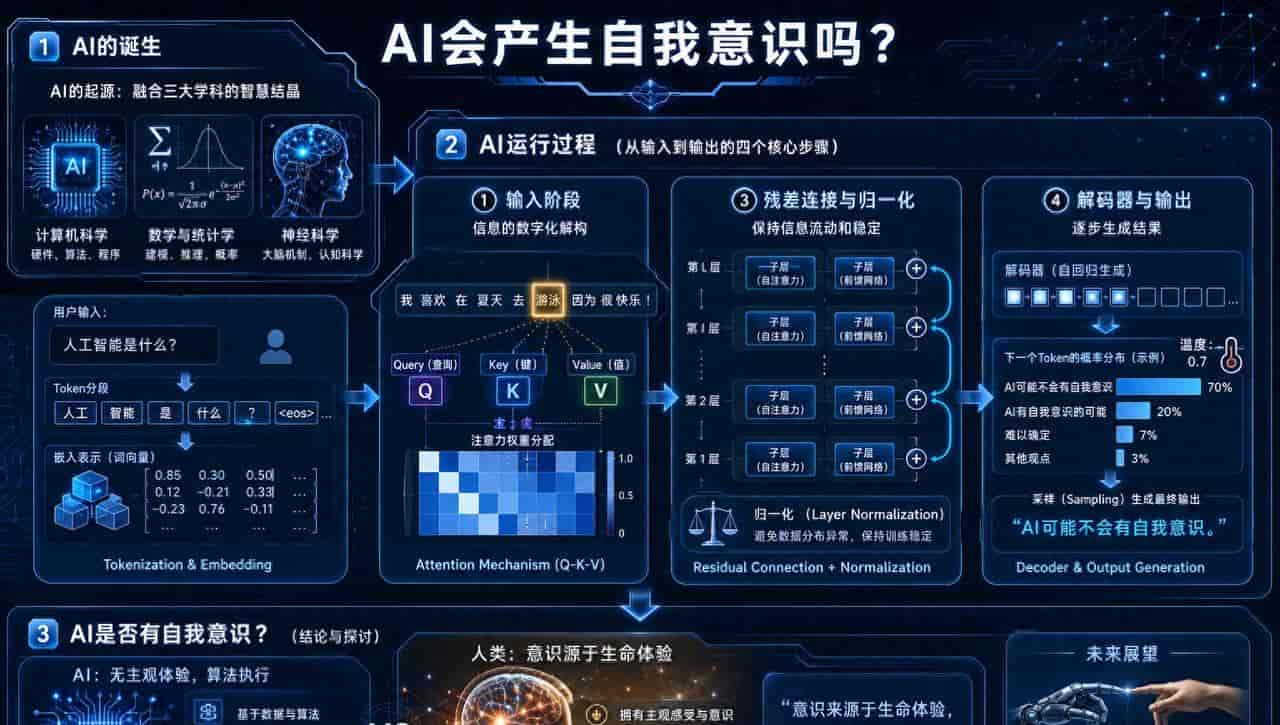
那么,AI是如何一步步实现“智能”的呢?让我们顺着AI的运行流程剖析一下。
1. 入场:数据输入与初步编码AI需要先接收输入的数据,这些可以是文字、图片、语音或其他形式的信息。为了在数字世界中处理这些输入,AI必须第一对它们进行数字化的编码,转化为它“能看懂”的语言。
输入处理与分段(Tokenization)以自然语言处理(NLP)为例,我们日常输入的文字(列如“人工智能是什么?”),AI需要将其拆分成一个个更小的单位,一般是“Token”(标记)。
Token可以是单词、字符,或者更小的语义单位。
AI通过分段,把一整句输入信息分解为便于处理的小块。列如,句子“我喜爱机器学习”可能变成这样的Token序列:[“我”, “喜爱”, “机器”, “学习”]
每个Token就像拼图的一块,把句子拆分后,AI才能一块块分析它的语义和上下文,将它重新组装成完整的意思。
嵌入层:将Token转化为数字向量,人类看得懂“喜爱”这样的词语,但计算机只理解数字。因此,AI中的嵌入层(Embedding Layer)需要为每个Token生成一个向量表明。这些向量是一组数字,包含了词语的语义关系(如“机器”与“学习”的关系距离近,“机器”和“喜爱”则稍远)。
举例来说:
“学习”可能被映射为:[0.8, 0.2, 0.5]
“机器”可能被映射为:[0.7, 0.3, 0.6]
这些向量化操作使AI建立了对词语之间内在关系的数学认知。
2. 聚焦核心:注意力机制与上下文理解经过Token化和嵌入后,AI不会逐个孤立地处理这些Token。
在文本生成或理解任务中,词汇的上下文超级关键。
例如,“他喜爱苹果”中的“苹果”是在说水果,而不是公司。
当输入变得很长,如何捕捉这种细微的语义差异?
注意力机制(Attention Mechanism):聚焦重大信息注意力机制可以理解成AI在阅读内容时的“注意力分配器”。它会判断哪些词语(或输入片段)对当前的任务更重大,并根据它们的重大性调整权重。
列如,阅读“今天的天气很好,我决定去游泳”,如果AI需要回答你的决定是什么,它会特别关注“决定”和“游泳”这两个Token,而忽略不重大的信息。
在技术层面,注意力机制通过三个核心向量来实现:Query(查询向量),Key(键向量),Value(值向量),AI会根据每个Token的Query和其他Token的Key进行类似性计算,看“谁和谁的关系重大”。
最终,对重大的Token赋予更高的权重,输出一个新的表明。形象化解释:想象你在人群中辨认熟人,“Query”就是你记住的熟人特征,“Key”是人群每个人的特征标签,“Value”是这些人的名字。根据Query和Key的匹配程度,你快速找到需要注意的人。
3. 信息传播:多层残差连接和归一化从注意力机制中,AI已经学会了如何“聚焦”于输入的重大部分,但信息在AI的神经网络中并非一次处理完成。
为了让信息传递得更高效、更深入,AI采用了以下两个关键技术:
残差连接(Residual Connection)当信息在网络中层层传播时,可能会出现“梯度消失”的问题(也就是说,信息逐渐被稀释、丢失)。残差连接通过“跳跃连接”,在每一层神经网络的输出中加入输入的数据,从而保留了原始信息。
举例:假设当前处理到的输入表明为A,下一层网络生成B,残差连接会输出A + B。这种操作类似于“备份”原始数据,确保上下文始终融入最终的输出。
归一化(Normalization)为了保证每层神经网络在处理信息时稳定,减小异常值的影响,会对输入值进行归一化。归一化让AI像人类一样,不轻易被极端数据“吓到”,而总是保持稳定。
4. 输出创造:解码器和概率采样AI通过编码器(Encoder)获取对输入信息的理解,而解码器(Decoder)是它创造输出的关键。
解码器如何工作?解码器的核心任务,是根据编码层的结果,逐步生成输出序列。
举例来说,当生成一篇文章或一句对话时,解码器是动态工作的:它会根据上下文生成一个个Token(词语或字符)。AI并不直接“确定”输出,而是生成Token序列的概率分布。
例如,对于输入“人类的未来”,AI可能预测出Token序列的概率如下:
“是” 60%
“将” 30%
“不” 10%
解码时,AI会根据计算出的概率分布选择最可能的Token。随后,这个Token会被加入上下文中一起参与下一次预测,直到生成完整输出。采样策略生成输出时,最常见的方式包括贪心搜索(选择最高概率的Token)或束搜索(同时保留多个可能路径)。另外,“温度参数”控制了输出的多样性,列如降低温度会让AI偏保守,更倾向于选择高概率的词。
5. 最终校准:惩罚机制与结果优化在输出阶段,为了避免AI生成“机械式”或“重复性强”的内容,一些模型会设计惩罚机制(Penalty Mechanism)。
例如:避免重复出现一样的短句;对低概率的Token进行轻微强化,增加多样性。这就好比AI自己给自己加了“规则”,在生成过程中不断优化输出。
总结:人工智能是如何合成答案的?从输入到输出,AI的运行是一个复杂且连续的链条:
一→输入数据经过分段(Tokenization)和嵌入,转化为数字世界的向量表明
一→注意力机制在全局中寻找最相关的信息
一→残差连接和归一化让信息传播稳定并保持上下文
一→解码器基于概率分布逐步生成Token,给出答案
一→加入惩罚机制优化结果,让输出更加符合逻辑和需求。
这一切看似复杂,实则不过是人类传递给机器的规则和步骤的叠加。虽说AI生成的文字、决策等令人惊叹,但它不具备自我意识——它只是人类算法思维的延伸。
但是AI好用是真的,这篇文章的材料是gpt辅助的,image革新后一键生成图片也超级好用,大家在AI时代也要多接触学习AI,本篇的目的就是为了让大家更了解AI的运行过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...