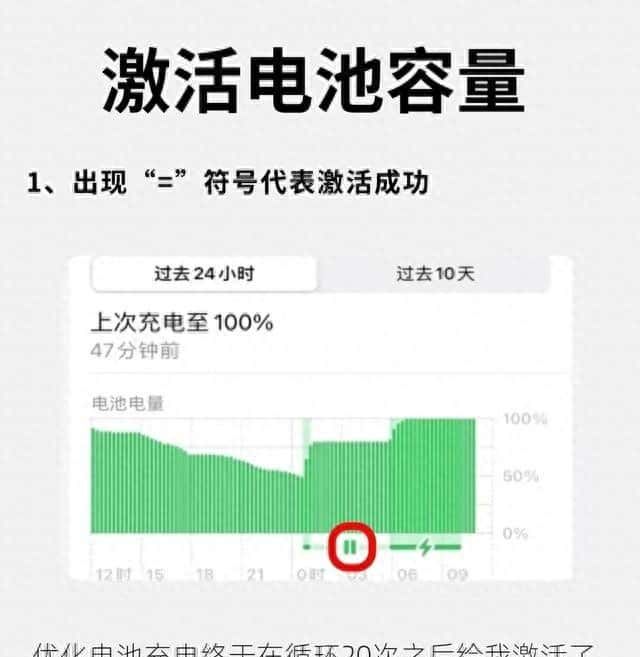
DeepSeek-R1 671B满血版代表了顶尖AI模型的能力,企业在部署时都应该优先思考满血版。然后,再按照使用场景,酌情思考部署蒸馏版的小模型。
出于安全和数据隐私等方面的思考,国内多数企业都想在本地部署,不过,部署推理DeepSeek-R1 671B满血版并不容易。
最近,超聚变FusionOne AI在满血DeepSeek-R1一体机中,嵌入了自主研发的推理加速引擎,通过软硬件协同优化提升了运算效率,模型性能也不打折扣。

从官方介绍中看到,超聚变仅用1台FusionServer G8600服务器,内置8张英伟达H20显卡即可运行原生满血模型DeepSeek-R1 671B,而且用的是官方默认的FP8精度,让模型智能能力无损释放。
超聚变提到,得益于自研推理加速引擎的优化,原本需要8张141GB显存显卡(也就是H200)才能做到,目前仅96G显存的H20即可做到,显存使用量降低30%。
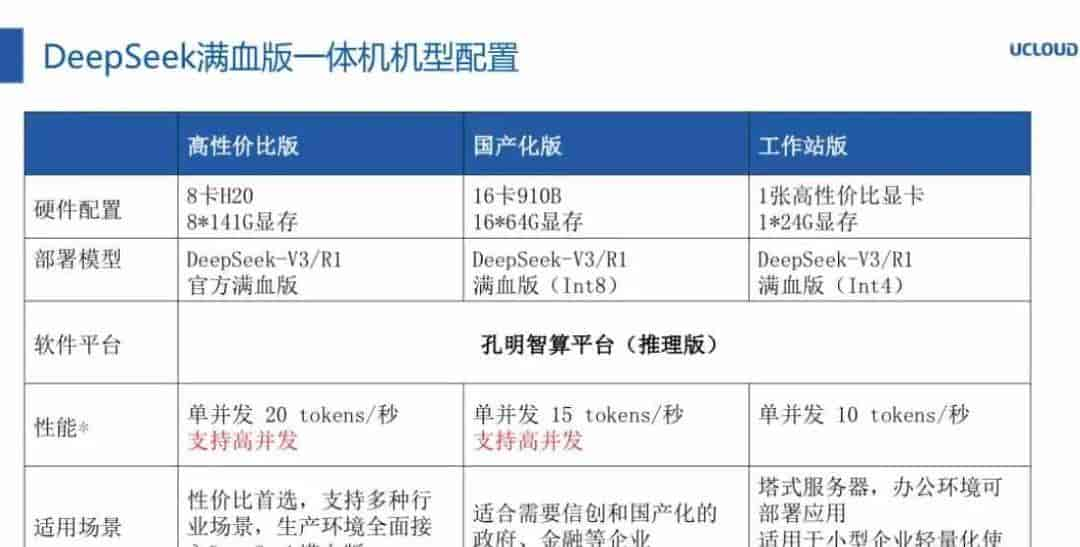
如上图所示,这里使用8张141G显存H200(上图的H20应该是笔误)显卡来部署满血版,这套方案已经可以视为高性价比的版本了,如果换成8张96G显存H20之后,显然性价比又上了一个台阶。
通过对推理引擎的深度优化和KV Cache策略的优化,单台G8600服务器跑满血大模型,性能提升50%,还支持32个并发访问,吞吐量最高可至1000 tokens/秒,属于超级高的表现了。
超聚变还提到,通过简单易用的容器管理平台,用户还可以灵活选择部署DeepSeek全系列的其他模型,支持选择多种AI加速卡,快速满足不同AI应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...