
DeepSeek去年下载量暴跌,新模型有望重振市占率,但挑战不小。2025年,这个曾被誉为“国产AI之光”的应用,下载量从峰值8000万骤降至2000万,跌幅高达72.2%。用户流失的背后,是行业生态的深层变革。
暴跌的背后
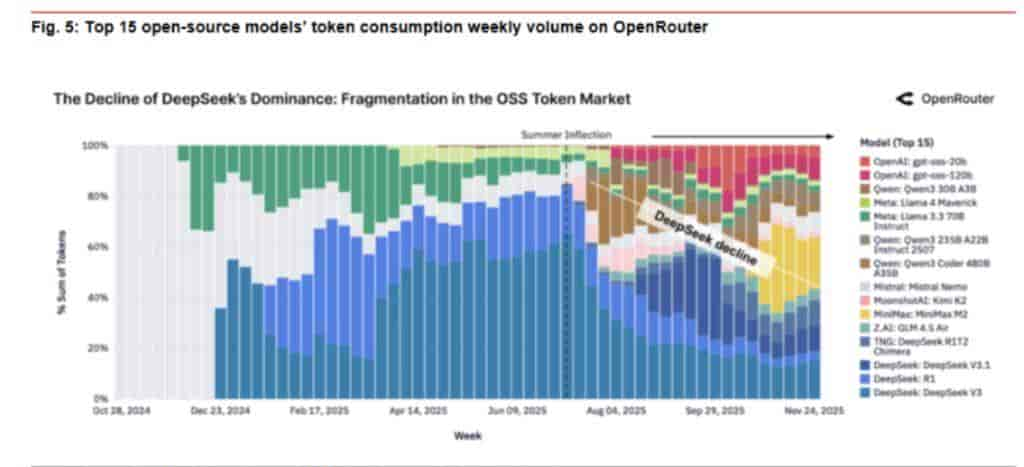
DeepSeek的困境并非单一缘由造成。第一,开源策略像一把双刃剑:作为全球首个免费开源大模型的企业,它推动了AI行业发展,却让自家ToC产品失去了用户壁垒。大量开发者基于开源模型搭建服务,用户通过腾讯元宝、百度智能云等第三方平台就能使用一样技术,无需下载官方App。
更关键的是技术迭代节奏滞后。原计划2025年5月发布的R2模型因性能问题无限期推迟,而同期GPT-5、Gemini等竞争对手疯狂更新,追求新技术的用户自然转向别处。
- 生态竞争挤压:阿里、字节、百度等大厂推出价格更低的同类API,并将AI能力深度嵌入搜索、办公、社交等日常产品中。相比之下,DeepSeek作为一个功能相对单一的独立App,在便捷性上逐渐落于下风。
- 体验瓶颈:部分用户反馈性能波动,交互设计停留在“问答机器人”阶段,而竞品如豆包、Qbot已进化为“生活助手”,无缝嵌入用户日常场景。
技术的跃迁
2026年2月11日,DeepSeek悄然推出新模型,支持高达1M(百万)Token的上下文长度,较去年8月的128K提升了近8倍。这意味着它能一次性处理《简爱》这类百万字级文本,精准识别跨章节细节,甚至分析数十万行的企业级代码库或数百页的法律合同。

技术突破源于架构革新:通过“Engram条件记忆”和“mHC流形约束超连接”技术,模型实现“查算分离”,将静态知识存入廉价CPU内存,让GPU专注动态推理。这不仅将HBM显存占用降低30%-50%,还使推理成本降至海外竞品的1/70。
实测显示,提交超过24万个token的《简爱》文档,DeepSeek能完整识别并精准回答人物关系等问题。
此外,新模型知识库更新至2025年5月,离线状态下能准确回答历史新闻事件,补齐了时效性短板。语言风格也更“热烈细腻”,响应质感可媲美Claude 3.5 Sonnet,提升了C端交互体验。
市场的考验
新模型的技术优势为DeepSeek重振市占率提供了可能,但道路并不平坦。
机会在于企业级需求:百万Token上下文能力直接瞄准法律合同审查、金融研报分析、代码库调试等垂直场景,商业化潜力巨大。成本优势也让中小企业能用上顶尖AI,扩大了市场覆盖。
但挑战同样严峻:
- 生态融合度不足:DeepSeek仍聚焦纯文本交互,未支持多模态,而竞品已融入更多生活场景。
- 开源分流持续:用户可能继续通过第三方平台使用技术,品牌粘性难以建立。
- 竞争环境复杂:市场从“一家独大”走向“群雄割据”,GPT-5、Gemini等竞品更新更快,竞争白热化。
技术救场有效,但生态布局才是长久之计。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











