
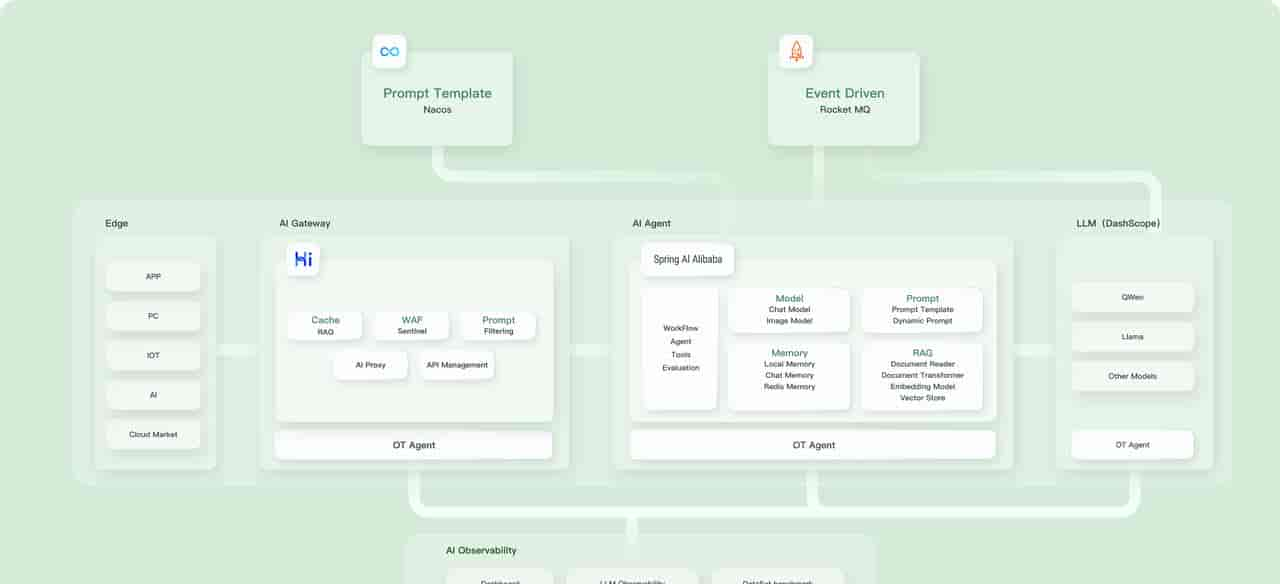
一、引言:当 Spring 遇上 AI,重新定义企业级 AI 开发范式
在生成式 AI 技术爆发的 2025 年,企业级 AI 应用开发正面临前所未有的挑战:如何让 Java 开发者快速接入阿里云通义大模型?怎样在微服务架构中实现 AI 功能的云原生集成?如何平衡模型调用的成本控制与性能优化?Spring AI Alibaba 的出现,正是为了解决这些痛点而诞生的企业级 AI 开发框架。
作为 Spring 官方 AI 框架的深度扩展实现,Spring AI Alibaba 不仅继承了 Spring 生态的工程化优势,更深度整合了阿里云通义大模型服务(如百炼、视觉大模型)、云原生基础设施(Nacos、RocketMQ、Sentinel)以及企业级 AI 开发组件(RAG 工具链、智能 Agent 框架、多模态处理模块)。本文将通过真实企业级场景,带您深入了解这个 “Java 开发者专属的 AI 开发利器”,并对比原生 Spring AI 框架,解析其在企业级落地中的独特价值。
二、Spring AI vs Spring AI Alibaba:企业级 AI 开发的进化之路
1. 框架定位:从通用工具到云原生解决方案
|
特性 |
Spring AI(原生) |
Spring AI Alibaba(企业版) |
|
核心目标 |
简化 AI 功能集成的基础框架 |
云原生环境下的完整 AI 应用开发解决方案 |
|
模型支持 |
开源模型为主(Llama、OpenAI) |
通义大模型深度适配 + 开源模型兼容 |
|
基础设施集成 |
基础 WebFlux/REST 支持 |
Nacos 配置中心、RocketMQ 事件驱动、Sentinel 流量控制 |
|
企业级特性 |
基础 RAG 组件 |
全链路观测性、AB 测试、成本监控、边缘计算支持 |
|
开发范式 |
函数式 API 为主 |
流式 API+Fluent 链式调用 + 可视化工作流编辑器 |
2. 核心优势解析:为什么企业更需要 Spring AI Alibaba?
- 云服务深度绑定:内置通义大模型 SDK,支持一键配置百炼模型的多模态调用(文本 / 图像 / 语音),自动处理 Token 限额、流量调度等云端特性
- 云原生组件生态:与 Alibaba Cloud 原生组件无缝集成,例如:Nacos 实现动态 Prompt 模板管理RocketMQ 构建异步 AI 任务队列Sentinel 实现模型调用熔断降级Prometheus+Grafana 提供 AI 服务全链路监控
- 企业级开发工具链:可视化 Prompt 设计器(支持动态变量注入、JSON Schema 校验)智能 Agent 工作台(内置工具调用、对话记忆、任务分解引擎)RAG 全流程管理(文档解析、向量存储、检索增强一站式解决方案)
三、五大核心场景:Spring AI Alibaba 的企业级应用实践
场景一:智能客服系统 – 多轮对话 + 业务系统集成
技术方案:
- 通义大模型对接:使用ChatClient链式调用实现多模态交互
java
// 初始化通义聊天客户端
ChatClient chatClient = ChatClient.builder()
.model(ModelType.DASHSCOPE_CHAT)
.apiKey("your-access-key")
.build();
// 流式对话处理
Flux<ChatMessage> response = chatClient.chatStream(
ChatInput.builder()
.messages(Arrays.asList(
ChatMessage.systemMessage("你是电商客服助手"),
ChatMessage.userMessage("我买的鞋子尺码不合适怎么退换?")
))
.build()
);- 业务系统集成:通过FunctionCalling连接 ERP 系统
java
// 定义退换货API工具
FunctionTool returnTool = FunctionTool.builder()
.name("returnGoods")
.description("处理商品退换货请求")
.parameters(JsonSchema.of(ReturnRequest.class))
.function(returnRequest -> erpClient.processReturn(returnRequest))
.build();
// 智能Agent配置
AgentExecutor agent = AgentExecutor.builder()
.tools(returnTool, logisticsTool)
.memory(ConversationMemory.withMaxSize(10))
.build();
- 流量控制:Sentinel 实现每分钟 500 次模型调用限流
yaml
spring:
sentinel:
resource: dashscope-chat-api
limitApp: default
count: 500
grade: QPS
limitRefreshMs: 1000
场景二:文档问答系统 – 企业知识库 RAG 构建
技术实现:
- 文档预处理流水线:
java
DocumentPipeline pipeline = DocumentPipeline.builder()
.reader(OfficeDocumentReader.builder().build()) // 支持Word/PDF解析
.splitter(MarkdownSplitter.withMaxTokens(1000)) // 按语义分块
.embedding(通义EmbeddingModel.builder().build()) // 生成向量表明
.vectorStore(ElasticsearchVectorStore.builder() // 集成阿里云ES向量检索
.endpoint("http://es-host:9200")
.indexName("knowledge-base")
.build())
.build();
// 批量导入文档
pipeline.process(Paths.get("docs/"));
- 智能检索增强:
java
// 构建RAG查询流程
RagQueryEngine queryEngine = RagQueryEngine.builder()
.retriever(Retriever.fromVectorStore(vectorStore))
.llm(通义ChatModel.builder().build())
.promptTemplate(PromptTemplate.of(
"根据以下文档内容回答问题:{context}
问题:{question}"
))
.build();
// 执行问答
String answer = queryEngine.query("如何申请内部系统权限?");
- 性能优化:HiCache 实现高频问题缓存
java
@Cacheable(value = "faqCache", key = "#question")
public String getCachedAnswer(String question) {
return queryEngine.query(question);
}
场景三:多模态营销系统 – 图文生成 + 智能审核
技术架构:
- 文生图流水线:
java
// 初始化通义视觉模型
ImageGenerator imageGenerator = ImageGenerator.builder()
.model(ModelType.DASHSCOPE_IMAGE)
.build();
// 生成产品宣传图
ImageOutput image = imageGenerator.generate(
ImageInput.builder()
.prompt("红色运动鞋在绿色草地上的特写,阳光明媚")
.width(1024)
.height(768)
.build()
);
- 智能审核集成:
java
// 内容安全审核工具
AiTool moderationTool = AiTool.builder()
.name("contentModeration")
.description("检测文本内容是否合规")
.parameters(JsonSchema.of(ModerationRequest.class))
.function(text -> moderationClient.check(text))
.build();
// 营销文案审核流程
String copywriting = "限时折扣,错过再等一年!";
ModerationResult result = (ModerationResult) moderationTool.call(copywriting);
- 边缘部署支持:
java
// 边缘端轻量化模型加载
EdgeModelLoader loader = EdgeModelLoader.builder()
.modelPath("/edge-models/dashscope-light")
.memoryLimit(2GB)
.build();
LocalModel localModel = loader.load();
场景四:智能数据分析系统 – 报表生成 + 异常检测
关键技术点:
- 结构化输出解析:
java
// 定义报表生成POJO
public class SalesReport {
private String period;
private Map<String, Double> productSales;
private String trendAnalysis;
// getters/setters
}
// 模型输出自动映射
SalesReport report = chatClient.chatForObject(
ChatInput.builder()
.messages(ChatMessage.userMessage("生成2024年Q4销售报表"))
.structuredOutput(SalesReport.class)
.build()
);
- 实时数据流处理:
java
// RocketMQ事件驱动架构
@StreamListener(AI_EVENT_TOPIC)
public void processDataStream(AnalyzeRequest request) {
Flux.fromIterable(request.getDataPoints())
.window(100) // 每100条数据分组
.flatMap(dataWindow -> aiAnalysisService.analyze(dataWindow))
.subscribe(result -> sendToDashboard(result));
}
- 成本监控:
java
// 模型调用成本统计
MetricsTracker tracker = MetricsTracker.builder()
.modelType(ModelType.DASHSCOPE_CHAT)
.apiCalls(100)
.tokensUsed(5000)
.build();
CostEstimator.calculate(tracker); // 自动生成成本报表
场景五:智能 Agent 平台 – 跨系统任务自动化
核心组件:
- 工具调用引擎:
java
// 定义多工具Agent
Tool[] tools = {
new HttpTool("apiLookup", "调用HTTP API获取数据"),
new DatabaseTool("dbQuery", "查询数据库"),
new FileTool("fileOps", "文件操作")
};
Agent agent = new DefaultAgent(tools, new ReActPlanner());
// 执行复合任务
String result = agent.execute("查询2024年销售额前10的产品并保存到文件");
- 对话记忆管理:
java
// 上下文记忆配置
ConversationMemory memory = ConversationMemory.builder()
.maxMessages(20) // 保留最近20轮对话
.sessionIdGenerator(UUID::randomUUID)
.build();
// 记忆注入
ChatInput input = ChatInput.builder()
.messages(memory.getHistory())
.userMessage("继续之前的数据分析")
.build();
- 工作流编排:
java
// 可视化工作流定义
WorkflowDefinition workflow = Workflow.builder()
.step("数据获取", httpTool::call)
.step("数据清洗", dataCleaner::process)
.step("模型预测", model::infer)
.build();
// 工作流执行
WorkflowExecutor.execute(workflow, inputData);
四、快速上手:从环境搭建到生产部署的全流程指南
1. 环境准备
依赖配置(Maven)
xml
<dependency>
<groupId>com.alibaba.spring</groupId>
<artifactId>spring-ai-alibaba-boot-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>dashscope-sdk</artifactId>
<version>2.1.0</version>
</dependency>
阿里云账号配置
yaml
spring:
ai:
alibaba:
dashscope:
access-key: your-access-key
secret-key: your-secret-key
endpoint: https://dashscope.aliyuncs.com
2. 核心组件快速入门
① Prompt 模板管理
java
// 动态Prompt生成
PromptTemplate template = PromptTemplate.builder()
.prompt("用户问题:{question}
上下文:{context}
请用JSON格式回答")
.build();
Map<String, Object> params = new HashMap<>();
params.put("question", "如何重置密码");
params.put("context", "重置密码步骤...");
String finalPrompt = template.render(params);
② RAG 核心流程
java
// 文档解析
Document document = new OfficeDocumentReader().read("user-manual.pdf");
// 文本分块
List<Document> chunks = new MarkdownSplitter(1000).split(document);
// 向量生成
List<Embedding> embeddings = new DashScopeEmbeddingModel().embed(chunks);
// 存储到向量库
vectorStore.save(chunks, embeddings);
③ 智能 Agent 构建
java
// 定义工具
WebSearchTool searchTool = new WebSearchTool("webSearch", "搜索网络信息");
// 初始化Agent
AgentExecutor agent = AgentExecutor.builder()
.tools(searchTool, calculatorTool)
.memory(new ConversationMemory())
.llm(new DashScopeChatModel())
.build();
// 执行对话
String response = agent.chat("今天北京的天气如何?");
3. 生产环境优化
① 流量治理
java
// Sentinel规则动态加载
SentinelConfigurer configurer = new SentinelConfigurer();
configurer.addFlowRule(FlowRule.of(
"dashscope-api",
ResourceTypeConstants.COMMON_WEB,
1000,
Grade.QPS,
new FlowRuleStrategy()
));
② 观测性增强
java
// 集成Prometheus指标
MicrometerRegistry registry = new PrometheusMeterRegistry();
registry.gauge("ai.model.latency", new Timer());
registry.counter("ai.api.calls", "model", "dashscope");
// 日志增强
LoggingHandler loggingHandler = new LoggingHandler(
(input, output) -> log.info("AI调用: {} -> {}", input, output)
);
chatClient.addHandler(loggingHandler);
③ 边缘计算部署
java
// 边缘端模型加载策略
EdgeModelManager manager = EdgeModelManager.builder()
.modelRepository(new LocalModelRepository("/edge-models"))
.updateStrategy(ModelUpdateStrategy.SCHEDULED)
.build();
// 离线调用逻辑
LocalModel model = manager.getModel("lightweight-model");
String result = model.predict("边缘端推理请求");
五、企业级最佳实践:从架构设计到团队协作
1. 架构设计原则
- 分层架构:
plaintext
应用层(业务逻辑)
├─ 服务层(AI能力封装)
│ ├─ 模型服务(通义大模型/开源模型)
│ ├─ RAG服务(文档处理/向量检索)
│ └─ Agent服务(工具调用/任务分解)
├─ 基础设施层(云原生组件)
│ ├─ 配置中心(Nacos)
│ ├─ 消息队列(RocketMQ)
│ └─ 监控体系(Prometheus+Grafana)
└─ 数据层(向量存储/业务数据库)- 多模型路由:通过ModelRouter实现自动模型切换
java
ModelRouter router = ModelRouter.builder()
.route("default", ModelType.DASHSCOPE_CHAT)
.route("low-cost", ModelType.OPENAI_GPT3_5)
.fallback(ModelType.LOCAL_MODEL)
.build();
2. 团队协作提议
- 角色分工:AI 工程师:专注 Prompt 工程、模型调优、RAG 流程设计Java 开发:负责云原生集成、业务逻辑开发、API 网关设计数据科学家:处理文档清洗、向量空间优化、模型评估
- 开发工具链:使用可视化 Prompt 设计器进行模板管理通过 Swagger 生成 AI 接口文档利用 GitOps 进行模型配置版本控制
3. 成本控制策略
- Token 优化:使用TokenCalculator预测调用成本
java
int tokens = TokenCalculator.calculate(prompt, ModelType.DASHSCOPE_CHAT);
if (tokens > 4096) {
throw new CostException("Token超过限额");
}
- 资源调度:夜间自动切换为低成本模型
- 用量监控:设置每日调用量预警阈值
六、未来展望:Spring AI Alibaba 的技术演进方向
1. 技术路线图
- 多模态深度融合:支持图文混合输入、语音交互全流程处理
- 联邦学习集成:实现跨部门数据隐私保护下的模型训练
- Serverless 化:基于函数计算(FC)的无服务器 AI 部署方案
- 行业解决方案:金融 / 医疗 / 制造等垂直领域的专属工具包
2. 生态建设计划
- 推出官方认证的 AI 应用市场,共享行业最佳实践
- 构建开发者社区,定期举办 AI Hackathon
- 发布企业级安全白皮书,涵盖数据加密、模型权限管理
结语:开启 Java 企业级 AI 开发的新纪元
Spring AI Alibaba 的出现,标志着 Java 生态在企业级 AI 开发领域的全面突破。它不仅解决了 “如何快速接入大模型” 的基础问题,更构建了一套完整的云原生 AI 开发体系,让 Java 开发者能够在熟悉的技术栈中,实现从简单 API 调用到复杂 RAG 系统、智能 Agent 平台的全场景开发。
对于企业而言,选择 Spring AI Alibaba 意味着获得:
- 阿里云通义大模型的深度优化支持
- 成熟的云原生基础设施集成能力
- 覆盖全开发生命周期的工具链
- 企业级的可靠性、安全性和可观测性
随着生成式 AI 技术的持续演进,Spring AI Alibaba 将成为企业数字化转型的核心驱动力,协助更多 Java 开发者在 AI 时代释放无限创新潜力。目前,就让我们一起开启这场云原生 AI 开发的革命之旅,用代码定义企业级 AI 应用的未来!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











