
doi:10.1093/molbev/msu300
iqtree简单来说就是一种作者新提出来的一种进行最大似然分析的方法,全文通过和RAxML以及PhyML的性能比较以及最高似然值的反问的比较展开,采用了爬山方法和随机扰动方法,并证明了其二者结合可以在时间上有效的实现查找最大似然(ML)树。
文章第一通过一样的运行时间,来比较iqtree和RAxML以及PhyML,令其分析DNA序列个氨基酸,分别记录其分析的速度以及最大似然性的大小来进行分析,各自运行十次,然后,我们比较了IQ-Tree和其他两个程序在每一次对齐中产生的树的平均对数似然。
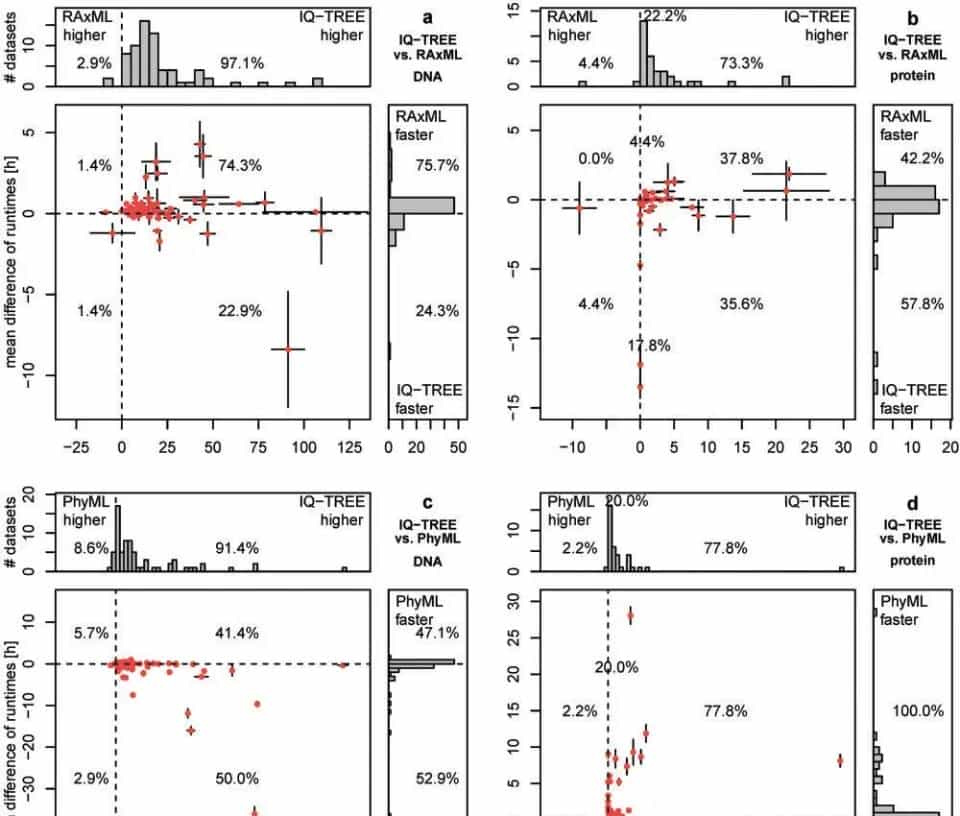
紧接着对不同运行时间进行了比较,在比较最大似然效果的同时,还进行了各自运行时间的比较,在默认和随机起始树选项下,IQ-Tree per-formed都优于Phyml。
在讨论部分进行了NNI的引入,IQ-Tree的良好性能的一个解释可能是随机NNI的引入。 局部最优树的这种随机扰动有助于逃避局部最优。 然后对扰动树进行优化。总之,IQ-Tree是一个时间和搜索效率都很高的ML树重建程序。由于IQ-Tree的效果并不总是优于其他两个,因此作者提议将三个方法组合在一起使用。至于最佳模型选择的modelfinder我估计那篇文献就得明天看了,天太冷了,我要去烧炉子了
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











