一、Streamlit库简介
Streamlit 是一个用于快速构建数据科学和机器学习 Web 应用的 Python 库。它允许开发者用简单的 Python 脚本创建交互式仪表盘,无需前端开发经验。官网地址:https://streamlit.io/
1. 核心特性
✅ 快速搭建UI:
- 用 Python 代码直接生成交互式组件(按钮、滑块、图表等)。
- 无需 HTML/CSS/JavaScript。
✅ 实时更新:
- 用户操作自动触发脚本重新运行,即时显示新结果。
✅ 丰富组件:
- 支持表格(st.dataframe)、图表(st.plotly_chart)、地图(st.map)、Markdown(st.markdown)等。
✅ 集成机器学习库:
- 直接与 PyTorch、TensorFlow、Scikit-learn 等协同工作。
✅ 部署便捷:
- 支持一键部署到 Streamlit Community Cloud。
2. 适用场景
- 数据可视化仪表盘
- 机器学习模型演示
- 交互式报告生成
- 快速原型开发
3.与其他Web框架比较
|
框架 |
优点✅ |
缺点❌ |
典型场景 |
|
Streamlit |
|
|
机器学习演示、数据报告仪表盘、快速原型。 |
|
Django |
|
|
电商平台、内容管理系统(CMS)、企业级应用。 |
|
Flask |
|
|
RESTful API、小型Web应用、IoT后端。 |
|
FastApi |
|
|
微服务、实时API、高频交易后端。 |
所以,该如何选择呢?
- 「我要快速展示数据结果」 → Streamlit
- 「我要开发一个完整的企业级网站」 → Django
- 「我需要轻量级API或自定义架构」 → Flask
- 「我要构建高性能API/微服务」 → FastAPI
二、安装streamlit
1.安装streamlit 库
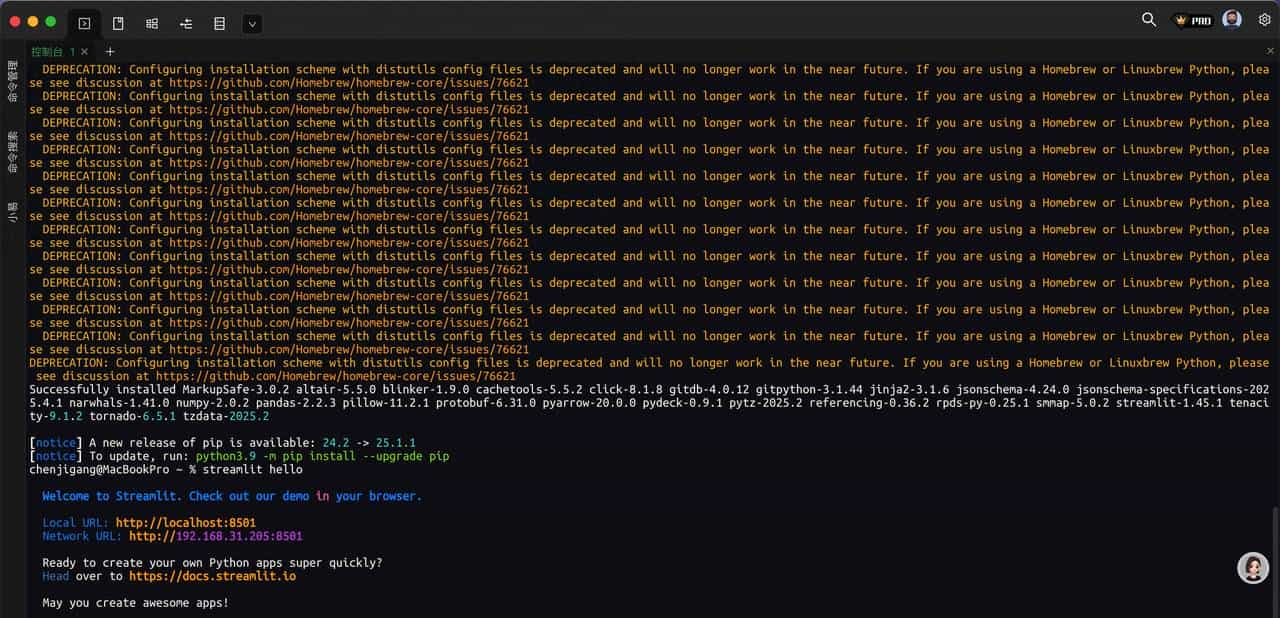
pip install streamlit2.验证streamlit 是否安装成功
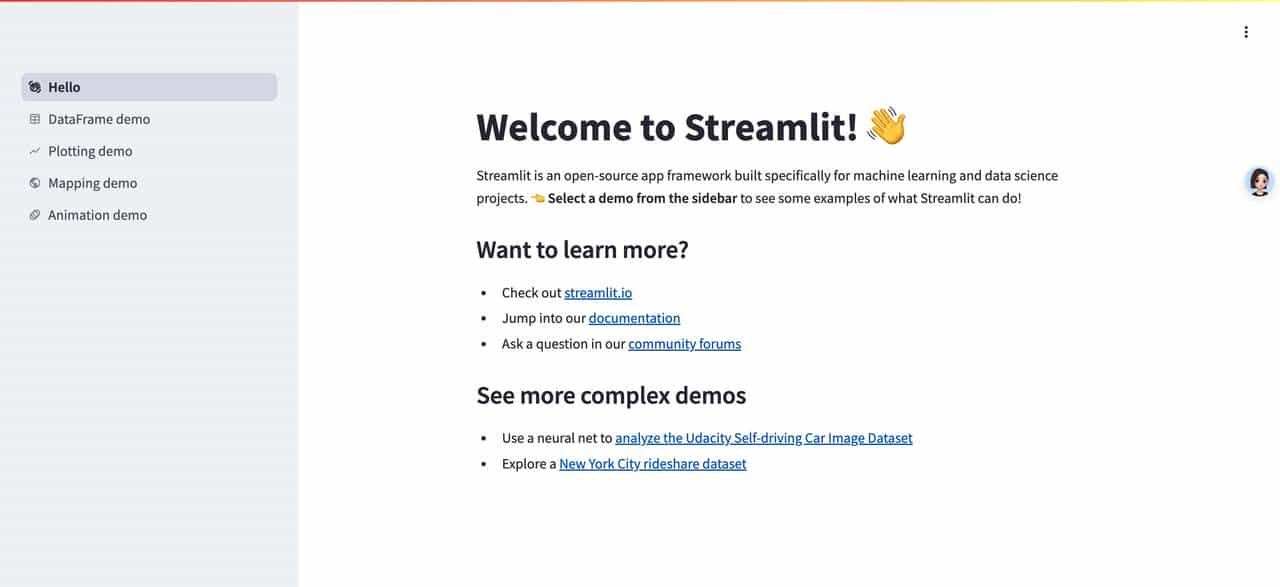
streamlit hello执行成功后,会给出如下提示,并自动在浏览器打开streamlit本地服务主页
三、运行第一个程序
按照惯例,运行第一个程序-hello world。
例如:my_data.csv是以下数据
index,salary
1,8000
2,13000
3,10000
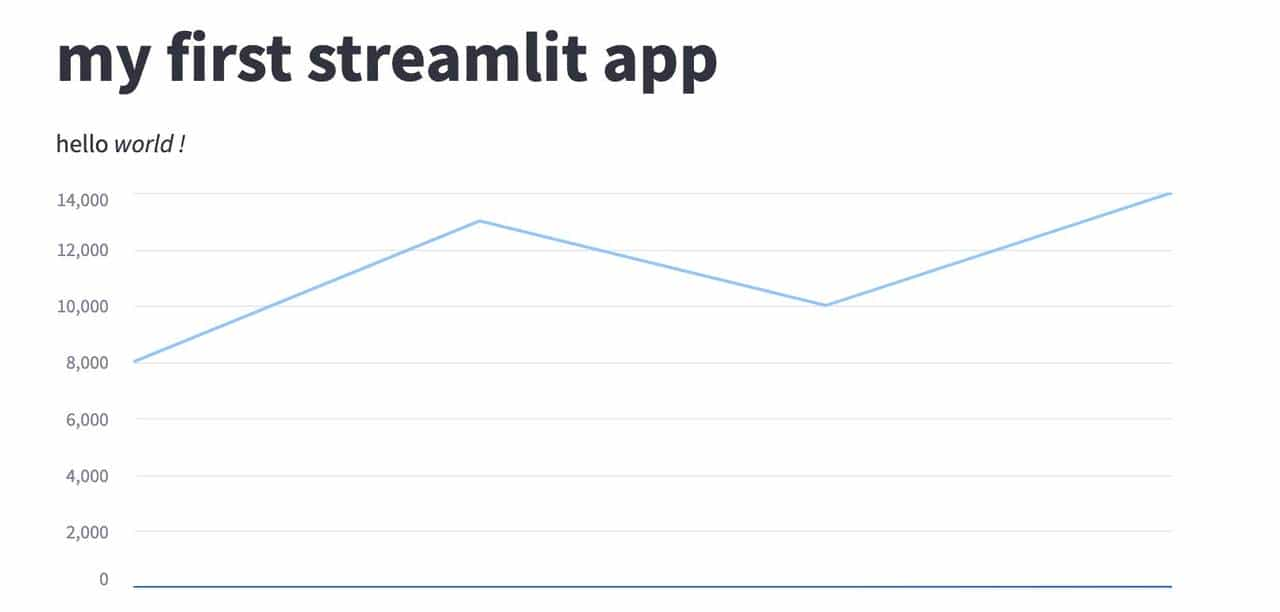
4,14000编写程序代码:
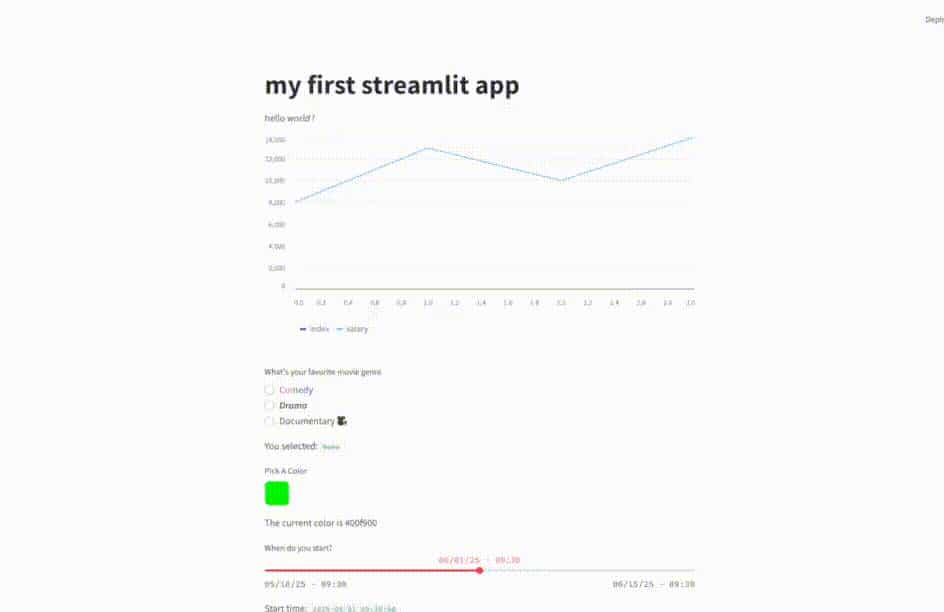
import streamlit as st
import pandas as pd
st.write("""
# my first streamlit app
hello *world !*
""")
df = pd.read_csv("my_data.csv")
st.line_chart(df)运行程序:
streamlit hello_world.py浏览器展示效果如下:
四、streamlit API
官网提供了大量API调用示例,例如:输入文本、选择日期、按钮操作、上传文件等等,开箱即用。
API文档地址:
https://docs.streamlit.io/develop/api-reference
① 单选
import streamlit as st
genre = st.radio(
"What's your favorite movie genre",
[":rainbow[Comedy]", "***Drama***", "Documentary :movie_camera:"],
index=None,
)
st.write("You selected:", genre)
② 选择颜色
import streamlit as st
color = st.color_picker("Pick A Color", "#00f900")
st.write("The current color is", color)
③ 滑动选择时间段
start_time = st.slider(
"When do you start?",
value=datetime(2025, 6, 1, 9, 30),
format="MM/DD/YY - hh:mm",
)
st.write("Start time:", start_time)
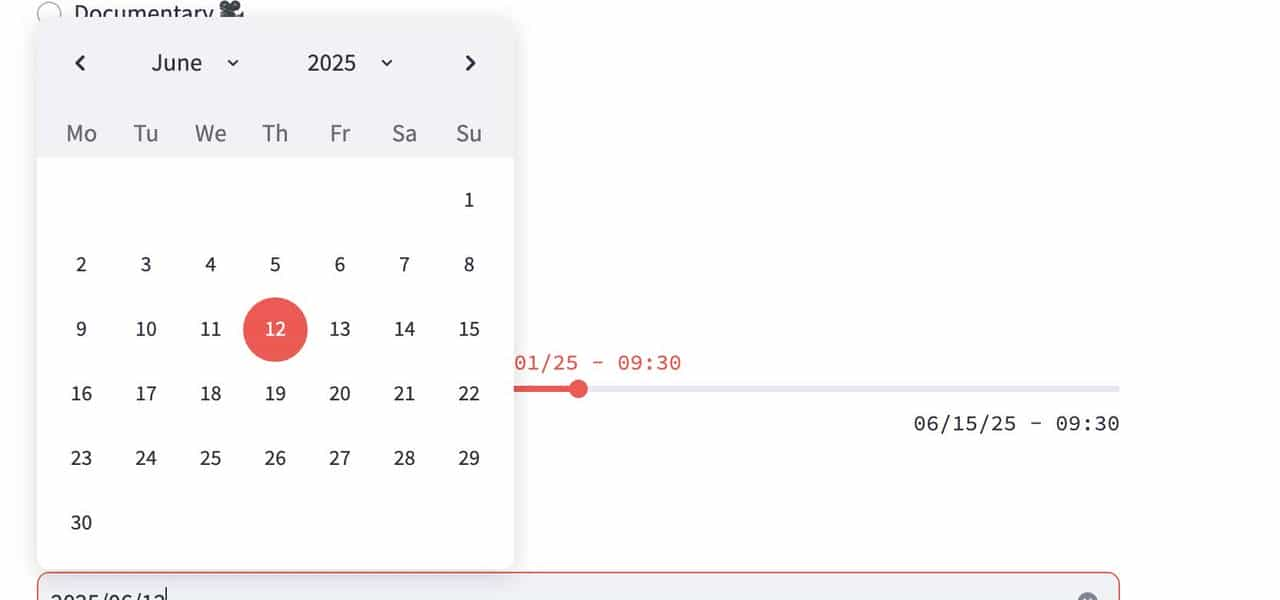
④ 选择日期
import datetime
import streamlit as st
d = st.date_input("When's your birthday", value=None)
st.write("Your birthday is:", d)初始值为None,选择某个日期后,底部会显示所选择的日期:
⑤ 图表展示
import streamlit as st
from vega_datasets import data
source = data.barley()
st.bar_chart(source, x="year", y="yield", color="site", stack=False)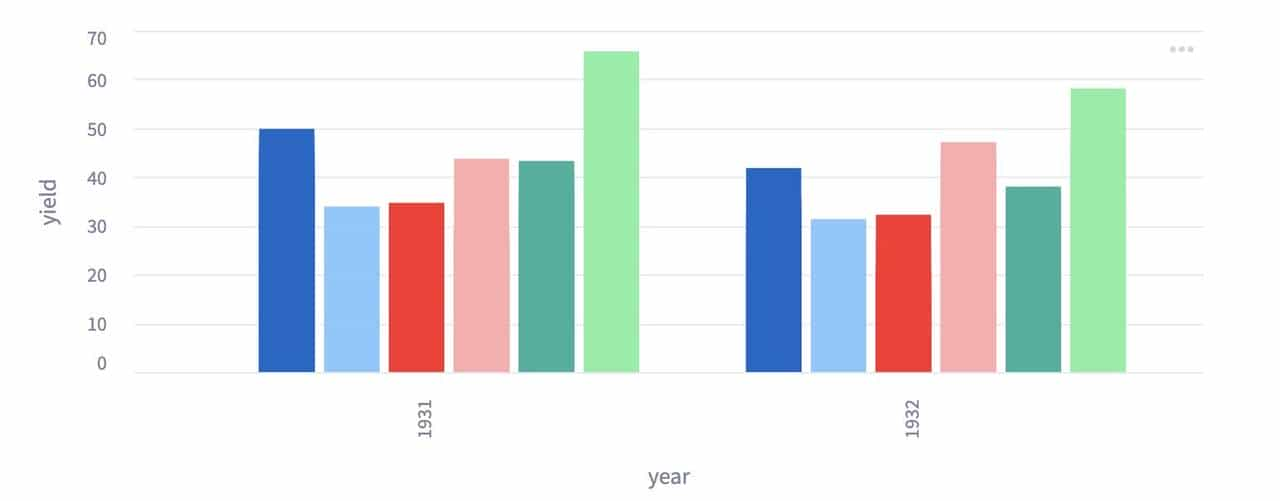
⑥ 上传文件交互
import streamlit as st
uploaded_files = st.file_uploader(
"Choose a CSV file", accept_multiple_files=True
)
for uploaded_file in uploaded_files:
bytes_data = uploaded_file.read()
st.write("filename:", uploaded_file.name)
st.write(bytes_data)
⑦ 输入文本
输入区域在左侧栏
import streamlit as st
with st.sidebar:
messages = st.container(height=300)
if prompt := st.chat_input("Say something"):
messages.chat_message("user").write(prompt)
messages.chat_message("assistant").write(f"Echo: {prompt}")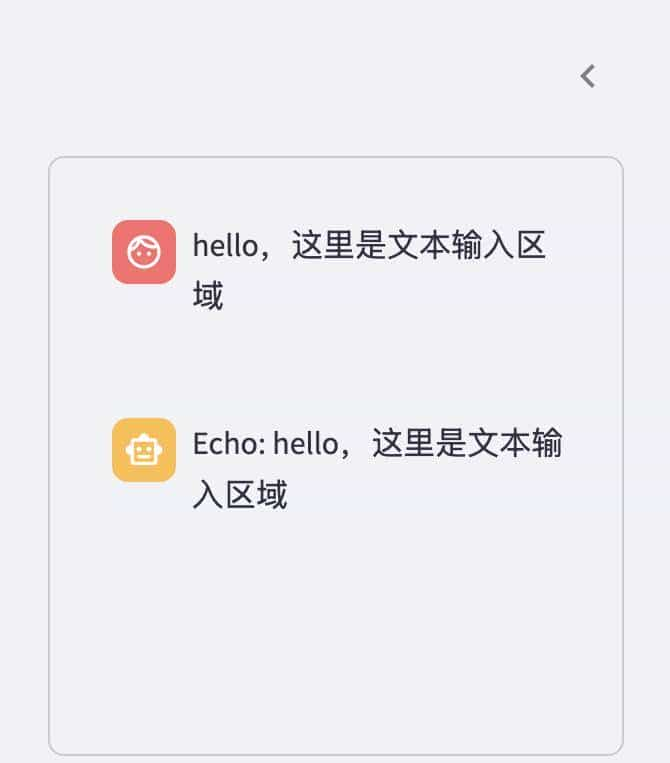
输入区域在居中
import streamlit as st
prompt = st.chat_input(
"Say something and/or attach an image",
accept_file=True,
file_type=["jpg", "jpeg", "png"],
)
if prompt and prompt.text:
st.markdown(prompt.text)
if prompt and prompt["files"]:
st.image(prompt["files"][0])
⑧ 按钮操作
import streamlit as st
left, middle, right = st.columns(3)
if left.button("Plain button", use_container_width=True):
left.markdown("You clicked the plain button.")
if middle.button("Emoji button", icon="", use_container_width=True):
middle.markdown("You clicked the emoji button.")
if right.button("Material button", icon=":material/mood:", use_container_width=True):
right.markdown("You clicked the Material button.")
⑨总体效果
下面是一个总体效果演示:
五、基于千问大模型开发一个Web应用
1.开发第一版AI应用
与大模型交互示例,这里基于千问大模型。
① 安装大模型SDK
pip install streamlit dashscope # Dashscope是阿里云千问的官方SDK② 前往阿里云官网,申请千问大模型API Key,首次注册会赠送100W tokens
③ 创建 .streamlit/secrets.toml 文件,填写API Key
# .streamlit/secrets.toml
QW_API_KEY = "sk-xxxxxxxxxxxxxxxx"④ 编写Web应用代码
import streamlit as st
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
# 标题和说明
st.title(" 千问大模型对话演示")
st.caption("Streamlit + 阿里云千问(Qwen)的简易问答交互")
# 从secrets.toml安全读取API Key
api_key = st.secrets.get("QW_API_KEY", "")
if not api_key:
st.error("未检测到API Key!请检查secrets.toml配置。")
st.stop()
# 初始化对话历史(存储在session_state中)
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "system", "content": "你是一个乐于助人的AI助手。"}
]
# 展示历史对话
for msg in st.session_state.messages:
if msg["role"] != "system": # 不显示系统提示
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# 用户输入
if prompt := st.chat_input("输入你的问题..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 调用千问API生成回答
with st.spinner("千问正在思考..."):
response = Generation.call(
model="qwen-max", # 千问Max模型
api_key=api_key,
messages=st.session_state.messages,
result_format="message" # 返回结构化消息
)
# 提取AI回复内容
ai_response = response.output.choices[0]["message"]["content"]
# 更新对话历史
st.session_state.messages.append({"role": "assistant", "content": ai_response})
# 展示AI回复
with st.chat_message("assistant"):
st.markdown(ai_response)

使用效果:
此处为语雀视频卡片,点击链接查看:streamlit&千问大模型示例.mp4
2.第二版:加入模型选择和流式输出
从视频效果来看,使用streamlit与大模型结合,能够实现简单的问答式交互。美中不足的是:
- 没办法选择模型类型,列如千问的其他model;
- 思考时间比较长,而且要等完全响应完成后再一股脑地把结果内容展示给用户,体验超级不好。
所以,这里再来改造一下,加入模型选择和流式输出。
① 添加模型选择
model = st.selectbox("选择模型", ["qwq-32b", "qwq-plus"])② 加入流式输出
response = Generation.call(stream=True, ...)
for chunk in response:
st.write(chunk.output.choices[0]["message"]["content"])完整代码如下:
import streamlit as st
from dashscope import Generation
import time
# 标题设置
st.title(" 千问大模型-流式对话演示")
st.caption("Streamlit + 阿里云千问(Qwen)的流式问答交互")
# 从secrets.toml安全读取API Key
api_key = st.secrets.get("QW_API_KEY", "")
if not api_key:
st.error("未检测到API Key!请检查secrets.toml配置。")
st.stop()
# 初始化对话历史
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "system", "content": "你是一个回答简洁的AI助手,每次回复不超过3句话。"}
]
# 展示历史对话(跳过system prompt)
for msg in st.session_state.messages:
if msg["role"] != "system":
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
model = st.selectbox("选择模型", ["qwq-32b", "qwq-plus"])
# 用户输入
if prompt := st.chat_input("请输入问题:"):
# 添加用户消息到历史
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 创建AI回复的空容器(后续动态更新)
with st.chat_message("assistant"):
response_placeholder = st.empty() # 占位符用于流式更新
full_response = "" # 累积完整回复
# 调用千问流式API
responses = Generation.call(
model=model,
api_key=api_key,
messages=st.session_state.messages,
stream=True, # 关键参数:启用流式
temperature=0.7
)
# 逐个处理流式响应块
for chunk in responses:
word = chunk.output.choices[0]['message']['content'] # 获取当前片段
if word: # 过滤空内容
full_response += word
response_placeholder.markdown(full_response + "▌") # 光标动画
time.sleep(0.05) # 控制输出速度(模拟打字效果)
# 移除光标并显示最终结果
response_placeholder.markdown(full_response)
# 将AI回复添加到对话历史
st.session_state.messages.append({"role": "assistant", "content": full_response})改造后的使用效果如下:
此处为语雀视频卡片,点击链接查看:streamlit流式交互示例.mp4
注意啊,代码在初始化对话时加入了回答限制,所以每次回答得都很简洁,只有三句话,如果不想做限制的可以去掉:

3.第三版:加入中断按钮
可能细心的小伙伴会发现,如果回答内容过长,或是问题问错了,如何终止回答呢?这时,就需要加入一个中断按钮。
① 先在用户输入时初始化中断标志位:
st.session_state.abort_generation = False # 重置中断标志② 再在AI回复时加入中断按钮
# 添加中断按钮列
col1, col2 = st.columns([5,1])
with col2:
if st.button("✋ 停止生成", key="stop_btn"):
st.session_state.abort_generation = True③ 最后在流式处理响应的循环体中加入中断的判断
if st.session_state.abort_generation:
full_response += "【用户中断】"
break最终实现效果如下:

小结
以上就是利用Python的streamlit库结合千问大模型本地开发的一款简单的AI交互式应用。当然,还有许多可以优化的地方,例如:上传文件;也可以基于其他大模型、例如DeepSeek进行开发。
我新组建了一个测试开发学习交流群,持续分享测试开发方面知识,更有累计超过1000G的AI大模型等相关资料,欢迎私聊我、入群免费领取资料


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...