换句话说,thread_local 的原意就是把数据按线程“分格子”放好,开一条新线程,就多出一块属于它自己的存储空间。好处很明显:不同线程之间不会由于写同一份变量而相互干扰,代码写起来也省心不少。但是代价也摆在那儿,不是白来的摇钱树。

先说开销这茬。每开一条线程,系统都得给它分配一块 TLS(线程本地存储),线程多了,内存消耗就按条线性往上窜。别以为只有你定义的几个变量占地儿,编译器和链接器会为了对齐加上 padding,一个看着小巧的结构体,最终占的内存可能比想象的大。时间上也费事儿:访问 thread_local 变量时,不像直接读一个全局地址那样方便,需要先通过一个专门寄存器(x86 平台上常见的是 %fs 或 %gs)拿到线程的基址,然后再加偏移去读写,这比直接寻址多了一次间接。还有一点容易忽略:线程一创建,运行时要把这块 TLS 的内存申请好并把初始值拷过去;如果你放进去的是带构造函数的复杂对象,这些构造逻辑会在每个线程里跑一次,线程创建成本自然被抬高。最容易踩坑的场景就是频繁起短命线程,同时又把大量 thread_local 对象塞进去,开销会被放大好几倍。
把幕后具体流程说清楚。程序一启动,主线程会被分配一块 TLS 区,初始化数据(如果有)会被拷贝入内存,运行时再把这块区的基址写到相应的寄存器里。每当用 pthread_create 起新线程,运行时就为它申请新的 TLS,把那些需要的初始值一并拷进去,然后把新线程的基址写进该线程的寄存器。线程切换时,内核或运行时会把寄存器值换掉,让被调度的线程用自己的基点去访问 TLS。底层这堆 TLS 块一般由线程控制块(TCB)管理,TCB 里记着 TLS 的起始位置和其他线程相关信息。
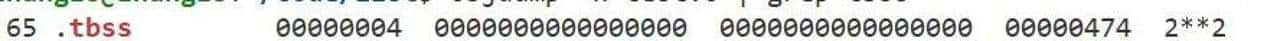
编译器和链接器那边也动了不少手脚。碰到 thread_local 变量,编译器会把它们分到特殊段里,一般叫 .tdata(有初始值的)和 .tbss(没初始化的,类似普通的 .bss)。生成的代码不会把变量地址直接写死,而是用偏移指令或者专门的 TLS 访问序列。链接器最后把这些段的偏移和布局整理到可执行文件或动态库里。运行时访问时,有的会直接像 “%fs:offset” 读,有的在动态 TLS 场景下会先调用一个运行时函数(像 __tls_get_addr 之类)来算出真实地址。目标就是把模块里的变量映射到当前线程那份独立的存储里。
说点实际用法和要注意的细节。不少人会写成这样:thread_local int local_val = 0; 这句的意思很直白:每个线程都有一份 local_val,互不干涉。放在线程私有缓存、每线程的随机数上下文、统计计数器这种场景,thread_local 的确 能把代码弄得更干净,也能少用锁。不过别忘了两点:一是如果你的变量是复杂类型、有构造函数、析构动作,那么每个线程都会去构造一遍,线程创建就要多跑这道工序;二是在对延迟和性能特别敏感的热路径里,额外的一次寄存器间接和偏移计算可能被频繁访问放大,特别是 tight loop 里,可能得好好权衡。

还有些不太明显的坑。动态库里如果有 TLS 定义,链接器要把各个模块的 TLS 段拼起来,并给每个线程算出每个模块变量的最终偏移。换句话说,用了许多第三方库或在运行时动态加载模块时,TLS 布局会变复杂,线程创建时可能需要额外的工作来初始化这些分散的 TLS 区块。再有从缓存角度思考:每个线程独立的内存块会让总的内存占用上升,影响 TLB(地址变换缓冲)的命中率,间接对性能带来影响。
给出点实战提议:别把 thread_local 当成万能钥匙。适合它的场景是那些每线程都要、体积小、构造轻的东西,列如每线程的小缓存、统计数据或 RNG 的状态。如果遇到大量短命线程,或者每个线程都要构造很重的对象,思考把线程改成线程池的模式,复用线程,那样 TLS 的初始化成本就不会反复爆表。还有一种折中办法是把对象放到线程对象的成员里,由你手动决定生命周期;或者做按需延迟初始化,需要用到时再分配,避免线程启动时一口气造一堆东西。
举个直观的例子:同一段程序里,如果你在两个线程里打印同一个 thread_local 变量的地址,一般会看到两条不同的地址 —— 这就是最简单明了的证据,说明每个线程的确 拿到的是独立的一份。设计时要记住,便利性是有代价的,别让这笔“便利账”变成性能或内存上的糊涂账。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...