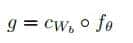在 AI 编程后端开发领域,大模型技术正从 “单模态专属” 向 “多模态融合” 全面升级。作为支撑业务智能化的核心技术,多模态大模型打破了传统文本、图像、语音等数据类型的孤立壁垒,实现了跨模态信息的统一理解与生成 —— 这意味着后端开发者需要面对更复杂的数据处理场景、接口设计需求和性能优化挑战。
从行业落地来看,多模态技术已广泛应用于智能客服(语音 + 文本交互)、内容审核(图像 + 文本检测)、智能办公(文档 + 表格 + 图片解析)等后端场景。根据技术调研机构数据,2024 年以来,互联网企业多模态相关后端岗位招聘量同比增长 128%,但具备实战能力的开发者仅占 37%,供需缺口直接推动多模态成为后端开发的 “必备技能”。
对于互联网软件开发人员而言,掌握多模态技术不仅能拓宽技术边界,更能解决传统单模态模型无法覆盖的业务痛点:列如传统文本大模型无法处理图像数据的局限、语音接口与文本接口难以协同的问题等,成为技术竞争力的核心加分项。
多模态大模型的核心技术逻辑
多模态大模型的本质是 “跨模态信息的统一表征与交互”,其底层原理可拆解为三大核心模块,后端开发者需重点理解:
1. 模态输入编码模块
不同模态数据(文本、图像、语音、视频等)的结构差异巨大:文本是序列数据,图像是像素矩阵,语音是波形信号。编码模块的核心作用是将这些异构数据转化为计算机可理解的 “统一向量表征”。
- 文本编码:沿用 Transformer 架构(如 BERT、GPT 的编码器),将文字转化为语义向量;
- 图像编码:采用 CNN(卷积神经网络)或 Vision Transformer(ViT),提取图像的视觉特征向量;
- 语音编码:通过 MFCC(梅尔频率倒谱系数)转化为特征向量,再经 Transformer 编码优化;
- 关键技术点:后端开发需关注编码后的向量维度一致性(一般统一为 768 维或 1024 维),否则会导致后续融合模块报错。
2. 跨模态融合模块
这是多模态技术的核心难点,目的是让不同模态的向量 “相互理解、协同工作”。目前主流的融合方案有三种,后端开发需根据业务场景选择:
- 早期融合(Pre-fusion):在编码后直接将多模态向量拼接 / 相加,结构简单但融合深度不足,适合轻量型场景(如文本 + 小图识别);
- 中期融合(Cross-fusion):通过跨注意力机制(Cross-Attention)让不同模态向量相互交互,列如文本向量关注图像的关键区域、图像向量呼应文本的核心语义,是目前最常用的方案(如 GPT-4V、文心一言多模态版均采用);
- 晚期融合(Post-fusion):各模态分别完成任务后,再融合结果,适合对单一模态精度要求高的场景(如医疗影像 + 文本报告联合诊断)。
3. 模态输出生成模块
根据业务需求生成目标模态数据,列如输入 “文本 + 图像” 输出 “总结文本”、输入 “语音 + 文本” 输出 “翻译语音” 等。输出模块需与输入模态对应:
- 文本输出:采用 Transformer 解码器(如 GPT 的自回归生成);
- 图像输出:采用 GAN(生成对抗网络)或扩散模型;
- 语音输出:结合 TTS(文本转语音)技术;
- 关键技术点:后端开发需关注输出模块与融合模块的接口适配,避免向量维度不匹配导致的生成失败。
后端开发者如何快速落地多模态接口开发?
结合后端开发的实际工作场景,以 “文本 + 图像输入,生成结构化 JSON 结果” 为例(如商品图像 + 描述文本,输出商品分类、价格区间、属性标签),提供基于开源多模态模型的实战步骤:
1. 技术选型与环境搭建
模型选择:优先选用成熟开源模型(降低开发成本),推荐:
- 轻量型:BLIP-2(支持文本 + 图像,部署门槛低,适合中小规模后端服务);
- 高性能:LLaVA(基于 Llama 2+ViT,精度接近商用模型,需 GPU 支持);
开发环境:Python 3.8+、PyTorch 2.0+、FastAPI(接口开发)、Redis(缓存多模态向量,提升响应速度);
部署依赖:若采用 GPU 部署,需配置 CUDA 11.7+;CPU 部署提议开启量化(INT8),否则响应延迟会超过 3 秒(后端接口一般要求延迟≤500ms)。
2. 核心接口开发步骤
(1)模型加载与初始化
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
# 加载处理器(负责编码文本+图像)和模型
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16,
device_map="auto" # 自动分配GPU/CPU
)(2)多模态输入处理接口
from fastapi import FastAPI, UploadFile, File, Body
from PIL import Image
import json
app = FastAPI(title="多模态文本+图像处理接口")
@app.post("/multimodal/process")
async def process_multimodal(
image: UploadFile = File(...), # 图像输入
text: str = Body(..., description="文本描述") # 文本输入
):
# 1. 处理图像:转换为PIL格式
image = Image.open(image.file).convert("RGB")
# 2. 编码文本+图像(统一转化为模型可接受的输入格式)
inputs = processor(
images=image,
text=text,
return_tensors="pt"
).to("cuda", torch.float16) # 移至GPU(CPU环境移除该参数)
# 3. 模型推理:生成结构化结果(通过提示词引导输出JSON)
prompt = f"基于输入的图像和文本,输出商品信息JSON:{{'category':'','price_range':'','attributes':[]}}"
outputs = model.generate(
**inputs,
text=prompt,
max_new_tokens=200, # 限制输出长度
temperature=0.7 # 控制生成随机性
)
# 4. 解码结果并返回
result = processor.decode(outputs[0], skip_special_tokens=True)
return {"code": 200, "data": json.loads(result)}(3)接口性能优化(后端核心关注点)
- 向量缓存:将高频输入的图像 / 文本编码向量存入 Redis,有效期 1 小时,避免重复编码(可降低 30% 响应时间);
- 批量处理:针对批量请求(如批量商品识别),采用异步批量编码 + 推理,提升吞吐量;
- 量化部署:使用 TensorRT 对模型进行 INT8 量化,GPU 内存占用降低 50%,推理速度提升 2-3 倍;
- 容错处理:添加模态输入校验(如图像格式校验、文本长度限制),避免非法输入导致模型崩溃。
3. 接口测试与验证
测试用例:输入 “红色连衣裙图像”+ 文本 “夏季透气款,价格 200-300 元”,预期输出:
{
"category": "女装-连衣裙",
"price_range": "200-300元",
"attributes": ["红色", "夏季", "透气"]
}性能指标:GPU(NVIDIA A10)环境下,单请求响应时间≤300ms,QPS≥50;CPU 环境(16 核 32G)下,响应时间≤1.5s,QPS≥10。
经验总结:后端开发落地多模态的避坑指南
1. 技术选型避坑
- 不要盲目追求大模型:中小规模后端服务优先选择轻量型模型(如 BLIP-2、MiniGPT-4),大模型(如 GPT-4V、Claude 3 多模态版)API 调用成本高(单请求 0.1-0.5 元),且延迟高(≥1s),不适合高并发场景;
- 优先选择支持中文的模型:部分开源模型(如 LLaVA 原版)中文支持较差,提议选择中文优化版(如 LLaVA-Chinese、ChatGLM-4 多模态版),避免语义理解偏差。
2. 开发实现避坑
- 编码维度一致性:不同模态编码后的向量维度必须统一,否则融合模块会报 “shape mismatch” 错误,提议在编码后添加维度校验逻辑;
- 显存 / 内存控制:图像编码对显存占用较大,后端部署时需限制单请求图像分辨率(提议≤1024×1024),否则容易导致 OOM(内存溢出);
- 接口兼容性:多模态接口需支持多种输入格式(如图像支持 JPG/PNG/WebP,文本支持 UTF-8 编码),避免因格式问题导致调用失败。
3. 落地进阶提议
- 从简单场景切入:后端开发者首次落地可选择 “文本 + 图像” 的轻量场景(如内容标签生成、简单图像描述),积累经验后再挑战复杂场景(如视频 + 文本交互);
- 关注模型迭代:多模态技术更新快,提议通过 Hugging Face、GitHub 关注最新开源模型,同时跟踪大厂 API(如阿里云通义千问、腾讯云混元)的功能升级;
- 沉淀技术组件:将多模态编码、融合逻辑封装为通用组件,避免重复开发,同时便于后续性能优化和功能扩展。
作为后端开发者,多模态技术的核心是 “理解原理 + 落地实战”—— 无需深入研究模型训练细节,重点掌握编码、融合、接口开发的关键逻辑,就能快速适配业务需求。随着多模态技术的普及,未来 1-2 年,具备多模态开发能力的后端开发者将成为企业争抢的核心人才,提前布局就能抢占技术红利!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...





![西游H5圆美商业服务端游戏源码[教程+支持内充+GM后台]](https://img.dunling.com/smtb/20230825/64dd930b9af14cb7a041010bbcca032f.jpg)