” mathimg=”1″>
” mathimg=”1″>
 是一个words序列
是一个words序列 ,每个
,每个

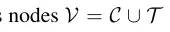
 为边(具体见下图)
为边(具体见下图)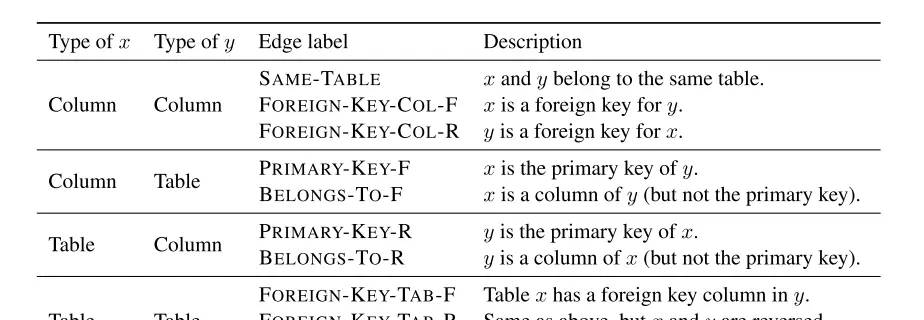

 (后面会讲question和schema之间的特殊关系)
(后面会讲question和schema之间的特殊关系) (或反过来),我们约定
(或反过来),我们约定 属于:
属于: 和列名
和列名 增加了一个
增加了一个
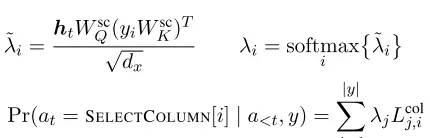

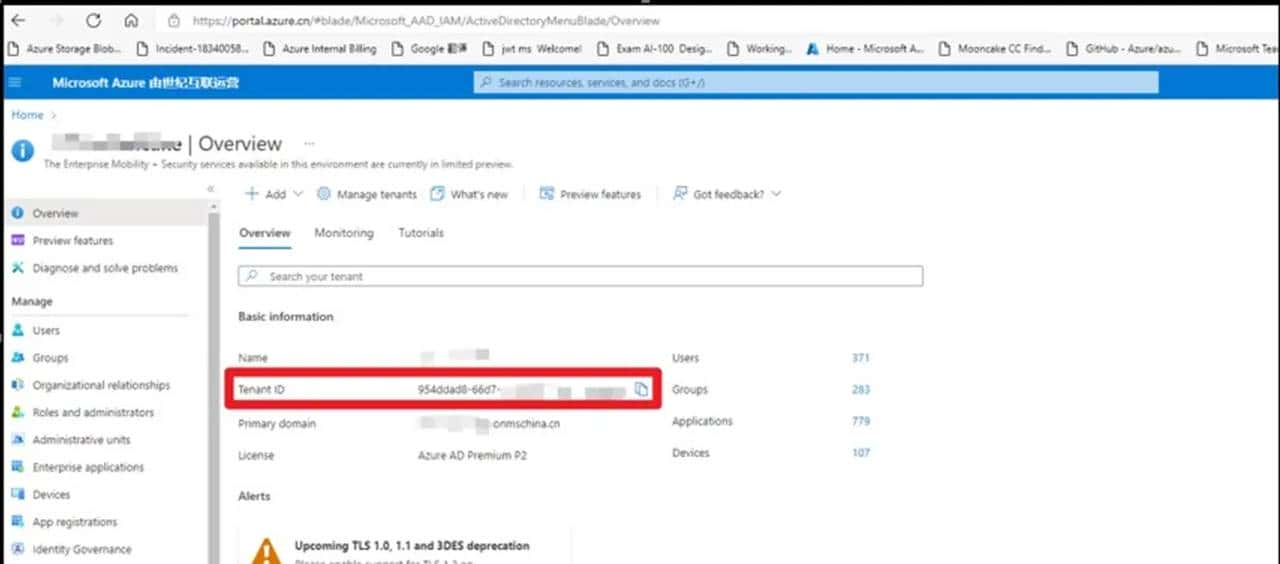
本issue记录RATSQL相关的内容
- paper: https://arxiv.org/abs/1911.04942
- codes:https://github.com/microsoft/rat-sql
摘要
现有两个挑战:
- 如何为语义解析器提供编码数据库关系?
- 如何将数据库列名与给定的query对齐
本文工作:
基于关系感知的自注意力机制,在一个text-to-sql encoder内解决schema encoding, schema linking和特征表明三个问题
Introduction
schema表明(schema generalization)难点:
- 任何text-to-sql模型均要将schema构建为适合解码成可能包含列名和表名的SQL语句的向量表明
-
1中得到的表明应该编码了schema的所有信息,包括列类别、主键、外键 - 模型需要识别(可能与训练过程不同的)NL问题所设计的列名和表格,故成:
schema linking,即将question与列、表进行对齐
具体描述本文工作
(RATSQL)利用关系感知的自注意力机制来构建schema和question的全局推理,用于在给定的question和数据库schema中对关系结构进行编码。
Related Work
- relation-aware self-attentionpaper
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-Attention with Relative Position Repre- sentations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464– 468.
- AST-based structural paper
Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, and Dongmei Zhang. 2019. Towards complex text-to-SQL in cross- domain database with intermediate representation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4524–4535.
Relation-Aware Self-Attention
一个正常的self-attention encoder/transformer:
给定输入:
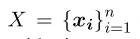
有:
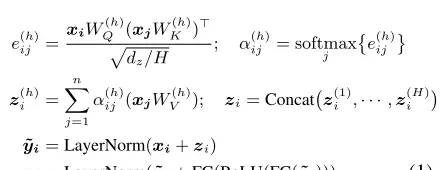
其中, ,这里attention权重
,这里attention权重 就是input的关系信息
就是input的关系信息
一个self-attention layer:
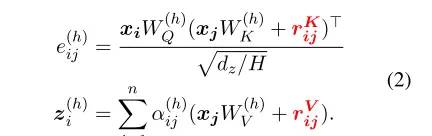
这里, 就编码了
就编码了 和
和 之间已知的关系
之间已知的关系
假设 为关系特征集合,那么
为关系特征集合,那么 。RATSQL对每个(i, j)边用
。RATSQL对每个(i, j)边用 表明所有的预定义特征。
表明所有的预定义特征。
这里 要么是一个从关系学到的embedding(如果该关系适用于相应的边),要么是一个零向量。
要么是一个从关系学到的embedding(如果该关系适用于相应的边),要么是一个零向量。
RAT-SQL
1. 输入输出定义
基本定义:
- 输入:
- natural language question

- schema ” mathimg=”1″>
- natural language question
- 输出:
- SQL P (abstract syntax tree
T)
- SQL P (abstract syntax tree
- 其中
- Question:是一个words序列
- column:,每个还包含type,
- table:
- Question:
每个列名 均包括多个words,如
均包括多个words,如 ;表格名
;表格名 也包括多个words,如
也包括多个words,如
将database schema表明为:
其中:
-
-
为边(具体见下图)
由于以上不包括question信息,所以设计了新的图:
 ” mathimg=”1″>
” mathimg=”1″>
其中:
-
(后面会讲question和schema之间的特殊关系)
encoder-decoder
 →
→ →representations→
→representations→ →
→ 
2. Relation-Aware Input Encoding
- Glove
- BiLSTM
- BERT
因此对于graph,构建输入为:
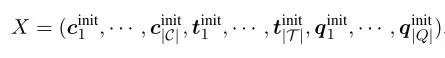
3. Schema Linking
在 的schema linking relations辅助模型去做question和schema的对齐,对齐也主要包括两种:
的schema linking relations辅助模型去做question和schema的对齐,对齐也主要包括两种:match names, match values。
Name-Based Linking
是指列名/表名完全或部分地出目前question中,self-attention在这里还是有一些的缺陷,所以作者:
- 对question取1~5的n-gram,判别每个n-gram是exact match还是partial match
- 对于(或反过来),我们约定属于:

Value-Based Linking
是指Question与schema中的内容(value)相关联,因此也会间接影响到SQL,所以作者:
- 对和列名增加了一个
Column-Value,即匹配了列的任意一个值
Memeory-Schema Alignment Matrix
TODO
4. Decoder
decoder参考了
Pengcheng Yin and Graham Neubig. 2017. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 440–450.
的树结构。
(该方法)根据深度优先遍历,通过一个LSTM来输出一个decoder action序列,像生成句法树一样生成SQL。这个action的产生遵从以下两种方式:
- 根据语法规则扩展最后生成的节点,称为
ApplyRule - 从schema中选择一个column或者table,成为
SelectColumn或者SelectTable
准确来说,
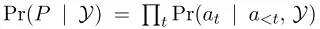
其中 是question和schema最后的encoding变量,
是question和schema最后的encoding变量, 是之前所有的actions。因此对于不同的action,有不同操作,如下:
是之前所有的actions。因此对于不同的action,有不同操作,如下:
- 对于ApplyRule,
-
对于SelectColumn,
Experiments
本小结详细讲了实验相关细节,描述了用到的方案如StanfordCoreNLP,PyTorch,BERT,batch size=24训练了9w个step,利用了超参数搜索的一些方式。由于spider没有test数据公开,所以论文也在dev上进行了验证和实验。并给出了Spider和WiKiSQL两个数据集的实验结果。
在错误分析部分,分析主要有以下三类错误:
- 18%:由于SQL表述形式不同但是实际意义一样
- 39%:在Select部分有丢失或者错误
- 29%:在Where部分错误
附录
TODO
按语
本篇论文是20年微软发表在ACL上的论文,基本达到了当时的sota水平,同时开源了项目代码,有极大的研究价值。纵观整个项目,项目代码较为优雅,在执行上做了许多优化,利用装饰器封装了一个全局的字典用于存储所有变量,方便整个项目在任意位置访问资源,这种写法可以深入学习。模型结构方面,还是经典的encoder-decoder,在encoder部分做了许多的尝试,在decoder部分还是采用了IRNet那种AST的方式。
作者主要是参考了relation-aware self-attention,即将schema和question之间的关系在做attention的时候加进去,从而让模型学得Question与Schema之间的关联信息。所以论文的许多工作是围绕着如何描述它们之间的信息展开的,例如定义了一些column和table之间的type(table 1),在question和column/table之间做match(name-based, value-based),以及(还没看)。在decoder阶段是利用了LSTM深度优先生成树结构,从而构成SQL语句。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...