
训练词典
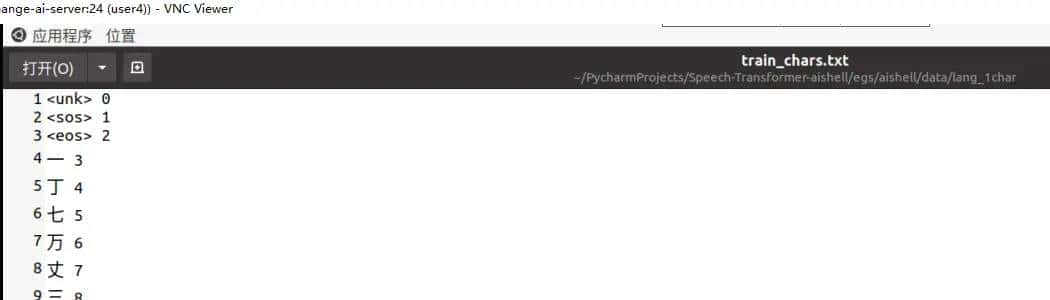
1.#用一个线性层去做词嵌入
use linear transformation with layer norm to replace input embedding
用一个带层归一化的线性层去取代词嵌入(*这里的词嵌入用的是模型的维度)
这里选用的m=7,in_features=560(7*80)=d_input,out_features=256=d_model
self.linear_in = nn.Linear(d_input, d_model)(encoder.py)
(linear_in): Linear(in_features=560, out_features=256, bias=True)
(layer_norm_in): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
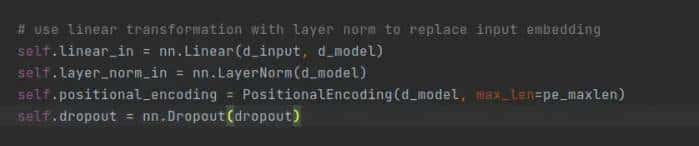
2.对词嵌入之后的数据?(暂时这样理解)加上位置参数
Positional Encoding#主要功能给并行计算的词加上顺序(主要参数 Dropout(p=0.1, inplace=False),控制Dropout,防止模型过拟合,传入参数,)
Transformer(
(encoder): Encoder(
(linear_in): Linear(in_features=560, out_features=256, bias=True)
(layer_norm_in): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(positional_encoding): PositionalEncoding()
(dropout): Dropout(p=0.1, inplace=False)
(layer_stack): ModuleList(
(0): EncoderLayer(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=1024, bias=True)
(w_ks): Linear(in_features=256, out_features=1024, bias=True)
(w_vs): Linear(in_features=256, out_features=1024, bias=True)
(attention): ScaledDotProductAttention(
(dropout): Dropout(p=0.1, inplace=False)
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1280, bias=True)
(w_2): Linear(in_features=1280, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
3.循环结构控制encoder的层数(再一次说明每一层的结构是一样的)

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










