
1.Pascal VOC 2007数据集
作为标准数据集,Pascal VOC 2007 是衡量图像分类识别能力的基准。它包括训练集(5011幅),测试集(4952幅),共计9963幅图,共包含20个种类。
数据集的组成架构如下:
Annotations(目标真值区域)
存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
ImageSets(类别标签)
存放的是每一种类型的challenge对应的图像数据。
Action下存放的是人的动作(例如running、jumping);
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分);
Segmentation下存放的是可用于分割的数据;
Main下存放的是图像物体识别的数据,总共分为20类。
在分类识别中,只关注【Main】,它内部存储20个分类类别标签,-1表明负样本,+1为正样本。
*_train.txt 训练样本集,存放的是训练使用的数据,每一个class的train数据都有5717个。
*_val.txt 评估样本集,存放的是验证结果使用的数据,每一个class的val数据都有5823个。
*_trainval.txt 训练与评估样本合并汇总,每一个class有11540个。
需要保证的是train和val两者没有交集,即训练数据和验证数据不能有重复,应选取随机产生的的训练数据。
JPEGImages(图像)
存放原始图像,这些图像都是以“年份_编号.jpg”格式命名。
图片的像素尺寸大小不一,一般为(横向图)500*375 或(纵向图) 375*500;基本不会偏差超过100。
这些图像就是用来进行训练和测试验证的图像数据。
SegmentationClass
SegmentationObjec
2.U-net架构
论文下载:U-Net: Convolutional Networks for Biomedical Image Segmentation

U-net架构可使用更少的训练图片的同时,且分割的准确度也较好。
每个蓝色框对应一个多通道特征图,通道数显示在框的顶部,x-y大小位于框的左下边缘。白框代表复制的特征图,箭头表明不同的操作。
整体可看作一个编码器-解码器网络,包含:
编码器模块:逐步减少特征映射并捕获更高的语义信息;
解码器模块:逐步恢复空间信息。
Attention:
(1)UNet采用全卷积神经网络。
(2)左边网络为特征提取网络:使用conv和pooling
(3)右边网络为特征融合网络:上采样产生的特征图与左侧特征图进行concatenate操作。
(上采样:让包含高级抽象特征低分辨率图片在保留高级抽象特征的同时变为高分辨率,
再与左边低级表层特征高分辨率图片进行concatenate操作。)
(4)最后再经过两次卷积操作,生成特征图,再用两个卷积核大小为1*1的卷积做分类得到最后的两张heatmap,然后作为softmax函数的输入,算出概率比较大的softmax,再进行loss和反向传播计算。
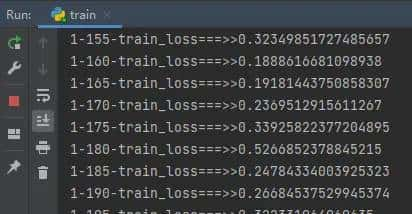
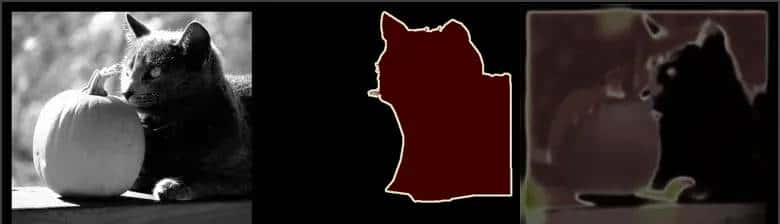
3.PyTorch代码实现及训练模型


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










