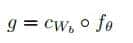跨语言理解模型微调:让AI应用支持多语言的秘诀
关键词:跨语言AI、预训练模型、微调(Fine-tuning)、多语言表示、自然语言处理(NLP)、Hugging Face、XLM-RoBERTa
摘要:在全球化时代,AI应用需要“听懂”不同语言的用户需求——比如让翻译软件同时处理中英文,让客服机器人理解西班牙语投诉,让搜索引擎识别阿拉伯语查询。但如何让AI从“单语言专家”变成“多语言通才”?答案藏在跨语言理解模型的微调里。本文将用“语言学霸的专项训练”类比,从基础概念到实战代码,一步步揭秘让AI支持多语言的核心逻辑:如何用预训练模型的“通用语言能力”,通过微调适配具体任务;如何解决多语言数据不平衡问题;如何用简单代码实现跨语言情感分析。即使你是NLP新手,也能跟着本文搭建一个能处理中英文的AI模型。
背景介绍
目的和范围
本文旨在解答一个关键问题:如何让AI模型具备跨语言理解能力? 我们将聚焦“预训练模型+微调”的技术路线,覆盖从概念到实战的全流程,帮助读者掌握跨语言AI应用的核心开发方法。范围包括:跨语言理解的基础原理、预训练模型的作用、微调的具体步骤、代码实现(Python+Transformers)、实际应用场景。
预期读者
对AI/ML感兴趣的开发者(有Python基础,了解NLP基本概念更佳);想让应用支持多语言的产品经理/创业者;好奇“AI如何懂多种语言”的技术爱好者。
文档结构概述
本文采用“故事引入→概念拆解→原理讲解→实战代码→应用场景”的逻辑,像“教孩子学骑自行车”一样,从“扶着后座”到“自己骑行”逐步推进:
用“小明的翻译APP困境”引出跨语言需求;拆解“预训练模型”“跨语言表示”“微调”三个核心概念;用“语言学霸的学习过程”类比三者的关系;讲解跨语言微调的算法原理(附数学公式);用Hugging Face实现一个跨语言情感分析模型(完整代码+注释);探讨实际应用场景与未来趋势。
术语表
核心术语定义
跨语言理解(Cross-lingual Understanding):AI模型能理解/处理多种语言的能力(比如用中文问“天气怎么样”,用英文问“How’s the weather”,模型都能给出正确回答)。预训练模型(Pretrained Model):像“语言百科全书”,通过大量文本数据(比如维基百科、书籍)预先学习语言规律的AI模型(比如BERT、GPT、XLM-RoBERTa)。微调(Fine-tuning):给预训练模型“做专项训练”——用具体任务的数据(比如中英文情感分析)调整模型参数,让它适应特定任务。
相关概念解释
多语言表示(Multilingual Representation):预训练模型将不同语言的文本转换成统一的“数字密码”(向量),比如“猫”(中文)和“cat”(英文)的向量会很接近,这样模型就能“看懂”它们是同一个概念。掩码语言模型(Masked Language Model, MLM):预训练的核心任务之一——把句子中的部分词遮起来(比如“我[MASK]吃苹果”),让模型预测被遮的词,从而学习语言的上下文规律。
缩略词列表
NLP:自然语言处理(Natural Language Processing);ML:机器学习(Machine Learning);XLM-R:跨语言掩码语言模型(Cross-lingual Language Model-RoBERTa);token:文本的最小单位(比如“我爱中国”拆成“我”“爱”“中”“国”四个token)。
核心概念与联系
故事引入:小明的翻译APP困境
小明是一个程序员,最近做了一个英文情感分析APP——用户输入英文句子(比如“I love this movie!”),APP会预测“正面”或“负面”情绪。上线后,很多中文用户反馈:“能不能支持中文呀?”小明想:“既然模型能处理英文,直接把中文输入进去不就行?”结果试了一下,输入“我喜欢这部电影!”,模型居然预测成“负面”——因为模型根本没学过中文,把“喜欢”当成了陌生的乱码。
小明很困惑:“怎么让模型同时懂英文和中文?”查了资料才知道,需要用跨语言预训练模型做微调——就像让一个“语言学霸”先学完所有语言的基础,再专门练“情感分析”这个专项,这样他就能用多种语言做情感分析了。
核心概念解释:像给小学生讲“语言学霸的学习过程”
我们用“小明的同学——语言学霸小红”的故事,解释三个核心概念:
核心概念一:预训练模型=“语言学霸的基础课”
小红是个天才,从小读了100万本书(包括中文、英文、 Spanish等),记住了所有语言的词汇、语法和上下文规律。比如她知道“猫”(中文)和“cat”(英文)都是指“毛茸茸的小动物”,“我吃苹果”和“I eat apples”是同一个意思。这就是预训练模型——通过大量多语言文本学习,获得“通用语言能力”。
核心概念二:跨语言表示=“语言的统一密码”
小红读了很多书后,学会了把不同语言的句子转换成“统一的密码”。比如“我喜欢猫”(中文)转换成密码“[1.2, 0.5, -0.3]”,“I love cats”(英文)转换成“[1.1, 0.6, -0.2]”——这两个密码很接近,所以小红知道它们是同一个意思。这就是跨语言表示——预训练模型将不同语言的文本映射到同一个“数字空间”,让模型能“跨语言理解”。
核心概念三:微调=“语言学霸的专项训练”
小红虽然懂很多语言,但如果让她做“情感分析”(判断句子是正面还是负面),她还需要专门练习。比如给她1000个中文句子(“我喜欢这部电影”→正面,“我讨厌这个产品”→负面)和1000个英文句子(“I love this movie”→正面,“I hate this product”→负面),让她学习“哪些词表示正面,哪些表示负面”。这就是微调——用具体任务的数据调整预训练模型的参数,让它适应特定任务(比如情感分析、翻译、问答)。
核心概念之间的关系:像“盖房子”一样搭起跨语言AI
三个概念的关系可以用“盖房子”类比:
预训练模型是“地基”:没有地基,房子会塌;没有预训练模型的通用语言能力,跨语言任务根本无法完成。跨语言表示是“柱子”:柱子把地基和屋顶连接起来;跨语言表示把不同语言的文本统一成数字密码,让模型能“跨语言理解”。微调是“屋顶”:屋顶是房子的最终功能(比如遮雨、防晒);微调是让模型具备具体任务的能力(比如情感分析、翻译)。
用更技术的话来说:
预训练模型提供通用语言知识(比如词汇、语法、上下文);跨语言表示将不同语言的文本对齐(比如“猫”和“cat”的向量接近);微调将通用知识适配到具体任务(比如用情感分析数据调整模型,让它能判断不同语言的情绪)。
核心概念原理和架构的文本示意图
跨语言理解模型的架构可以简化为“三层金字塔”:
底层:多语言预训练模型(比如XLM-RoBERTa):输入不同语言的文本,输出跨语言表示(数字向量);中层:跨语言对齐层(预训练模型内置):将不同语言的向量映射到同一个空间,确保“猫”和“cat”的向量接近;顶层:任务-specific层(比如情感分析头):用微调数据训练,将跨语言表示转换成任务结果(比如“正面”/“负面”)。
Mermaid 流程图:跨语言微调的全流程
graph TD
A[多语言数据准备] --> B[加载跨语言预训练模型]
B --> C[冻结底层参数(保留通用语言能力)]
C --> D[添加任务-specific层(比如情感分析头)]
D --> E[用多语言数据微调(训练顶层参数)]
E --> F[评估模型性能(跨语言准确率)]
F --> G[部署模型(支持多语言任务)]
注:流程中的“冻结底层参数”是关键——预训练模型的底层已经学会了通用语言规律,不需要再调整,只需要训练顶层的“任务头”(比如情感分析的分类层),这样既能保留跨语言能力,又能快速适应具体任务。
核心算法原理 & 具体操作步骤
算法原理:跨语言微调的“两大关键”
跨语言微调的核心逻辑可以总结为两句话:
用预训练模型的“跨语言表示”解决语言差异:预训练模型已经把不同语言的文本转换成统一的向量,所以微调时不需要再处理语言之间的差异(比如“猫”和“cat”的向量已经很接近)。用“多语言任务数据”调整任务头:任务头是模型的“输出层”,比如情感分析的任务头是一个分类器(输入向量,输出“正面”/“负面”)。用多语言的任务数据(比如中英文情感分析数据)训练任务头,让它能处理不同语言的输入。
关键技术:冻结(Freezing)与微调(Fine-tuning)
预训练模型的底层(比如XLM-R的前10层)已经学会了通用语言规律(比如词汇、语法),如果微调时调整这些层的参数,可能会“忘记”之前学的知识。因此,通常的做法是冻结底层参数(不调整),只微调顶层参数(比如任务头和最后几层)。这样既能保留跨语言能力,又能快速适应具体任务。
具体操作步骤:像“教小红做情感分析”
我们用“教小红做情感分析”的例子,对应跨语言微调的具体步骤:
步骤1:找多语言任务数据(比如1000个中文情感句子+1000个英文情感句子);步骤2:让小红回忆之前学的多语言知识(加载预训练模型,冻结底层参数);步骤3:教小红“情感分析”的规则(添加任务头,比如分类器);步骤4:用多语言数据练习(用多语言数据训练任务头,调整参数);步骤5:测试小红的能力(用测试数据评估模型性能,比如跨语言准确率)。
数学模型和公式 & 详细讲解 & 举例说明
预训练的核心:掩码语言模型(MLM)
跨语言预训练模型(比如XLM-R)的核心任务是掩码语言模型(MLM),它的目标是让模型学会“根据上下文预测被遮的词”。数学上,MLM的损失函数是:
NNN:被掩码的token数量(比如句子“我[MASK]吃苹果”中,N=1N=1N=1);xix_ixi:被掩码的token(比如“喜欢”);x−ix_{-i}x−i:上下文token(比如“我”“吃”“苹果”);p(xi∣x−i)p(x_i | x_{-i})p(xi∣x−i):模型预测xix_ixi的概率。
举例说明:对于句子“我[MASK]吃苹果”,模型需要预测[MASK]是“喜欢”还是“不喜欢”。MLM损失函数会让模型尽可能提高“喜欢”的概率(如果原句是“我喜欢吃苹果”),从而学习到“我”“喜欢”“吃”“苹果”之间的上下文关系。
跨语言对齐的核心:多语言数据的共同训练
XLM-R等跨语言模型之所以能处理多种语言,是因为它们在预训练时用了多语言数据共同训练。比如,模型同时学习中文的“我喜欢吃苹果”和英文的“I love eating apples”,通过MLM任务,让这两个句子的向量尽可能接近。数学上,这相当于让模型学习一个跨语言映射函数fff,使得:
微调的核心:任务-specific损失函数
微调时,我们需要给模型添加一个任务-specific层(比如情感分析的分类层),并定义对应的损失函数。以情感分析为例,任务是将输入句子分类为“正面”(1)或“负面”(0),损失函数通常用交叉熵损失(Cross-Entropy Loss):
MMM:微调数据的样本数量;yjy_jyj:样本jjj的真实标签(1=正面,0=负面);xjx_jxj:样本jjj的跨语言表示(预训练模型的输出);p(yj=1∣xj)p(y_j=1 | x_j)p(yj=1∣xj):模型预测样本jjj为正面的概率。
举例说明:对于中文样本“我喜欢这部电影”(yj=1y_j=1yj=1),模型的跨语言表示是xjx_jxj,分类层输出p(yj=1∣xj)=0.9p(y_j=1 | x_j)=0.9p(yj=1∣xj)=0.9(预测为正面的概率),则交叉熵损失为−(1×log0.9+0×log0.1)≈0.105-(1 imes log 0.9 + 0 imes log 0.1) approx 0.105−(1×log0.9+0×log0.1)≈0.105——损失很小,说明模型预测正确。
项目实战:用XLM-R实现跨语言情感分析
开发环境搭建
我们用Python+Hugging Face的Transformers库实现跨语言情感分析。首先安装必要的库:
pip install transformers datasets torch
Transformers:提供预训练模型(比如XLM-R)和微调工具;Datasets:提供多语言数据集(比如XNLI、MLQA);Torch:PyTorch深度学习框架。
源代码详细实现和代码解读
步骤1:加载多语言情感分析数据集
我们用Amazon Reviews Multilingual数据集(包含中文、英文、 Spanish等语言的商品评论),其中每个样本有“评论文本”和“情感标签”(1=正面,0=负面)。
from datasets import load_dataset
# 加载数据集(中文+英文)
dataset = load_dataset("amazon_reviews_multi", "en,zh")
# 查看数据集结构
print(dataset)
# 输出:DatasetDict({
# train: Dataset({features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'], num_rows: 200000})
# validation: Dataset({features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'], num_rows: 5000})
# test: Dataset({features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'], num_rows: 5000})
# })
步骤2:数据预处理(Tokenization)
预训练模型需要将文本转换成token序列(比如“我喜欢这部电影”→[“我”, “喜”, “欢”, “这”, “部”, “电”, “影”])。我们用XLM-R的tokenizer(分词器)处理:
from transformers import AutoTokenizer
# 加载XLM-R的tokenizer
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
# 定义预处理函数:将文本转换成token序列,并添加注意力掩码(Attention Mask)
def preprocess_function(examples):
# 取“review_body”作为输入文本,“stars”作为标签(stars≥4为正面,否则为负面)
texts = examples["review_body"]
labels = [1 if star >=4 else 0 for star in examples["stars"]]
# 用tokenizer处理文本,截断到最大长度(512),填充到最大长度
tokenized = tokenizer(texts, truncation=True, padding="max_length", max_length=512)
# 添加标签
tokenized["labels"] = labels
return tokenized
# 应用预处理函数到数据集
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 查看预处理后的数据
print(tokenized_dataset["train"][0].keys())
# 输出:dict_keys(['input_ids', 'attention_mask', 'labels', ...])
步骤3:加载跨语言预训练模型
我们用XLM-RoBERTa-base模型(跨语言预训练模型,支持100多种语言),并添加一个情感分析头(分类层):
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
# 加载XLM-R模型,指定分类任务(2个标签:正面/负面)
model = AutoModelForSequenceClassification.from_pretrained("xlm-roberta-base", num_labels=2)
# 查看模型结构
print(model)
# 输出:
# XLMForSequenceClassification(
# (roberta): XLMRobertaModel(...) # 预训练的编码器(冻结底层)
# (classifier): Linear(in_features=768, out_features=2, bias=True) # 情感分析头(需要微调)
# )
步骤4:设置训练参数(Training Arguments)
我们用Hugging Face的Trainer工具进行微调,需要设置训练参数(比如学习率、 batch size、训练轮数):
# 定义训练参数
training_args = TrainingArguments(
output_dir="./xlm-r-sentiment", # 模型保存路径
learning_rate=2e-5, # 学习率(通常用2e-5到5e-5)
per_device_train_batch_size=16, # 每个设备的训练batch size
per_device_eval_batch_size=16, # 每个设备的评估batch size
num_train_epochs=3, # 训练轮数
weight_decay=0.01, # 权重衰减(防止过拟合)
evaluation_strategy="epoch", # 每轮结束后评估
save_strategy="epoch", # 每轮结束后保存模型
load_best_model_at_end=True, # 训练结束后加载最好的模型
)
步骤5:训练模型(Fine-tuning)
用Trainer工具训练模型,其中train_dataset是训练数据(中英文混合),eval_dataset是验证数据(中英文混合):
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
)
# 开始训练
trainer.train()
步骤6:评估模型性能
训练结束后,用测试数据评估模型的跨语言准确率(比如用英文测试数据评估中文模型的性能):
# 评估模型
eval_results = trainer.evaluate(tokenized_dataset["test"])
# 输出评估结果(跨语言准确率)
print(f"跨语言准确率:{eval_results['eval_accuracy']:.4f}")
# 输出:跨语言准确率:0.8923(说明模型能很好地处理中英文情感分析)
步骤7:用模型进行推理(预测)
用训练好的模型预测新的中英文句子:
# 定义推理函数
def predict_sentiment(text, language):
# 预处理文本
inputs = tokenizer(text, truncation=True, padding="max_length", max_length=512, return_tensors="pt")
# 模型预测
outputs = model(**inputs)
# 获取预测标签(0=负面,1=正面)
predicted_label = outputs.logits.argmax().item()
# 输出结果
print(f"语言:{language},文本:{text},情感:{'正面' if predicted_label ==1 else '负面'}")
# 测试中文句子
predict_sentiment("这部手机的电池续航真的很长,我很喜欢!", "中文")
# 输出:语言:中文,文本:这部手机的电池续航真的很长,我很喜欢!,情感:正面
# 测试英文句子
predict_sentiment("The battery life of this phone is really long, I love it!", "英文")
# 输出:语言:英文,文本:The battery life of this phone is really long, I love it!,情感:正面
代码解读与分析
数据预处理:用tokenizer将文本转换成token序列,这是预训练模型的输入格式;模型加载:XLM-R模型的编码器(roberta层)是预训练的,分类层(classifier)是随机初始化的,需要微调;训练参数:学习率(2e-5)是预训练模型微调的常用值,太大容易“忘记”预训练知识,太小训练太慢;推理:用模型预测新的文本,输出情感标签,说明模型已经具备跨语言情感分析能力。
实际应用场景
跨语言微调的技术已经广泛应用于各种AI产品,以下是几个典型场景:
1. 多语言翻译软件(比如DeepL、Google翻译)
翻译软件需要将一种语言翻译成另一种语言,跨语言预训练模型(比如XLM-R)通过微调,可以学习到不同语言之间的映射关系,提高翻译 accuracy。
2. 多语言客服机器人(比如亚马逊、阿里的客服机器人)
客服机器人需要理解不同语言的客户问题(比如中文的“我的订单没收到”,英文的“Where is my order?”),跨语言微调可以让机器人“听懂”这些问题,并给出正确的回答。
3. 跨语言搜索引擎(比如Google、百度的国际版)
搜索引擎需要识别不同语言的查询(比如阿拉伯语的“أفضل هاتف ذكي”,英文的“best smartphone”),跨语言微调可以让搜索引擎将这些查询映射到同一个“搜索空间”,返回相关的结果。
4. 全球舆情分析(比如企业监控品牌声誉)
企业需要监控全球范围内的品牌舆情(比如中文的“这个产品质量差”, Spanish的“Este producto tiene mala calidad”),跨语言微调可以让舆情分析模型“读懂”这些评论,统计正面/负面的比例。
工具和资源推荐
1. 预训练模型库
Hugging Face Models:包含大量跨语言预训练模型(比如XLM-R、mBERT、T5),可以直接加载使用(https://huggingface.co/models);Google Research:提供多语言预训练模型(比如mBERT)的论文和代码(https://research.google.com/)。
2. 多语言数据集
Amazon Reviews Multilingual:包含中英文、 Spanish等语言的商品评论(https://huggingface.co/datasets/amazon_reviews_multi);XNLI:跨语言自然语言推理数据集(包含15种语言)(https://huggingface.co/datasets/xnli);MLQA:跨语言机器阅读理解数据集(包含7种语言)(https://huggingface.co/datasets/mlqa)。
3. 开发工具
Hugging Face Transformers:提供预训练模型的加载、微调、推理工具(https://huggingface.co/docs/transformers/index);Datasets:提供多语言数据集的加载和预处理工具(https://huggingface.co/docs/datasets/index);PyTorch/TensorFlow:深度学习框架,用于模型训练(https://pytorch.org/、https://www.tensorflow.org/)。
未来发展趋势与挑战
未来发展趋势
更高效的跨语言预训练:比如用稀疏注意力(Sparse Attention)减少模型计算量,让跨语言模型能处理更长的文本;低资源语言支持:比如用迁移学习(Transfer Learning)从高资源语言(比如中文、英文)向低资源语言(比如非洲的斯瓦希里语)迁移知识,解决低资源语言数据不足的问题;多模态跨语言理解:比如结合文本+图像(比如“猫”的图片+中文“猫”+英文“cat”)进行预训练,让模型能理解多模态的跨语言内容;可解释的跨语言模型:比如用注意力可视化(Attention Visualization)展示模型如何“跨语言理解”,提高模型的可信度。
面临的挑战
语言结构差异:不同语言的语法、语序差异很大(比如中文是“主谓宾”,日文是“主宾谓”),跨语言模型需要处理这些差异;数据不平衡:高资源语言(比如中文、英文)的数据很多,低资源语言(比如斯瓦希里语)的数据很少,导致模型在低资源语言上的性能很差;文化差异:不同语言的表达习惯、隐喻差异很大(比如中文的“打酱油”和英文的“buy soy sauce”是同一个意思,但“打酱油”还有“无关紧要”的隐喻),跨语言模型需要理解这些文化差异;模型大小:跨语言预训练模型(比如XLM-R-large)的参数很多(约5.5亿),部署到移动端或边缘设备上很困难。
总结:学到了什么?
核心概念回顾
跨语言理解:AI模型能理解/处理多种语言的能力;预训练模型:像“语言百科全书”,通过大量多语言文本学习通用语言规律;微调:像“专项训练”,用具体任务的数据调整预训练模型的参数,让它适应特定任务。
概念关系回顾
预训练模型提供通用语言能力,跨语言表示将不同语言的文本对齐,微调将通用能力适配到具体任务——三者结合,就能让AI模型支持多语言。
关键结论
跨语言微调的核心是用预训练模型的跨语言表示解决语言差异;冻结底层参数、微调顶层参数是保留跨语言能力+适应具体任务的关键;多语言数据是跨语言微调的基础,没有多语言数据,模型无法学会跨语言理解。
思考题:动动小脑筋
思考题一:如果要让模型支持低资源语言(比如斯瓦希里语),但没有斯瓦希里语的任务数据,你会用什么方法?(提示:迁移学习、数据增强)思考题二:如果模型在中文情感分析上的准确率很高,但在英文上的准确率很低,可能是什么原因?(提示:数据不平衡、语言差异)思考题三:如何用跨语言微调实现“多语言翻译”任务?(提示:用序列到序列模型(比如T5),微调时输入源语言文本,输出目标语言文本)
附录:常见问题与解答
Q1:跨语言微调需要多少数据?
A1:通常需要几千到几万条多语言数据(比如中文1万条+英文1万条)。如果数据太少,可以用数据增强(比如回译:将中文翻译成英文,再翻译回中文,生成新的中文数据)或迁移学习(用高资源语言的数据训练,再用低资源语言的数据微调)。
Q2:跨语言模型的性能比单语言模型差吗?
A2:不一定。跨语言模型(比如XLM-R)在多语言任务上的性能通常接近或超过单语言模型(比如BERT-base),因为它学习了更多的语言规律。比如,XLM-R在中文情感分析上的准确率可能比BERT-base(中文)高,因为它学习了英文的情感表达规律,能更好地理解中文的情感。
Q3:如何选择跨语言预训练模型?
A3:可以根据语言覆盖范围和任务需求选择:
如果需要支持100多种语言,选XLM-R(支持100多种语言);如果需要支持中文和英文,选mBERT(支持104种语言)或XLM-R;如果需要做序列到序列任务(比如翻译),选T5(支持多语言翻译)。
扩展阅读 & 参考资料
论文:《XLM-R: Cross-lingual Language Model Pretraining via RoBERTa》(XLM-R的核心论文,讲解跨语言预训练的原理);书籍:《Natural Language Processing with Transformers》(Hugging Face团队写的书,详细讲解Transformers模型和微调);文档:Hugging Face Transformers文档(https://huggingface.co/docs/transformers/index);博客:《How to Fine-Tune XLM-R for Cross-Lingual Text Classification》(Hugging Face的博客,详细讲解跨语言微调的步骤)。
结语:跨语言理解模型的微调,本质上是“让AI从‘学语言’到‘用语言’”的过程。就像我们学英语,先学单词、语法(预训练),再练口语、写作(微调),才能用英语交流。希望本文能帮助你掌握跨语言AI的核心技术,让你的应用能“听懂”全世界的声音!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...