
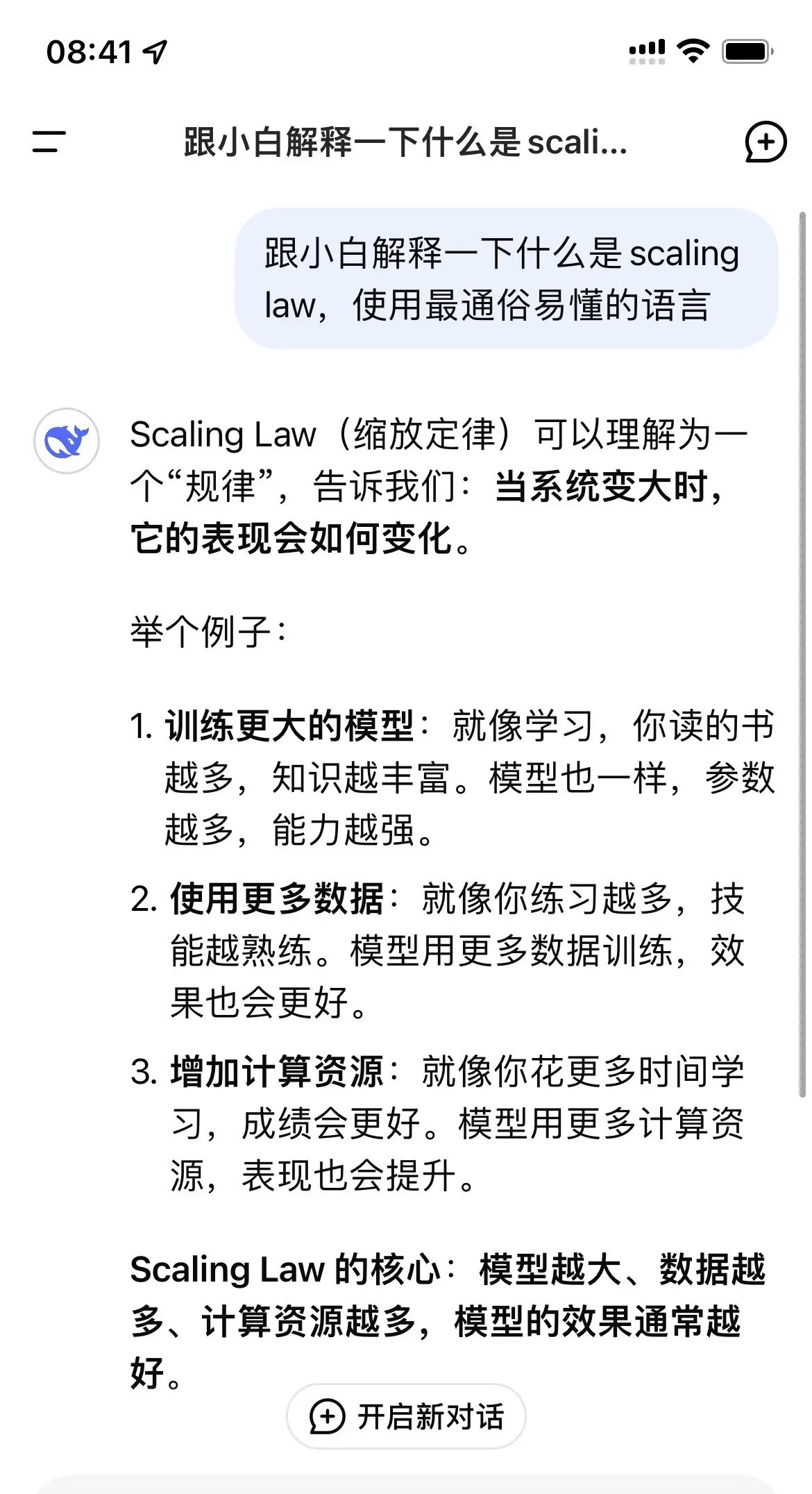
.简单讲,就是暴力美学。在模型架构(transformer)基本不变的情况下,增加模型大小、数据量、算力资源,都能让模型达到更好的效果。目前的大模型架构是基于8年前的一篇文章,attention is all you need,基本架构到目前几乎没动过!openai最早把第一个要素,即模型规模做到了极致,(当年1700亿参数的gpt3的确 很吓人),力大砖飞,成就了目前最强ai公司;老黄靠着买显卡,给大家提供算力资源,让英伟达曾一度超越苹果,成为市值最高的公司;按照目前人类的生产力,模型规模和算力资源都不是问题,无非就是烧嘛,钱能解决的都不叫事。但是,目前的问题是数据已经到了瓶颈,毕竟互联网包括人类几千年留下的书籍就那么多,另外,新增的互联网数据可能大多都是垃圾(没错,就是微博之类的互联网垃圾)导致数据已经撞墙了。既然大模型的预训练已经遇到了不小的瓶颈,所以目前大部分公司开始了转向后训练,通过RL来提高模型的能力。毕竟,解决不了的问题,只能靠脑子来解决了
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章











Scaling Law.简单讲,就是暴力美学。在模型架构(transformer)基本不变的情况下,增加模型大小、数据量、算力资源,都能让模型达到更好的效果。目前的大模型架构是基于8年前的一篇文章,attention is all you need,基本架构到现在几乎没动过!openai最早把第一个要素,即模型规模做到了极致,(当年1700亿参数的gpt3确实很吓人),力大砖飞,成就了现在最强ai公司;老黄靠着买显卡,给大家提供算力资源,让英伟达曾一度超越苹果,成为市值最高的公司;按照现在人类的生产力,模型规模和算力资源都不是问题,无非就是烧嘛,钱能解决的都不叫事。但是,现在的问题是数据已经到了瓶颈,毕竟互联网包括人类几千年留下的书籍就那么多,另外,新增的互联网数据可能大多都是垃圾(没错,就是微博之类的互联网垃圾)导致数据已经撞墙了。既然大模型的预训练已经遇到了不小的瓶颈,所以现在大部分公司开始了转向后训练,通过RL来提高模型的能力。毕竟,解决不了的问题,只能靠脑子来解决了
@Shanice羅珊