![[linux] CentOS 7 编译使用 openCv (Java)](https://www.dunling.com/img/5.jpg)
目前大模型火归火,但落地一看推理慢、资源吃紧,许多都跑不动,特别是在边缘设备或者商用场景里。所以推理加速优化,真的就是决定能不能真正work的关键。我们来聊聊2025年比较实用、还挺有前景的优化手段。投机解码投机解码是2025年很火的技术,用小模型先生成几个候选token,然后大模型并行验证,不影响输出质量但速度能提升2-4倍。像vLLM、FlashInfer都已经原生支持,特别适合对话和代码生成场景。 模型裁剪,干掉冗余参数剪枝目前许多团队已经从稀疏剪枝搞到结构化剪枝,尤其像[Structured Pruning + Low-rank factorization]组合拳,直接干掉一大波没啥贡献的通道和层。列如对Transformer,可以裁点attention head、layer block,推理时间一下子就压下来了。 把float换成int,说白了就是压缩精度换速度目前不是简单地float32变int8这么low了,大家搞得越来越精细,列如[Mixed-Precision Quantization]、[GPTQ]、[AWQ]这种,更偏向于layer-wise感知,能做到不明显掉精度但推理飞快。OpenLLM这块已经卷到大家都默认用INT4了,速度直接提一倍以上。 推理时计算扩展推理模型兴起后,出现了推理效率优化新方向,通过增加测试时计算来提升模型输出质量,像Chain-of-Thought优化、并行推理路径等。 你写的模型,框架懂了还得再加工一下列如用TensorRT、ONNX Runtime、OpenVINO这些,把原始模型转换后做一波图融合、内存复用、算子融合。常见的transformer模型,算子一多,优化后能少好几个kernel call,能快不少。 长文本推理,KV Cache别忘了开大模型在长文本场景中如果没用KV Cache,那就像没加油的发动机,一直重复计算。目前推理分为prefill(预填充)和decode两个阶段,各有不同的计算特点。FlashAttention、PagedAttention这些都是为了解决这个问题来的,提升挺猛。 从架构源头思考部署知识蒸馏也很香,特别是你把一个巨大的teacher模型训好之后,再用它来训个小模型student。目前有些新架构本身就往低资源场景上靠,列如[Mamba-style RNN架构]、[Phi-3]、[TinyLlama],参数少、架构紧凑,硬件友善。反正就一句话,训得起只是第一步,跑得动才是真的能落地。有些公司卷算法卷架构,有些组开始卷部署和优化,未来肯定还是这几条路一起走。你要做研究,选一个方向搞深入,也挺容易出新点子的。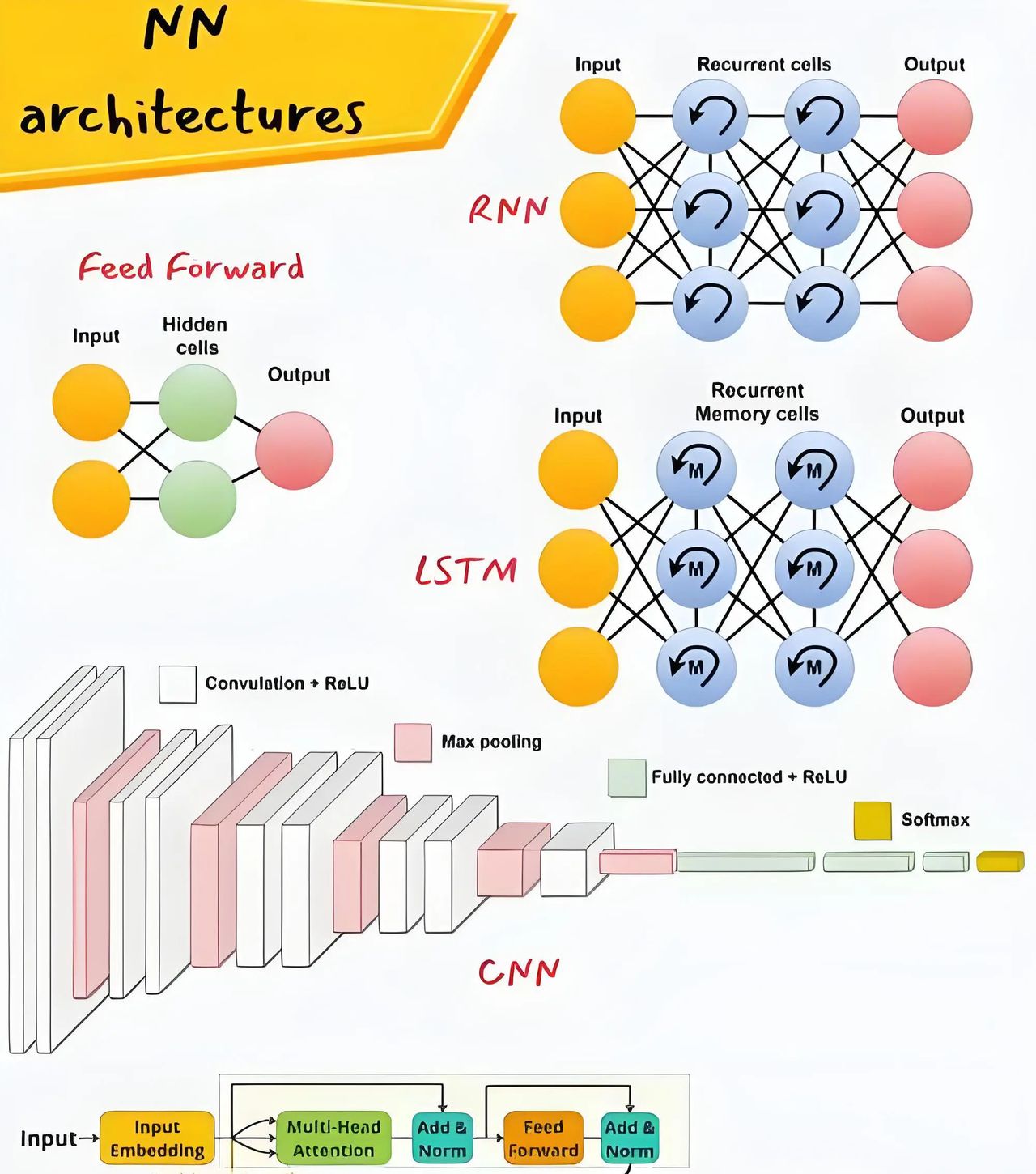





© 版权声明
文章版权归作者所有,未经允许请勿转载。














如何通过推理加速优化你的大模型?现在大模型火归火,但落地一看推理慢、资源吃紧,很多都跑不动,特别是在边缘设备或者商用场景里。所以推理加速优化,真的就是决定能不能真正work的关键。我们来聊聊2025年比较实用、还挺有前景的优化手段。投机解码投机解码是2025年很火的技术,用小模型先生成几个候选token,然后大模型并行验证,不影响输出质量但速度能提升2-4倍。像vLLM、FlashInfer都已经原生,特别适合对话和代码生成场景。 模型裁剪,干掉冗余参数剪枝现在很多团队已经从稀疏剪枝搞到结构化剪枝,尤其像[Structured Pruning + Low-rank factorization]组合拳,直接干掉一大波没啥贡献的通道和层。比如对Transformer,可以裁点attention head、layer block,推理时间一下子就压下来了。 把float换成int,说白了就是压缩精度换速度现在不是简单地float32变int8这么low了,大家搞得越来越精细,比如[Mixed-Precision Quantization]、[GPTQ]、[AWQ]这种,更偏向于layer-wise感知,能做到不明显掉精度但推理飞快。OpenLLM这块已经卷到大家都默认用INT4了,速度直接提一倍以上。 推理时计算扩展推理模型兴起后,出现了推理效率优化新方向,通过增加测试时计算来提升模型输出质量,像Chain-of-Thought优化、并行推理路径等。 你写的模型,框架懂了还得再加工一下比如用TensorRT、ONNX Runtime、OpenVINO这些,把原始模型转换后做一波图融合、内存复用、算子融合。常见的transformer模型,算子一多,优化后能少好几个kernel call,能快不少。 长文本推理,KV Cache别忘了开大模型在长文本场景中如果没用KV Cache,那就像没加油的发动机,一直重复计算。现在推理分为prefill(预填充)和decode两个阶段,各有不同的计算特点。FlashAttention、PagedAttention这些都是为了解决这个问题来的,提升挺猛。 从架构源头考虑部署知识蒸馏也很香,特别是你把一个巨大的teacher模型训好之后,再用它来训个小模型student。现在有些新架构本身就往低资源场景上靠,比如[Mamba-style RNN架构]、[Phi-3]、[TinyLlama],参数少、架构紧凑,硬件友好。反正就一句话,训得起只是第一步,跑得动才是真的能落地。有些公司卷算法卷架构,有些组开始卷部署和优化,未来肯定还是这几条路一起走。你要做研究,选一个方向搞深入,也挺容易出新点子的。#深度学习#Python #大模型#论文辅导#sci