OpenHuman一天涨千星,霸榜GitHub Trending第一
事情是这样的。
这两天GitHub Trending上来了个新东西,叫OpenHuman。你猜怎么着,一天涨千星,直接飙到9000多Star,霸榜第一。
一开始我没太在意,心想又是个Agent呗。最近Agent还少吗,虾啊马啊,一个接一个,看都看麻了。
但翻了一下项目页,我愣了一小会儿。
养虾养马,你得教它们
你知道虾和马的问题在哪儿吗?
你得教它们。
配Skill、写Prompt、调工作流,一顿操作猛如虎,一看效果……反正我身边没几个人真正把Manus用好用到日常里的。新鲜感过了就扔那了。
归根结底,你得先动,它们才动。
OpenHuman的逻辑反过来了。
你不需要教它,连上你的Gmail、GitHub、Slack、Notion、日历,118个服务一键接进来。然后它每20分钟自动抓一遍新数据,自己整理,自己存,自己理解。
一次同步跑完,直接对你的工作生活了如指掌。
没有训练期,没有磨合期,第一天上班就能干活。
谁懂啊。
养虾养马已经养累了。终于来了个不用教的。
卡帕西的手搓活儿,被它全自动了
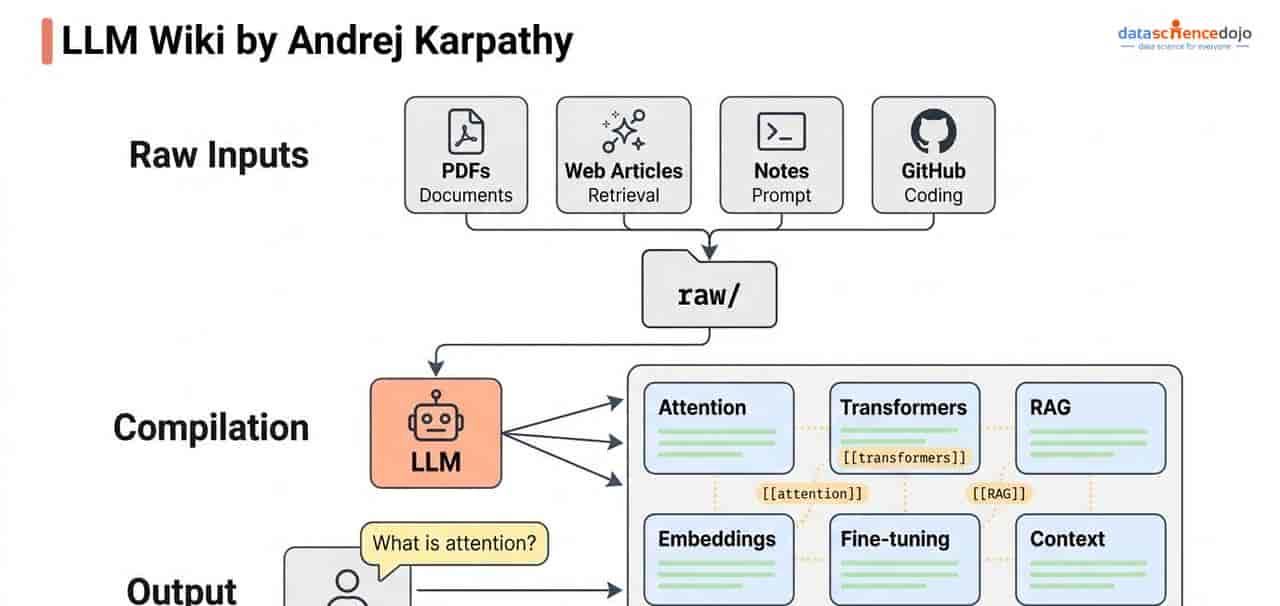
Andrej Karpathy的LLM Wiki工作流:手动整理→AI索引
说到卡帕西,你应该知道那哥们吧,OpenAI那哥们,前阵子公开了自己的一个工作流,叫LLM Wiki。
操作大致是这样,把所有笔记、项目文档,一个不落地整理成结构化的Markdown文件,扔进Obsidian里,让AI持续索引和理解。
这思路实则很好。
手动把所有碎片信息归一化,AI就能真正「理解你」。问题在于,这套操作全手工。你得自己写Markdown,自己分类,自己更新。一天不维护,知识库就馊了。
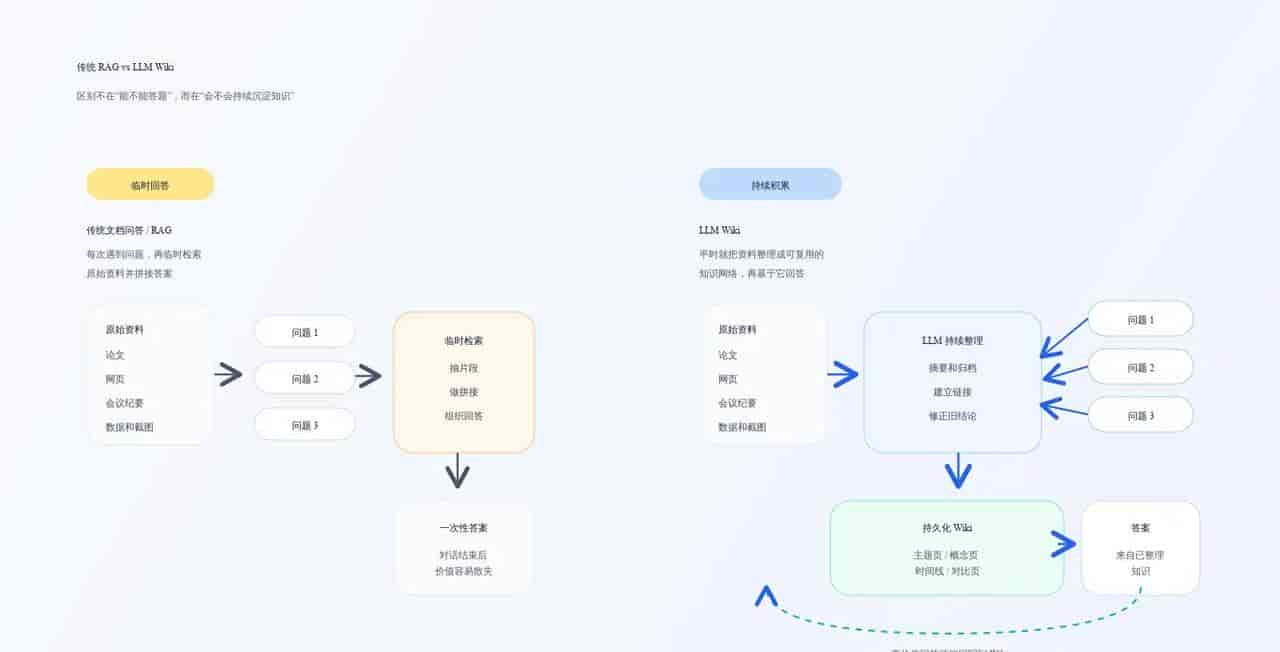
OpenHuman干的事特别直接,就是把卡帕西这套手搓活儿,变成了全自动流水线。总结成三步:
OpenHuman核心三步
连接:118个第三方服务一键授权,覆盖
Gmail/GitHub/Slack/Notion/Stripe/Drive等核心工具
抓取:每20分钟自动轮询所有账户,新邮件/日程/代码/文档全拉到本地
记忆树:数据清洗压缩,切成3000 Token以内的Markdown片段,按主题/时间线/关联对象做评分和层级摘要
记忆树:给机器读,也给人看
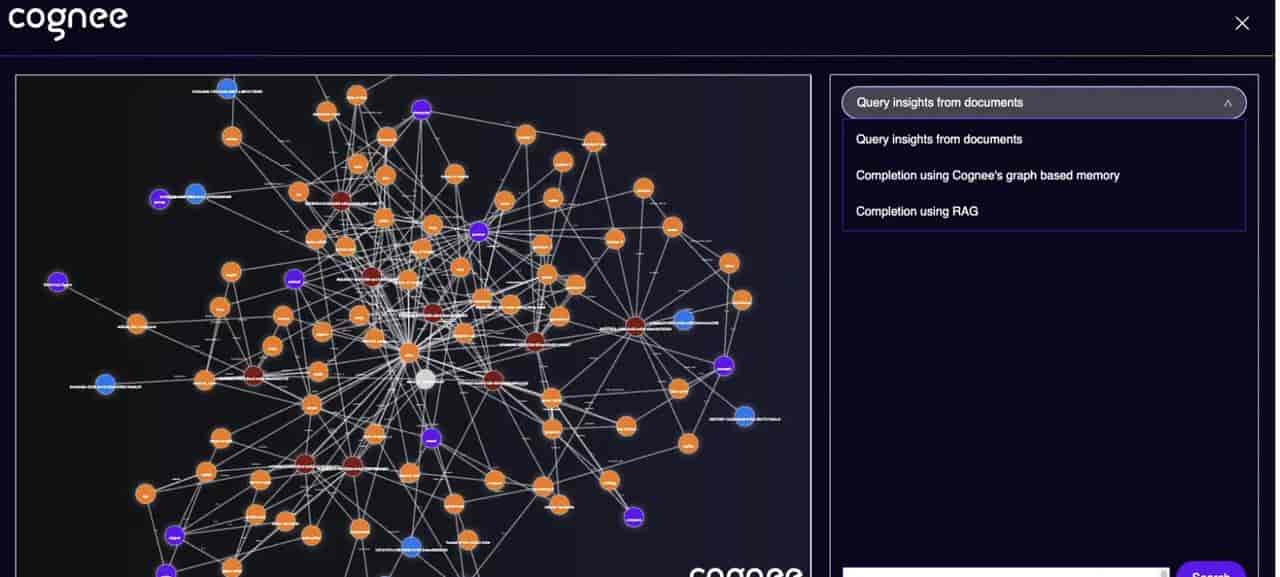
抓来的数据经过清洗和压缩,切成不超过3000个Token的Markdown片段,按主题、时间线、关联对象做评分和层级摘要,最终折叠成一棵记忆树。
这棵树的本体是一个本地SQLite数据库。但同一份数据还会同步生成.md文件,落盘成一个兼容Obsidian的本地知识库。
你可以直接用Obsidian打开它,浏览、编辑Agent的「记忆」。
就,很妙。
数据存两份,一份给机器读,一份给人看。你把Agent的记忆当自己的笔记用,反过来也可以改它的记忆让它更准。这就不是一个黑箱了,是透明的。
TokenJuice:直接砍掉80%Token消耗
记忆树之外还有个我觉得挺鸡贼的设计,叫TokenJuice。
每次工具调用结果、网页抓取、邮件正文,在送到大模型之前,先过一遍压缩。
HTML转Markdown、长URL缩短、非ASCII字符清理、冗余信息去重。一顿操作下来,Token消耗能砍掉80%。
80%啊兄弟。
目前大家吐槽最狠的不就是Token太贵吃不起吗。OpenHuman直接在入口处给你省了。而且它用了三层规则叠加,内置默认规则、用户自定义规则、项目级规则,全以JSON文件存储,改了不用重新编译。
Mascot:会开会的虚拟形象

Mascot作为独立参会者加入Google Meet,旁听记要点
还有Mascot功能,一个会说话的虚拟形象,能作为独立参会者加入Google Meet会议。
你开会,它旁听记要点。你离开电脑,它在后台继续执行待办任务。
而且它有个叫做「潜意识循环」的机制。即使你不主动跟它交互,它也会自己加载待办、读取近期记忆、自主决定还有什么可以干。
你下午三点开完会,去茶水间接杯水。回来一看,会上讨论的那些待办,它已经帮你列好了。邮箱里需要回复的邮件,它草稿都打完了。PR提了,通知发到位了。
—— 不是你说它做的,是你还没说,它就做了
这种体验跟目前市面上的Agent完全是两种东西。
为什么虾和马大家日常不用
聊到这儿我想说点真的。
虾和马被吹得那么厉害,但为什么大家日常不怎么用?我觉得不是由于它们能力不够,而是由于它们跟你的「对齐」成本太高了。
你得先把自己的知识和习惯教给它们。这个过程本身就够累的。
天天上班已经够累了,下班还要训Agent?
这就好比你买了个扫地机器人,回家还得先花三天教它怎么认路。那你还不如自己扫。
OpenHuman的做法是,你不是让我学,是让它自己来看。连上我的数据,20分钟后它自己就懂了。这不偷懒,这是对的。工具应该适应人,不是人适应工具。

量子位的文章里有句话写得很准:
这三个痛点拆开是功能问题,合起来实则是还不够贴合用户真实使用习惯。之前的Agent,心思都花在「能干」上了,但在「懂你」这方面,始终差了点意思。
—— 量子位
我特别认同这句话。
一个Agent能不能帮你写代码、能不能帮你订机票,是能力问题。但它知不知道你最近在忙什么项目、跟谁在合作、什么时间不方便开会,是懂不懂你的问题。
能力可以更新,懂你需要时间。
所以你回头看OpenHuman的爆火,可能不是由于它的功能有多牛逼,而是由于它刚好踩中了那个所有人都隐隐觉得不对但一直没明说的问题:
养虾养马养累了。
不是Agent不够强,是Agent太需要我来教了。
OpenHuman的思路很简单也很粗暴:
别教了,让它自己看吧。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














[db:评论]