
大家好,我是阿童麦。
扣子工作流是由多个节点组成,每个节点通过连线,把变量不断处理、传递,最终输出我们想要的结果。
节点是什么?
你可以把“工作流”理解成一条流水线,而“节点”就是这条流水线上的不同工位的员工。每个员工只做一件事,但组合起来,就能完成复杂任务。
刚接触工作流的新手朋友,对于各个节点如何使用、每个节点适用于什么场景,往往一头雾水,甚至看完教程也不知道该从哪里下手。
还有一个很常见的误区:许多人以为节点越多、越复杂,工作流就越高级。实则恰恰相反:真正成熟的工作流,往往结构清晰、节点克制。
本篇开始,我会带你从 0 建立一套“节点认知体系”,系统梳理常见节点的作用与使用方式。
作为节点的第一篇,我们先从最基础、也是最重大的三个节点开始:开始节点、结束节点,以及大模型节点。
开始节点
开始节点作为工作流的入口,用来接收输入数据。它的使用很简单,你需要交给工作流处理的数据,都是在这个节点输入。
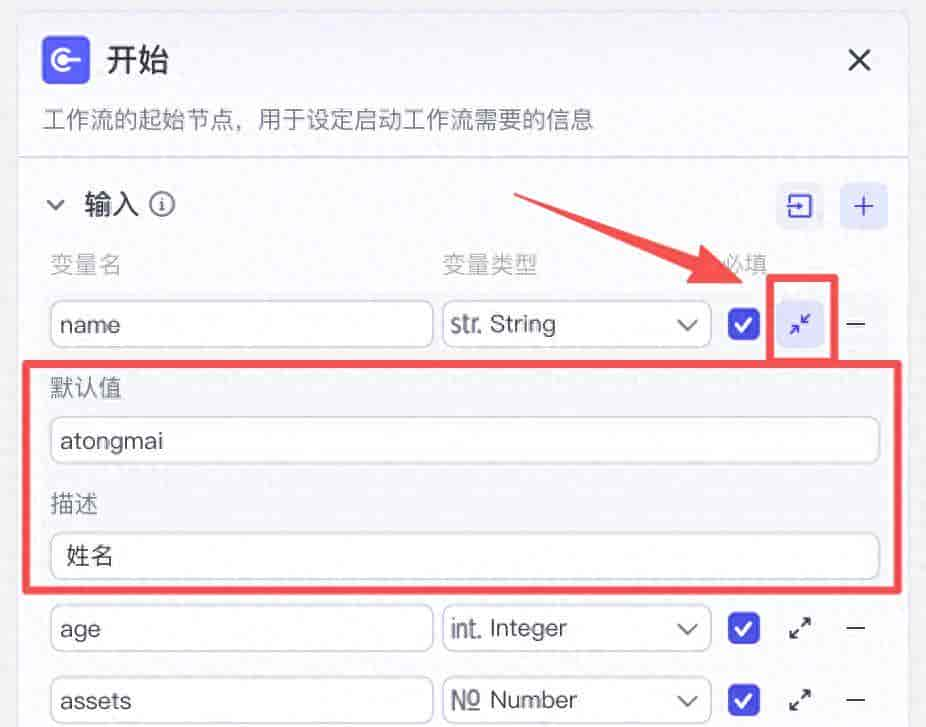
我这边在开始节点建立了 4 个变量,用来接收相应的 4 个数据。我们可以对变量勾选必填,还可以点击「展开」图标,对变量设置默认值和描述。
必填:勾选后,该变量必须输入数据,否则工作流无法运行。
默认值:在运行时自动填入预设内容,作为默认输入。
描述:用于说明这个变量的用途,方便自己或他人理解。
提议:如果变量勾选了“必填”,尽量设置默认值,避免运行时遗漏导致无法运行。
许多新手一开始都会有个疑问:是不是所有数据,都应该从开始节点传进来?
实则开始节点只负责一件事情:接收数据,也就是这条工作流一开始就必须确定的信息。
这些数据,我归纳为以下两类。
1、外部输入
最常见的一类的就是我们在运行时,需要输入的数据。
列如你要搭建一个“把动物放进冰箱”的工作流,可以把“动物名称”作为变量配置在开始节点。在运行时输入“大象”,那工作流接下来处理的就是“把大象放进冰箱”这件事。
另外,在后续你会接触到工作流节点,当一个工作流被当作子节点使用时,父工作流传入的数据,本质上也是通过“开始节点”进入子流程。
2、配置信息
一些不常常变化,但又必须存在的数据。
第三方插件节点需要的 api_key ,工作流的固定配置信息,列如语言类型、时间参数等,后续我会在实战项目中详细讲到。
把这些信息统一放在开始节点,有两个好处:聚焦管理 + 减少重复配置。
一句话总结开始节点的使用原则:一开始就必须知道的数据,才放在开始节点;中途才产生的数据,一律放到后面的节点处理。
结束节点
结束节点作为工作流的出口,当所有节点处理完成之后,最终的结果,会从这里输出。
你可以在结束节点中,选择需要输出的变量,把它们作为最终结果返回。我这边输出了开始节点中的四个数据。这也是最常用的返回形式:“返回变量”。
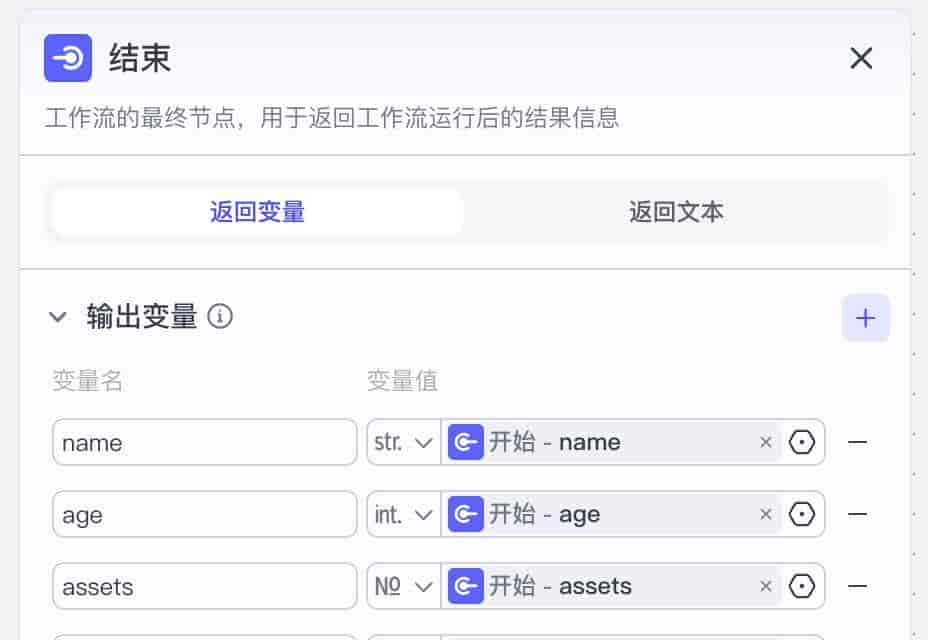
另外,你也可以对结束节点配置为“返回文本”,运行时工作流就会把输出变量,按你的方式组合成一段话来输出。如果工作流中有大模型节点,还可以打开「流式输出」,这样子更像聊天方式,逐字逐句的输出结果。
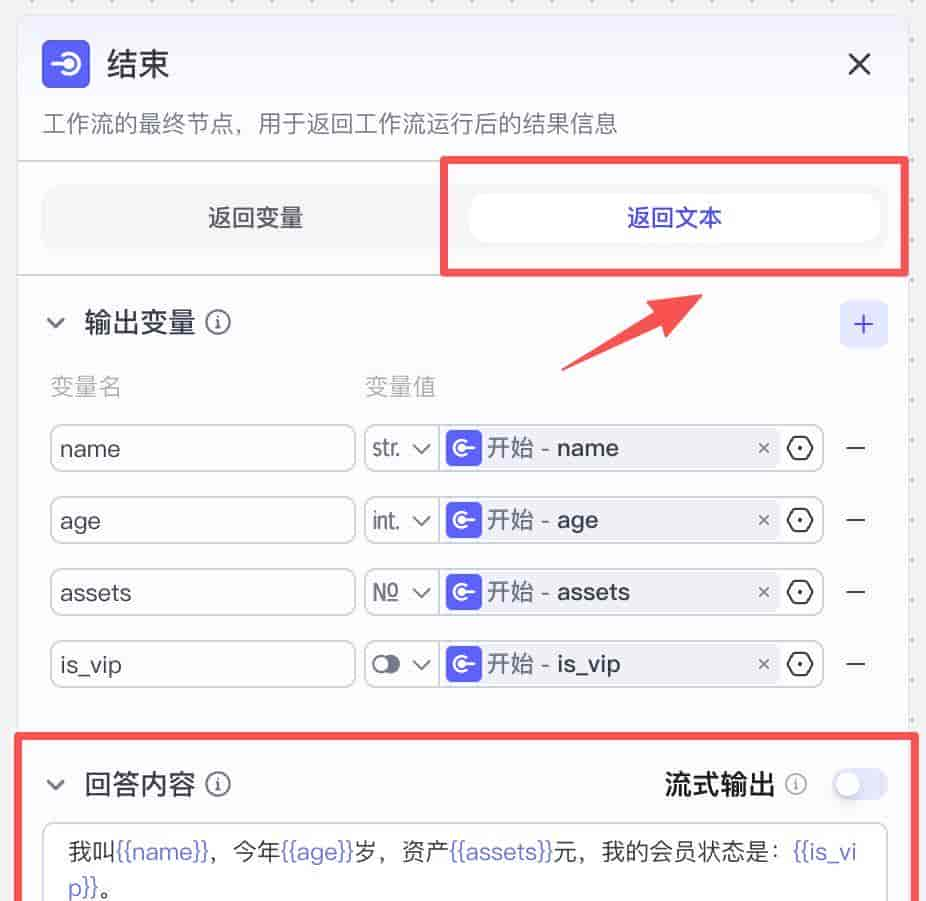
一般我们在用扣子开发智能体应用时会用到这种方式来输出。可以看到运行结果中输出的效果如下图所示。
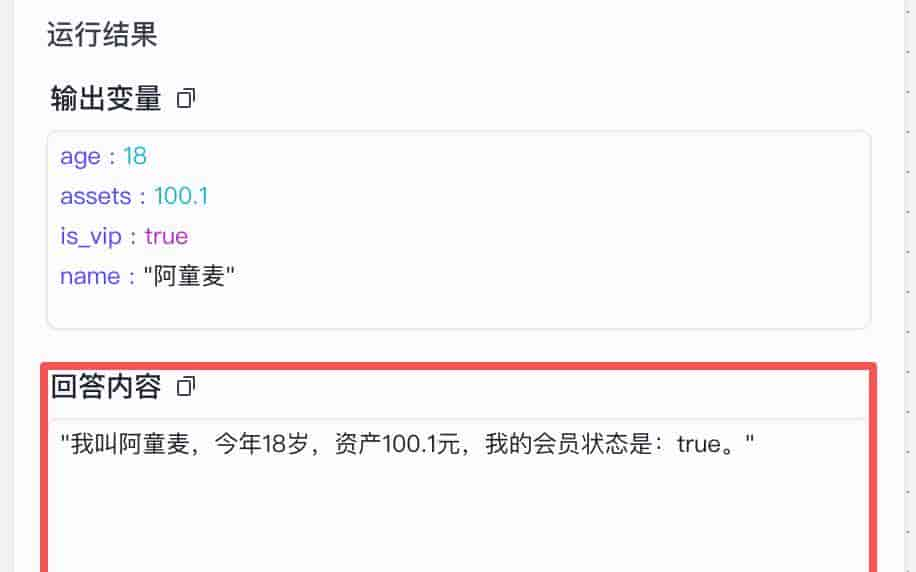
一句话理解:结束节点不会做任何处理,它只负责“拿结果”,并把结果“交出去”。
大模型节点
大模型,也叫大语言模型(英语:Large Language Model,LLM),它让工作流具备了“理解”和“生成”的能力,是整个流程中最重大的一环。
扣子工作流的核心在于通过 AI 来处理问题,而大模型节点,正是承载这一能力的关键节点,它让流程真正“活了起来”。
大模型节点可以做什么?
你肯定通过豆包、ChatGPT等来改写文案,问知识问题,这种智能体,背后的核心就是大模型。
我们在扣子工作流中也一样,通过大模型节点来处理文本相关的工作,列如生成视频的分镜脚本,成语故事的旁白文案,图片的提示词。
这里许多新手都有一个误区,觉得大模型节点是万能的,直接可以生成视频或者图片。这里要分清楚一点:大模型节点“不能做视频渲染和图片生成”,但可以参与视频、图片生成的前半段工作。
下面我对大模型节点的各个配置进行详细讲解。
模型
大模型节点可以选择许多模型,列如豆包、DeepSeek、Kimi等,每个模型官方都写明了介绍,适用于什么场景。
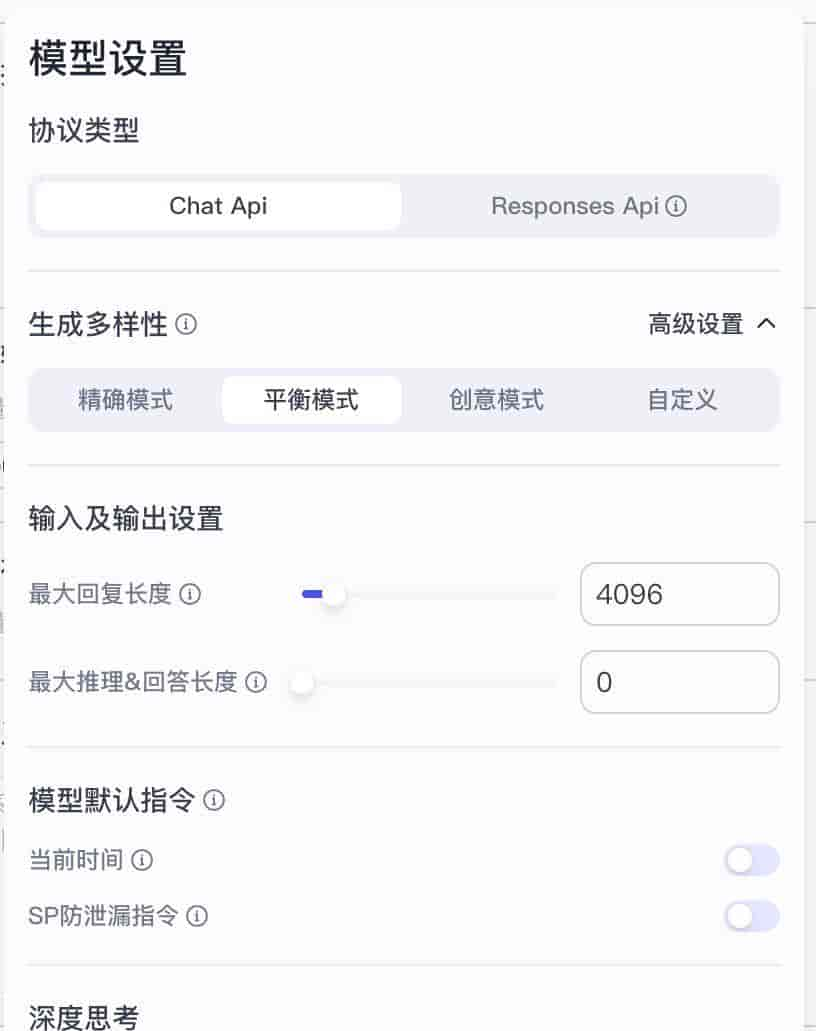
点击右边的「设置」按钮,还可以对模型进行更细化的设置。一般情况保持默认就可以,如果模型处理时间过长,可以把「深度思考开关」关闭。
技能
如果你直接问大模型:“今天天气怎么样?”,它没有办法直接告知你具体天气情况,而是让你通过其他查询方式来获取。
这是由于大模型本身不具备查询天气的技能,如果要让它实现查询天气,我们就需要对它配置技能。列如,我这边添加了“墨迹天气”的技能,给它赋予了查询天气的能力。

输入
输入用来接收其他节点输出的变量,我这边接收了开始节点的 input 变量。

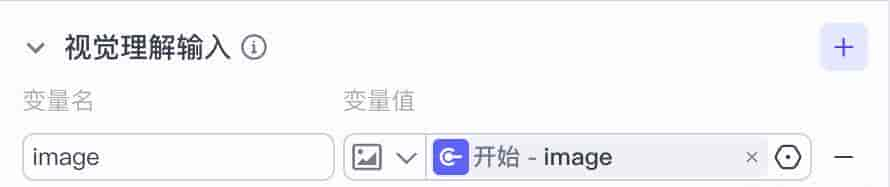
视觉理解输入
图片、视频这些数据,大模型节点通过“视觉理解输入”来接收,类似于上传功能。这样子模型可以获取并分析这些数据中的内容。
我这里接收了开始节点的 image 变量。
系统提示词
可以理解为:你在大模型节点里给 AI 定的身份 + 规则 + 工作方式。它是写给模型看的“最高优先级说明”,用来规定它该怎么思考、怎么输出、不能做什么。
列如你建一个“文章生成节点”,系统提示词可以这样写:“你是一个专业写作助手。你需要根据用户提供的主题生成一篇结构清晰的文章。文章必须包含标题、正文和总结。输出必须为中文,不要输出多余解释。”
系统提示词可以插入“变量”和“技能”,输入 {} 后就会弹出相应的“变量”和“技能”,点击添加就可以。
用户提示词
可以理解为:你在大模型节点里具体要 AI 处理的这一次任务内容。它和系统提示词的区别用一句话理解:系统提示词规定 AI “怎么做”,用户提示词告知 AI “做什么”。
用户提示词一样可以插入“变量”和“技能”,输入 {} 后和系统提示词一样操作。
这里要注意的是,你在输入中接收的变量,不会自动出目前用户提示词中,需要自己插入。

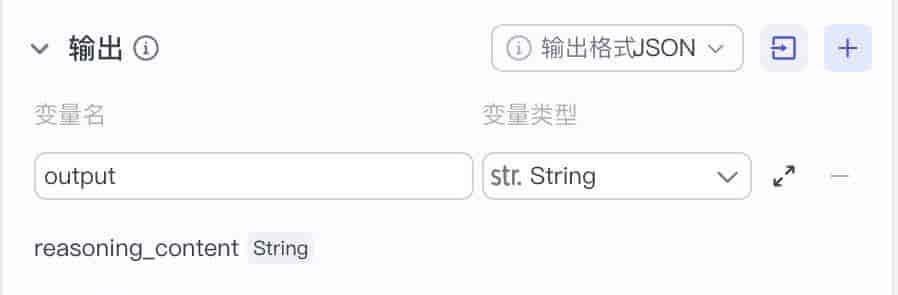
输出
把模型回答的内容,通过输出配置来传递变量,输出格式一般都是选择 JSON。
异常处理
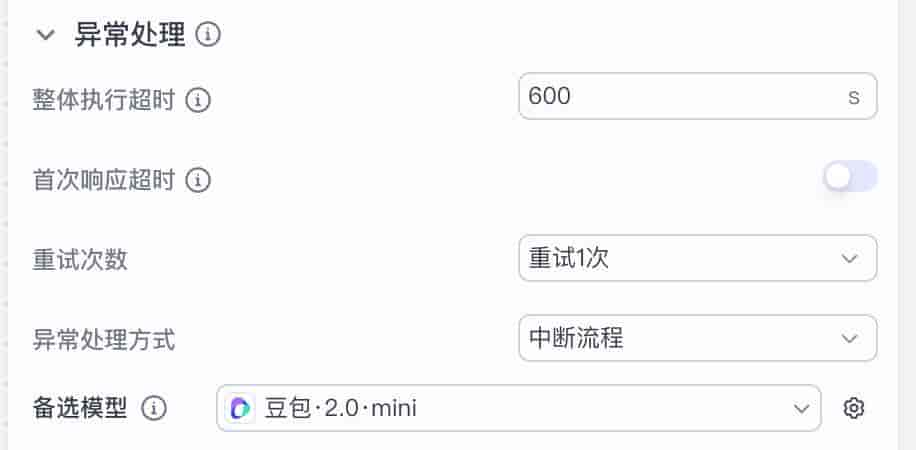
大模型实际工作中会有超时,导致我们的工作流没法正常运行,我们需要对其进行异常处理。
我这边把“整体执行超时”设置成最高 “600 s”,“重复次数”设置为“重试 1 次”,“异常处理方式“设置为“中断流程”,“备选模型”设置为“豆包 2.0 mini”。
按这样配置,大模型第一次如果超过 600 秒后还未处理完成,就会调用备选模型来执行第二次工作,如果第二次还是超时,那就中断整个流程。
大模型节点,是整个工作流的核心节点。如果说开始节点负责“输入”,结束节点负责“输出”,那么大模型节点,负责的就是中间最关键的一步:处理内容。
结语
许多人学工作流,一开始是在记“节点怎么用,参数这么配”。但慢慢你会发现,这些都不是最关键的。
真正决定你能不能把工作流做起来的,是另一件事:你有没有把“要解决的事情”拆清楚。
节点只是工具,模型只有能力。
当你能把一件事情拆清楚,每一步做什么,用哪个节点做,这个时候,你会发现:工作流,不再是“搭节点”,而是在“设计流程”。
你不再关心“这个节点能不能用”,而是会自然地想到:这一步,本来就应该用这个节点。
下一篇,我将通过为大模型节点添加技能,一步步带你完成一个简单实战:查询天气。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











