解放眼睛,一款将电子书转成有声书的开源工具
先听好了,这款工具叫:ebook2audiobook (github上2.4k star!)
https://github.com/DrewThomasson/ebook2audiobook
一句话描述咱功能:
使用动态AI模型和语音克隆将电子书转换为带有章节和元数据的有声读物,已支持1,100+种语言!
使用技术名词再描述下(要不显得不专业):
ebook2audiobook工具是一款从电子书到带有章节和元数据的有声读物的CPU/GPU转换器,用到Calibre、ffmpeg、XTTSv2、Fairseq等开源技术方案,并且支持语音克隆。
没懂?估计还不清楚到底这玩意干嘛的?
那这么说吧,就是如果你有一本英文版电子书(正版pdf哦),不用在屏幕上盯着看,这款工具帮您把pdf整本转换成音频了,这样你可以在闲暇或者上班期间带上耳机,随时“听书”。
它的厉害之处是还可以上传一段你自己的语音,然后根据你的语音进行学习和克隆,用自己的语音进行转换,这是不是有点逆天了!
pdf转后之后生成的“音频书”
ebook2audiobook的具体特性如下:
使用 Calibre 将电子书转换为文本格式。
将电子书拆分为多个章节,以便有组织的音频。
️ 使用 Coqui XTTSv2 和 Fairseq 实现高质量的文本转语音。
️ 使用您自己的语音文件进行可选的语音克隆。
支持 1107 种语言(默认为英语)。支持的语言列表
️ 设计为在 4GB RAM 上运行。
Huggingface上已经有现成的demo可以体验哈(需要科学上网),Huggingface的免费cpu上运行的demo里,转换速度会超级慢或出现超时,哈哈,上百页的pdf大文件就别想了,可以试试小数据量,列如先用单页面的txt文件尝尝鲜:)
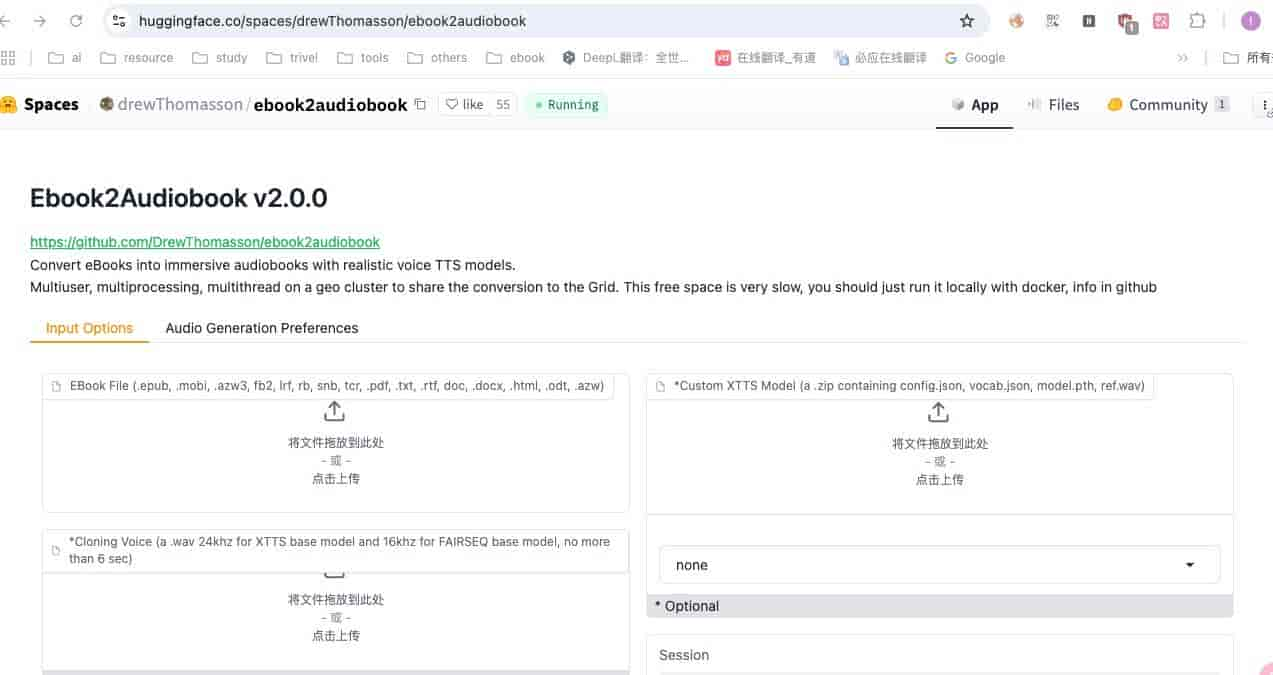
Huggingface-demo
ebook2audiobook部署:
Clone repo 下载代码
git clone https://github.com/DrewThomasson/ebook2audiobook.git
启动 Gradio Web 界面
Linux/MacOS下为例:
./ebook2audiobook.sh # 运行 Launch 脚本
命令行方式下headless方式运行
./ebook2audiobook.sh –headless –ebook <path_to_ebook_file> –voice [path_to_voice_file] –language [language_code]
关于命令的详细参数指南,其中包含要使用的所有参数的列表
Linux/MacOS下:
./ebook2audiobook.sh –help
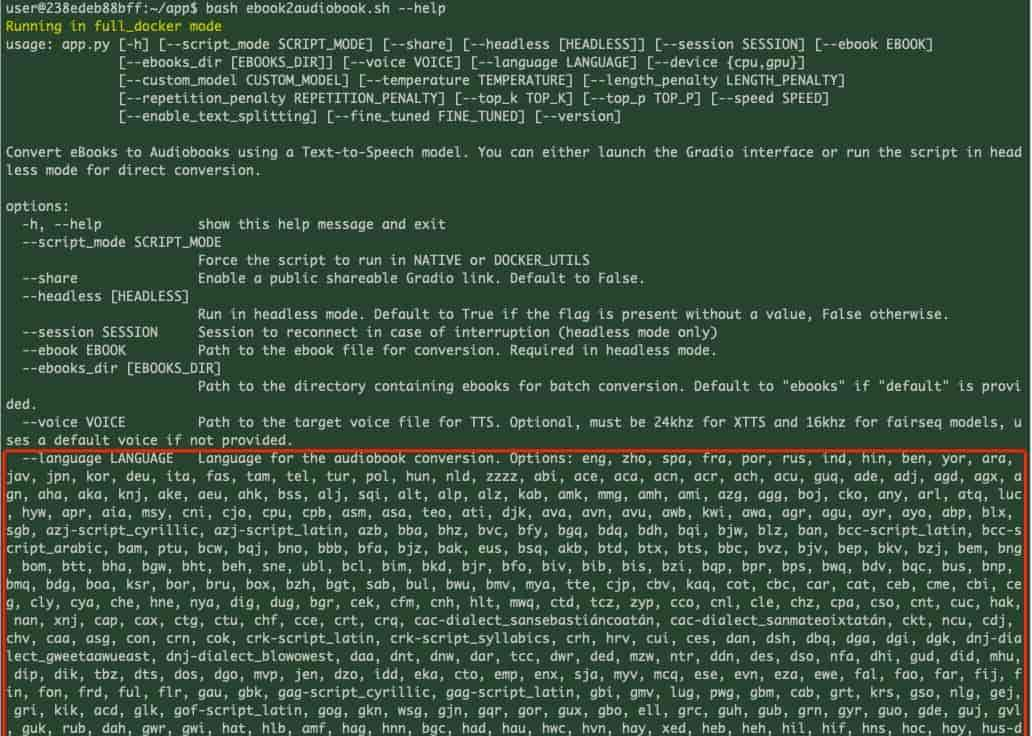
ebook2audiobook.sh –help (1)
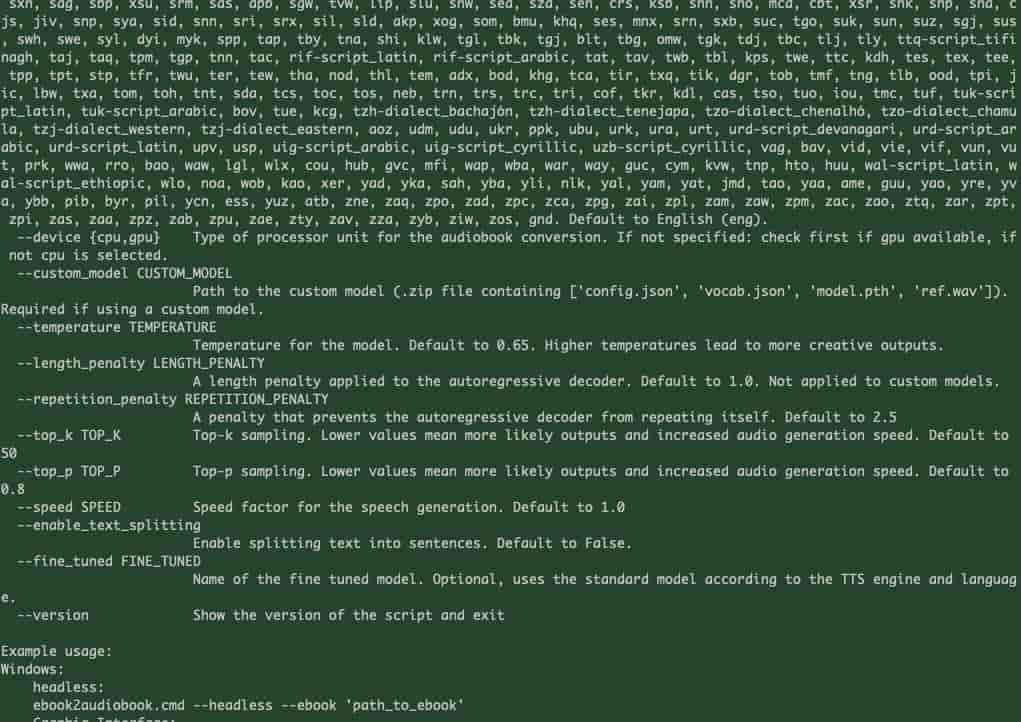
ebook2audiobook.sh –help (2)
OK,接下来我们还是实战体验!
依然,我的环境还是在Ubuntu24下使用以Docker方式部署:
第一下载镜像,镜像有点大:13.7G左右
docker pull athomasson2/ebook2audiobookxtts:huggingface
查看镜像大小
docker ps | grep ebook2audiobookxtts
athomasson2/ebook2audiobookxtts huggingface 2d85fa70c4d2 4 days ago 13.7GB
docker-compose文件
$ cat docker-compose.yml
x-gpu-enabled: &gpu-enabled
devices:
- driver: nvidia
count: all
capabilities:
- gpu
services:
ebook2audiobookxtts:
image: athomasson2/ebook2audiobookxtts:huggingface
platform: linux/amd64
tty: true
stdin_open: true
ports:
- 7860:7860
environment:
- share=True
command: python app.py
deploy:
resources:
reservations:
<<: *gpu-enabled
#change this to gpu-enabled if you have an NVIDIA gpu启动服务
docker-compose up -d
服务启动之后,可以使用浏览器web访问
http://Your-IP:7860
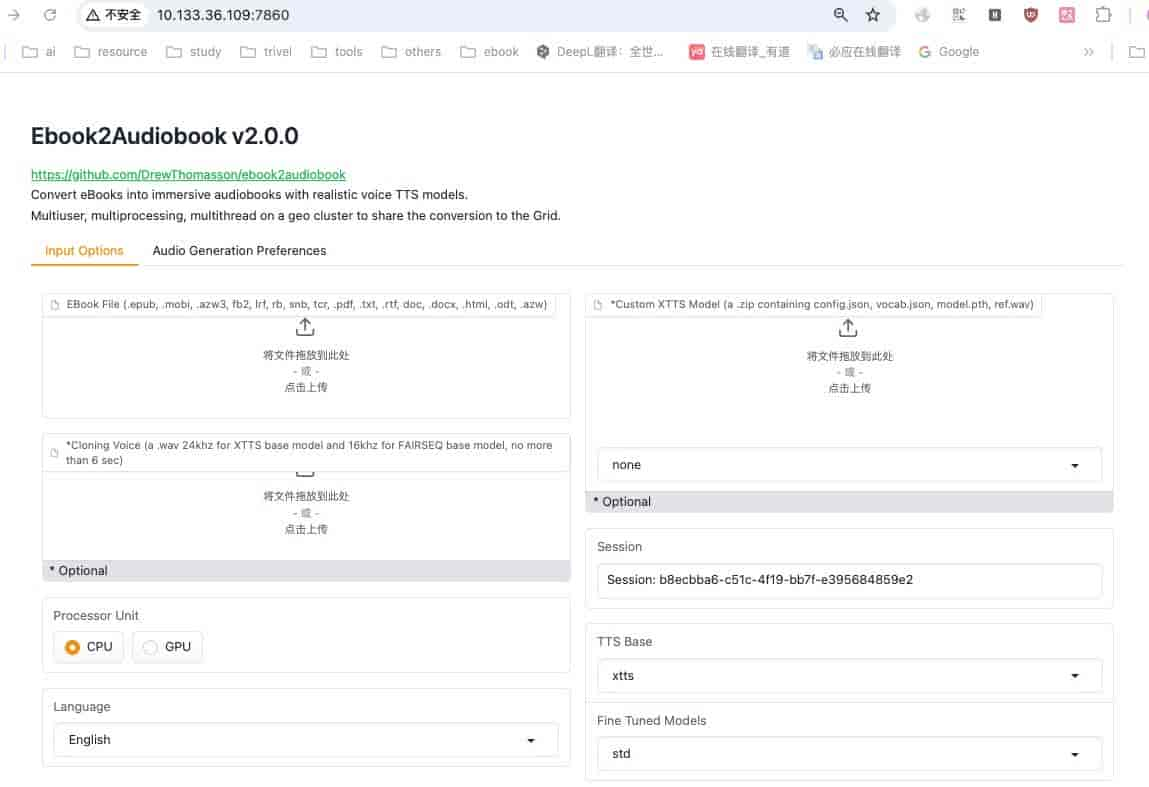
首页
既然环境已经好了,接下来看看具体使用吧!
第一使用单页的txt文件试试,文件内容来自项目在github上的readme文件,我选了几十行另存为”t.txt”
cat t.txt
CPU/GPU Converter from eBooks to audiobooks with chapters and metadata
using Calibre, ffmpeg, XTTSv2, Fairseq and more. Supports voice cloning and 1124 languages!
Important
This tool is intended for use with non-DRM, legally acquired eBooks only.
The authors are not responsible for any misuse of this software or any resulting legal consequences.
Use this tool responsibly and in accordance with all applicable laws.
...
...
Discord
New v2.0 Web GUI Interface!
demo_web_gui
Click to see images of Web GUI
README.md
en English
Table of Contents
ebook2audiobook
Features上传t.txt
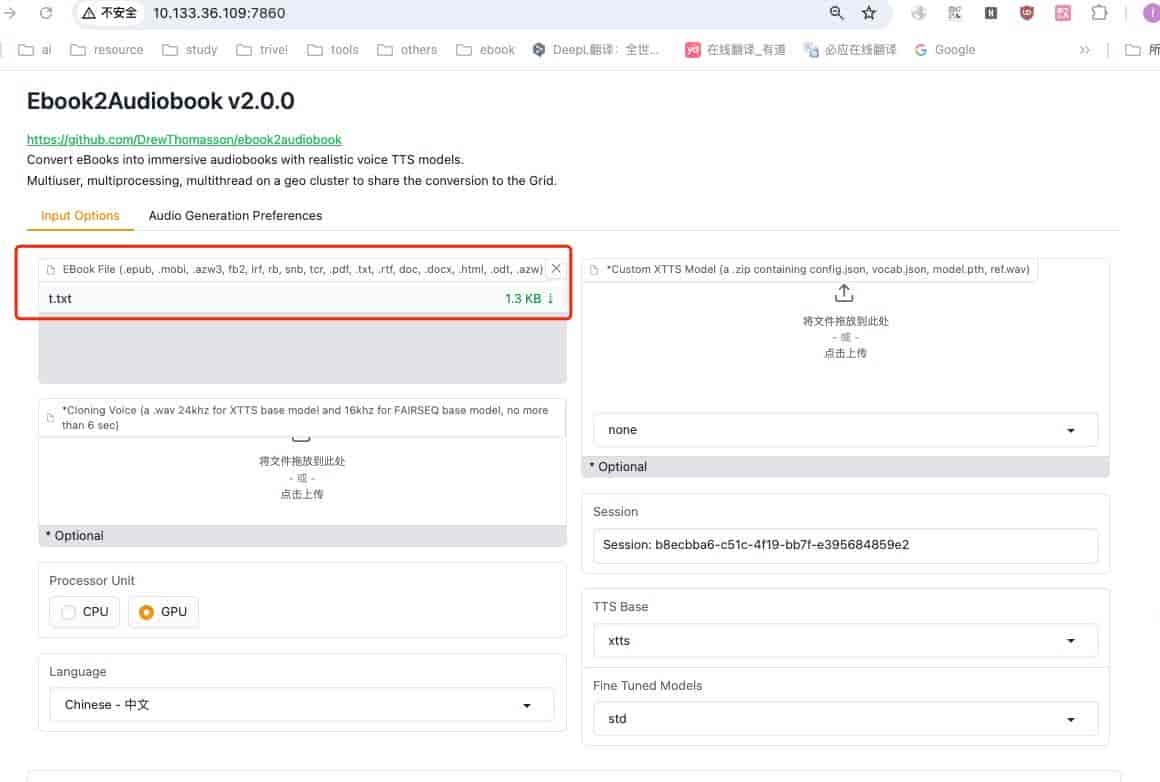
上传文本文件进行测试
然后点击convert转换,这时就能看到转换进度了,我这使用了GPU,单页面的转换速度看着还可以,这是后台日志:
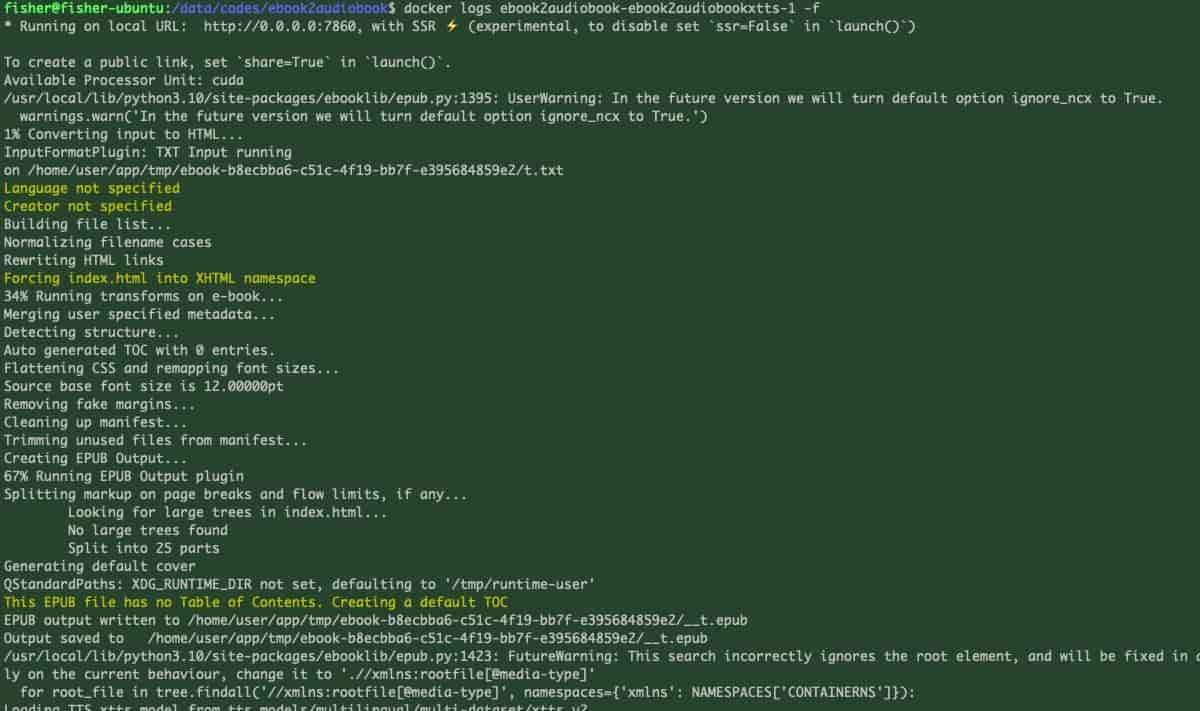
转换日志(1)
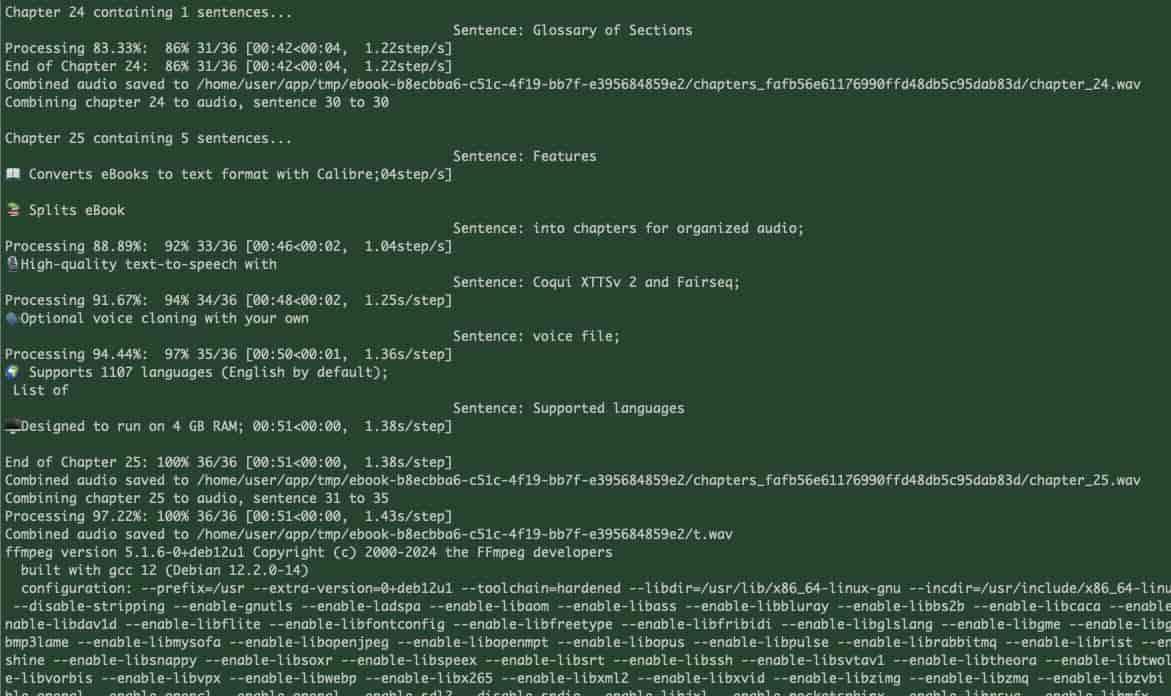
转换日志(2)
转换完成
此时生成了一个2.2M的语音文件,可以从页面直接点击收听。
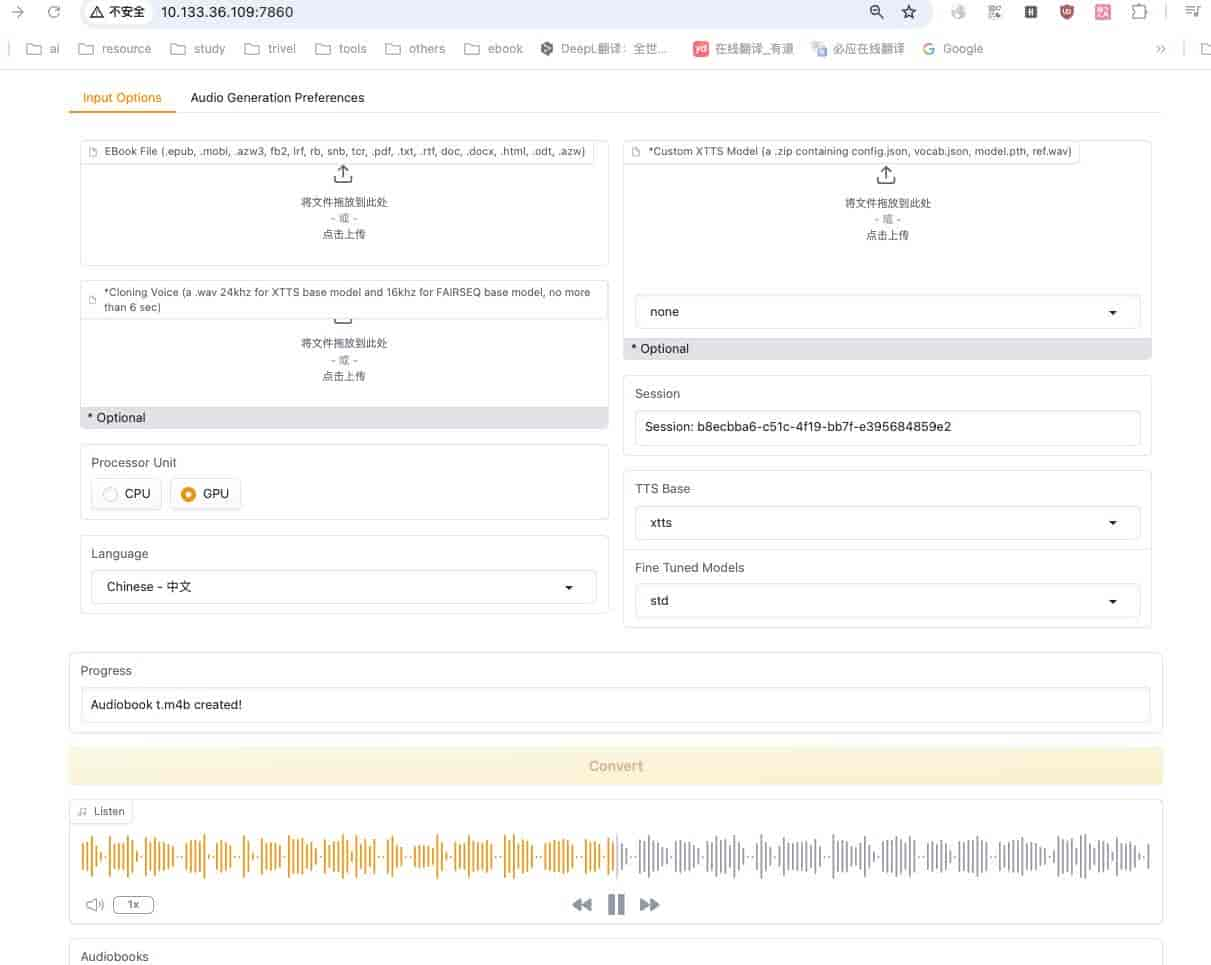
转换成功,生成音频文件
生成的音频文件格式为:m4b
txt文本中的是英文,我选的是转换成中文,不过最后生成的音频有点让人一言难尽,中文并没有生效,音频还是英文,不过咋是带口音的呢,而且是一种带有印度咖喱味和小日子的咕噜咕的口音。
转换整本pdf
上次测试中文没生效,我怀疑本地并没有中文原声,找了一下的确 没有,估计需要单独下载。
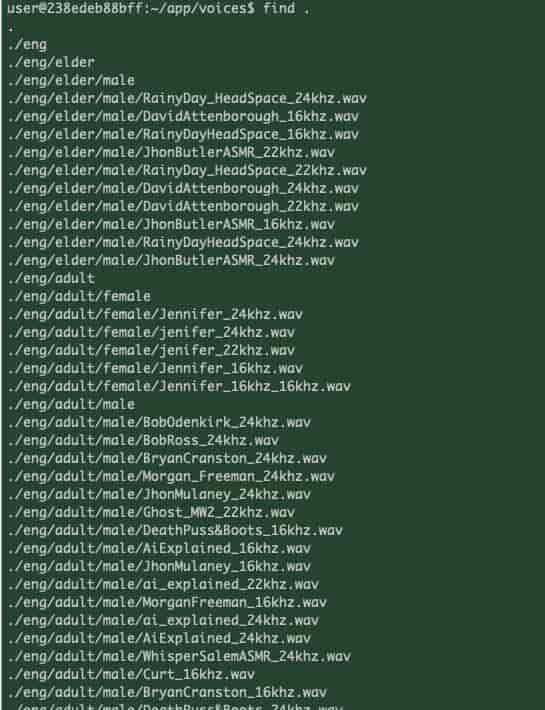
本地语音文件
好吧,那这次的话我选择一个多页的pdf文件,没中文那咱就用纯正的英文转换试试,书籍名字叫《AWS_DevOps》一共22页,哈哈,也不是许多。
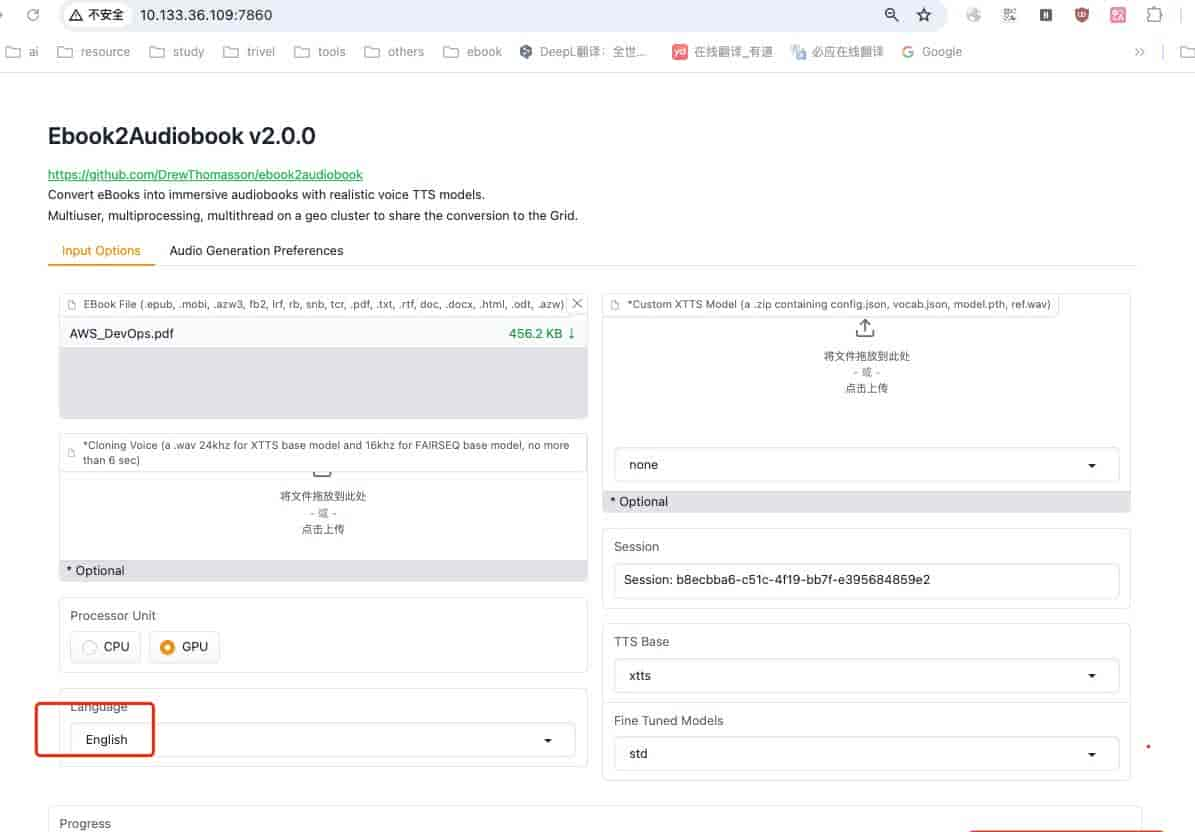
上传pdf
参数微调
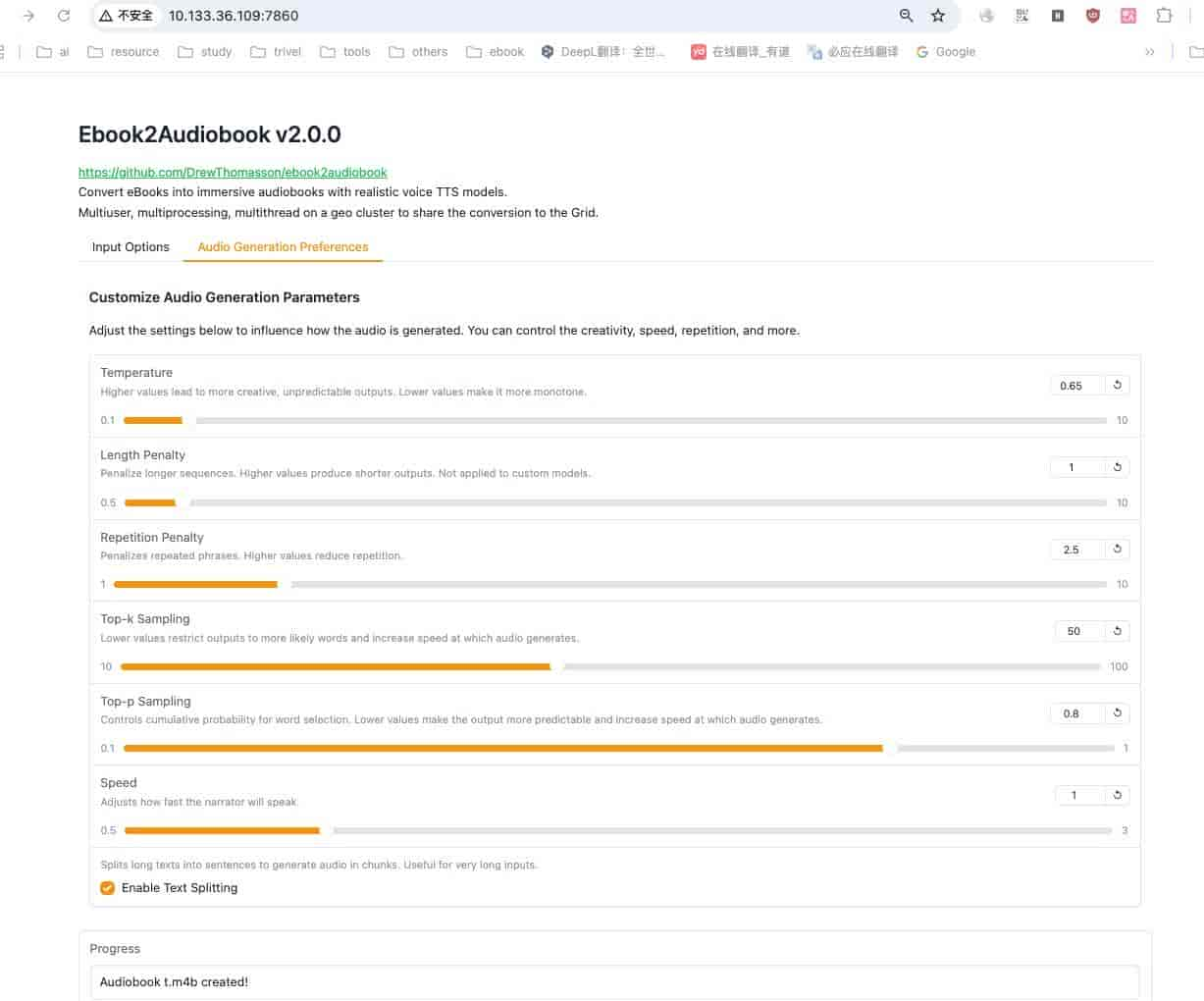
参数
开始转换,并查看日志:
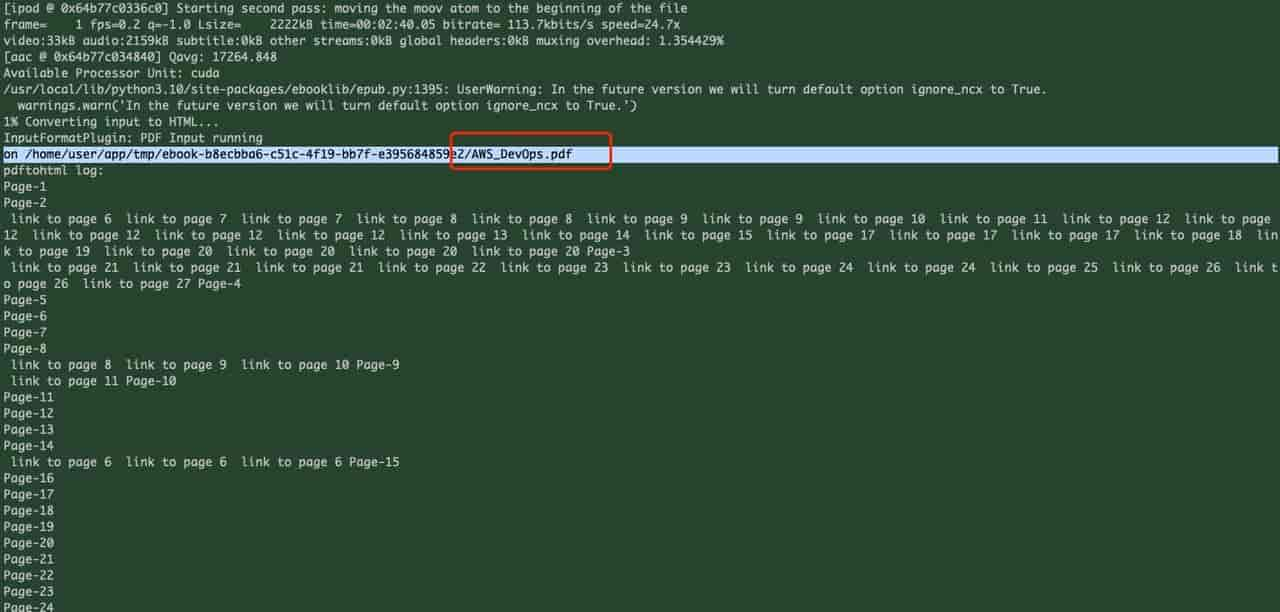
上传及转换日志
先看看原pdf啥样

原pdf(1)

原pdf(2)

原pdf(3)
转换时间比较漫长
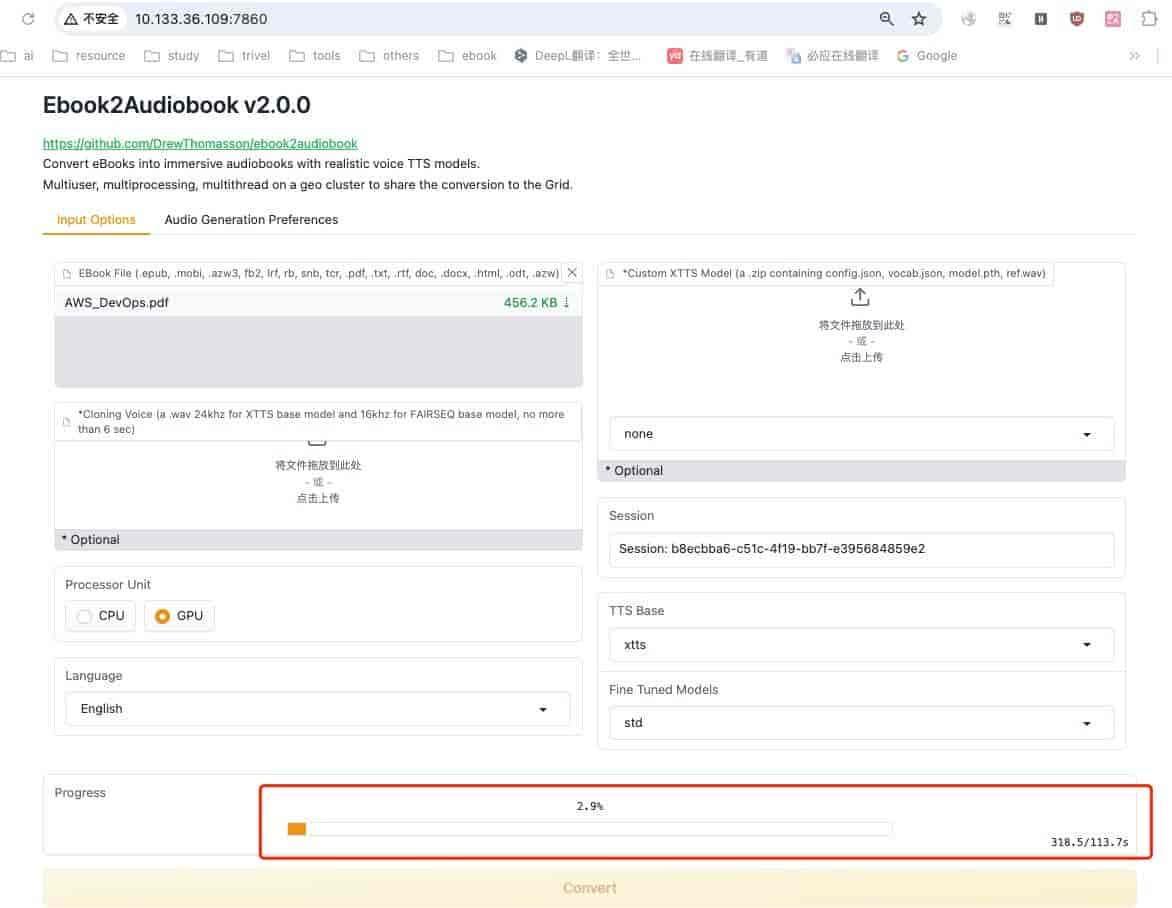
转换中
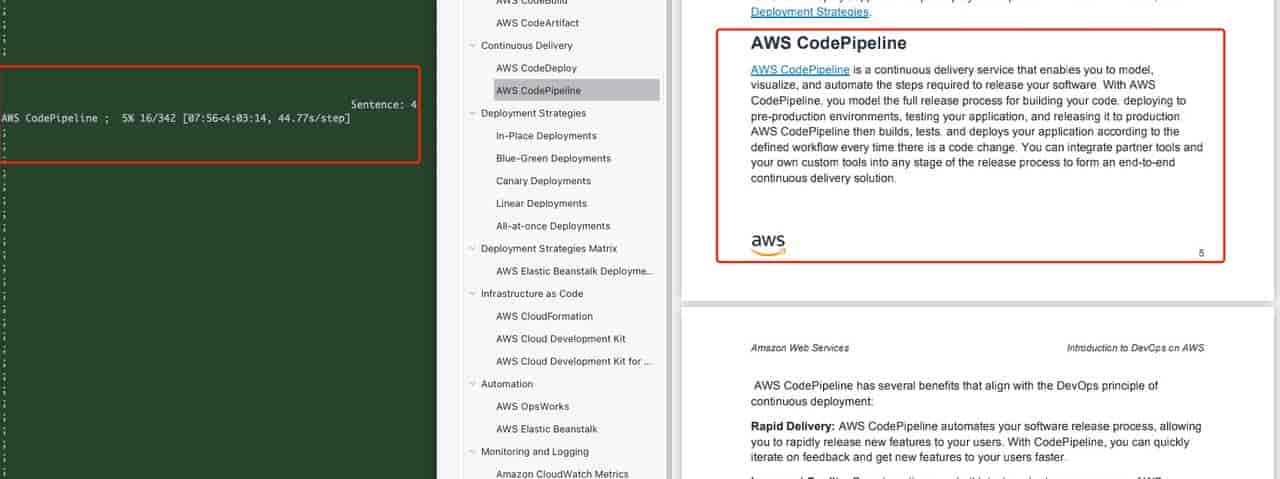
看看对应关系
耗时很长,期间可以看到音频是分章节的
分章节
转换完成
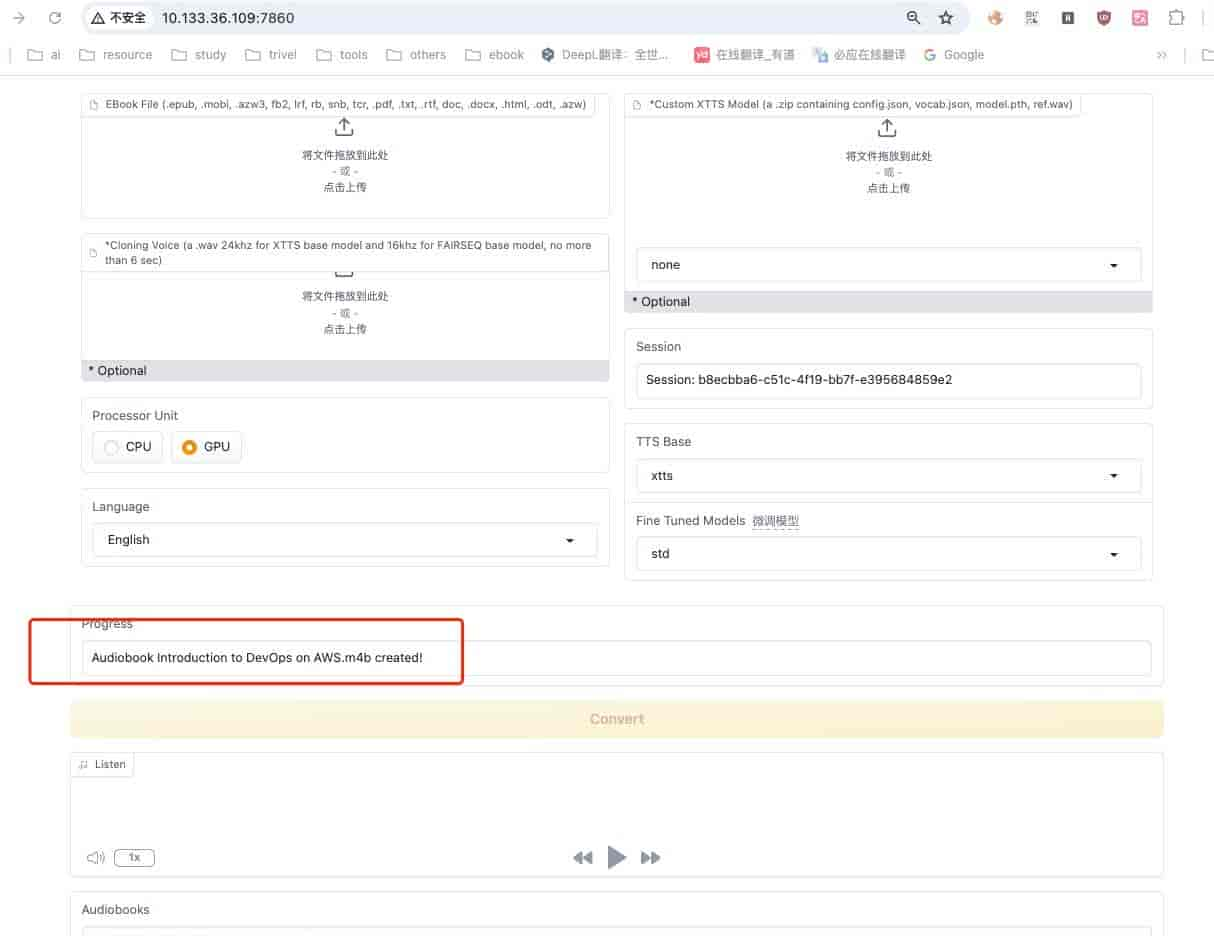
转换完成
这里生成了一个136M的大音频文件,可以从页面直接下载下来,服务器里面也能看到。

file size
下载到本地后,mac下使用图书打开这个m4b文件
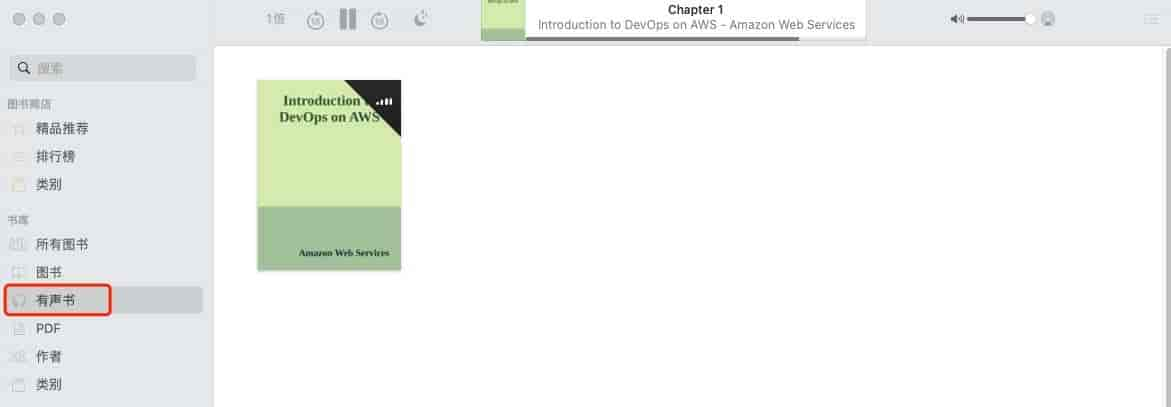
mac下使用图书打开m4b语音文件
这会我大致听了下,口音纯正,美式女生的发音很标准。
提出一个提议:如果能够能让音频跟文本匹配并且同步显示的话就更好了。
看着是真挺牛的,好奇心驱动下,跟大家一块再看看ebook2audiobook用到的底层技术及方案吧。
Calibre
github地址:
https://github.com/kovidgoyal/calibre 20.2K star
这伙计叫电子书管理器。
- 可以查看、转换、编辑和编目所有主要电子书格式的电子书。
- 可以与电子书阅读器设备通信。
- 可以访问互联网并获取您书籍的元数据。
- 可以下载报纸并将其转换为电子书以方便阅读。
- 跨平台,可在 Linux、Windows 和 macOS 上运行。
各种仓库中的 calibre 软件包版本:
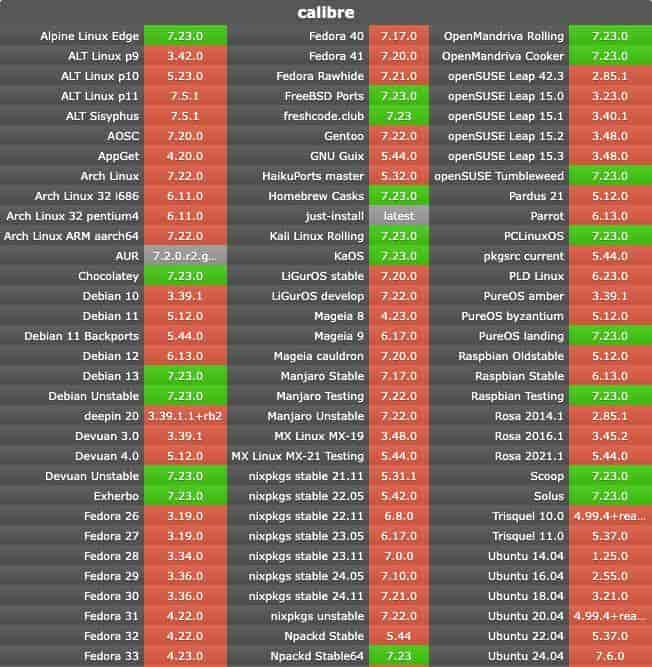
version
FFmpeg:
FFmpeg信任许多人已经很熟悉了,业界音视频处理底层基本都有它的影子。
FFmpeg是一个开源的、跨平台的命令行工具,用于处理各种多媒体文件。它支持录制、转换、流化音视频,几乎能处理任何格式的音频和视频。
Coqui XTTSv2
是一款用于文本转语音的深度学习工具包,是久经时间考验的工具。
github地址:
https://github.com/coqui-ai/TTS
huggingface地址:
https://huggingface.co/coqui/XTTS-v2
TTS是一种语音生成模型,可用于Text2Speech任务的高性能深度学习模型,可让您仅使用一个6秒的快速音频剪辑将语音克隆为不同的语言,无需跨越无数小时的过多训练数据,支持多扬声器,拥有高效、灵活、轻量级但功能齐全的Trainer API。
Fairseq
github地址:https://github.com/facebookresearch/fairseq
Fairseq(-py) 是一个序列建模工具包,允许研究人员和开发人员为翻译、摘要、语言建模和其他文本生成任务训练自定义模型。
主要特性:
- 在一台机器上或跨多台机器进行多 GPU 训练(数据和模型并行)
- 多样化光束搜索
- 可扩展:轻松注册新模型、标准、任务、优化器和学习率调度器
- 全参数和优化器状态分片
好了,以上介绍您是否对ebook2audiobook有初步的了解呢?反正我认为是我这种“耳机党”听技术书的福音,电子书转换成音频书籍的确 要花费一些时间,我这使用GPU(显卡太次GTX1080)的情况下22页跑了一个小时左右。
GPU跑模型
这个时间我可以接受,毕竟让pdf转换在后台跑就行了,时间上也不是啥问题,毕竟开源工具能做到这样,我只能大大的点赞和加星(all start!)
(全文完)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...