
万字长文:深入解析“上下文工程”(Context Engineering)——驾驭百万Token时代的AI性能缰绳:五种典型的“上下文失效”模式与解决方案
Effective context engineering for AI agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
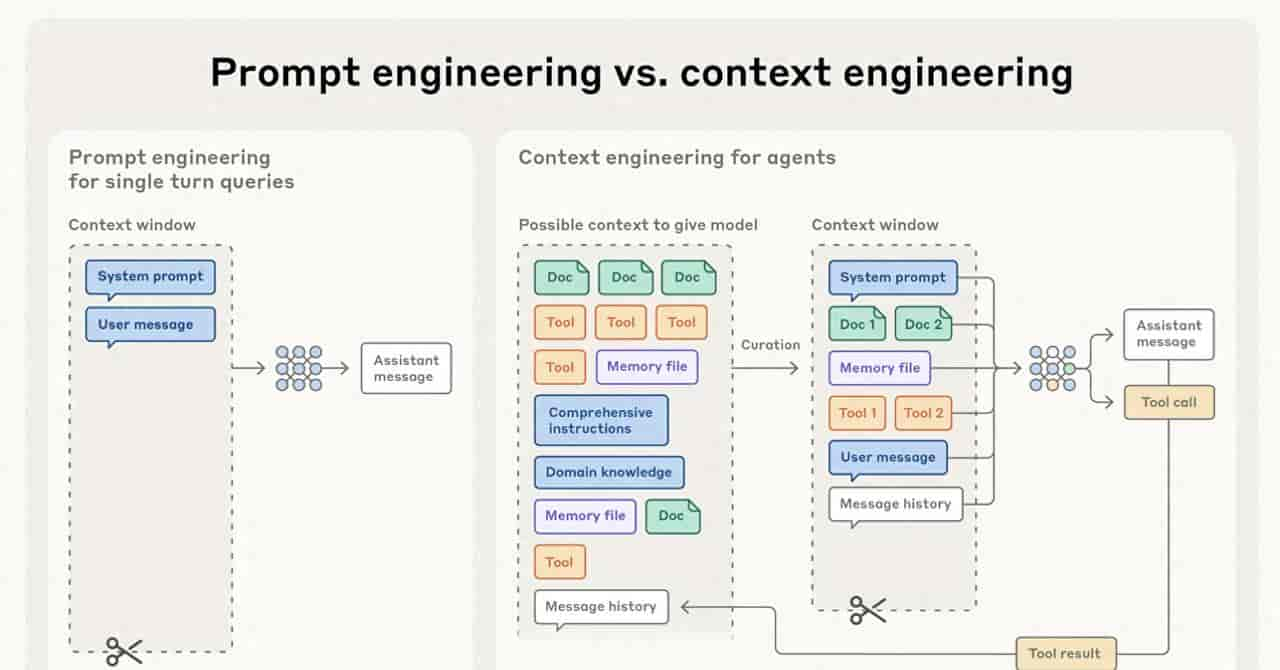
我们将上下文工程视为提示工程的自然发展。提示工程是指编写和组织 LLM 指令以获得最佳结果的方法。 上下文工程是指在 LLM 推理过程中策划和维护最佳标记(信息)集的一组策略,包括提示之外可能出现的所有其他信息。
上下文工程代表了我们使用 LLM 构建方式的根本性转变。随着模型功能越来越强劲,挑战不仅在于设计完美的提示,还在于精心策划在每一步中哪些信息可以进入模型有限的注意力预算。无论您是为长期任务实施压缩,设计高效的标记工具,还是使代理能够实时探索其环境,指导原则始终不变:找到最小的高信号标记集,以最大化实现期望结果的可能性。
万字长文:深入解析“上下文工程”(Context Engineering)——驾驭百万Token时代的AI性能缰绳
引言:当“无限”上下文遇到“有限”的注意力
2025年,我们正处在一个激动人心的AI技术拐点。百万级Token的上下文窗口已经从遥不可及的梦想,变成了开发者们可以触及的现实。从Anthropic的Claude系列到Google的Gemini家族,再到OpenAI的GPT模型,超长上下文似乎正在成为新一代大语言模型(LLM)的“标配”。理论上,这意味着AI能够“记住”并处理整本书、完整的代码库,或长达数小时的会议记录。
不过,一个更大的上下文窗口,并不直接等同于一个更机智、更可靠的AI。恰恰相反,当上下文的长度跨越某个阈值(例如,几十万Token)后,一系列诡异的性能衰减问题开始浮现,如同物理学中从宏观进入微观世界时,熟悉的定律不再适用。
就在几个月前,开发者兼思想家Drew Breunig发表了一篇极具影响力的博客文章《上下文如何失效以及如何修复它们》(How Contexts Fail and How to Fix Them),系统性地揭示了长上下文背后的“诅咒”。这篇文章犹如一声惊雷,让整个AI社区开始正视这个难题,并催生了一门新兴的、至关重大的学科——上下文工程(Context Engineering)。
上下文工程,顾名思义,是一套旨在管理、优化和构建LLM上下文,以最大限度地发挥其性能、规避其内在缺陷的理论、策略与技术实践的总和。它承认,上下文窗口并非一个可以无限填充而无副作用的“垃圾桶”,而是一个需要精心设计的“认知工作区”。
在这篇万字长文中,我将以Breunig的洞见为起点,结合业界(如Anthropic、Cognition、Manus.io等)的最新实践,以及我自身处理信息的经验,全面、深入地剖析上下文工程的两个核心命题:上下文为何会失效(The Problems)以及我们该如何修复它(The Solutions)。这不仅是对当前技术挑战的梳理,更是对未来构建高效、可靠AI Agent的一次深度思考。
什么是上下文工程?
第一部分:长上下文的诅咒——五种典型的“上下文失效”模式
当我们把巨量信息不加筛选地塞进模型的上下文窗口时,就如同让一个人在充斥着数万本书、无数对话和持续噪音的房间里专注于一项任务。即便这个人记忆力超群,其认知负荷也终将达到极限,导致判断失准、效率低下。LLM也是如此,其底层的Transformer架构虽然强劲,但其注意力机制并非万能。以下是五种最常见的上下文失效模式。
1. 上下文中毒(Context Poisoning)
定义:指模型在处理长上下文时,被其中错误、虚构或不相关的信息“污染”,导致其产生幻觉,并基于这些幻觉做出后续的、持续错误的判断与行动。
典型案例:Breunig在他的文章中提到了一个绝佳的例子:Gemini在玩《口袋妖怪》游戏时,在长上下文中“幻觉”出了一个本不存在的道具(例如,“万能钥匙”)。这本身是一个小错误。但“中毒”的可怕之处在于,模型随后会坚信这个幻觉产物的存在,并在接下来的几十甚至上百步操作中,反复尝试使用这个“万能钥匙”去开门,导致整个任务陷入死循环,彻底偏离正轨。
深层缘由:
注意力稀释:在巨大的上下文中,所有信息都在争夺模型的“注意力”。 一个偶然的、微小的幻觉,与其他成千上万的真实信息token混杂在一起,模型很难在没有明确纠正指令的情况下,自我识别并否定这个内部产生的信息。
一致性偏见:模型倾向于保持其输出的一致性。一旦它生成了某个“实际”(即使是幻觉),在后续的推理中,它会倾向于遵循这个“实际”,以维持逻辑上的连贯性。这种偏见在短上下文中可能被很快纠正,但在长上下文中,纠正成本(需要回溯和否定的信息量)呈指数级增长。
我的思考:上下文中毒就像是AI的“思想钢印”。一旦某个错误的观念被植入,后续所有的推理都会被扭曲。在软件开发场景中,一个Agent可能“中毒”地认为某个API存在一个实际上没有的参数,并花费大量时间去调试这个“幽灵”参数,最终导致项目延期。
2. 上下文分心(Context Distraction)
定义:当上下文变得极其庞大时,模型会“忘记”其最初的核心任务或高层计划,转而倾向于执行重复性的、低价值的或在上下文中近期出现过的行为。
典型案例:Breunig观察到,当上下文超过10万个Token时,Gemini在执行复杂任务时,会放弃原有的、精妙的计划,转而开始重复之前已经做过的动作。列如,一个本应编写新功能的编程Agent,可能会开始反复检查同一个文件的格式,或者不断地列出同一个目录的内容。
深层缘由:
“迷失在中间”(Lost in the Middle):多项研究表明,模型对上下文开头(系统提示、初始指令)和结尾(最新用户输入)的信息关注度最高,而对中间部分的信息关注度则显著下降。当上下文极长时,最初的“宏伟蓝图”就埋藏在浩瀚的“中间地带”,被模型“选择性遗忘”。
近期行为锚定:模型的注意力机制天然地对最近的Token更为敏感。因此,它更容易被最近执行过的操作(如 ls -la)或最近看到的输出所“锚定”,从而产生一种“惯性”,不断重复这些操作,而非去遥远的上下文“深处”挖掘那个更重大但更遥远的原始计划。
我的思考:上下文分心是长上下文环境下AI“意志力”的丧失。它揭示了当前模型在没有外部辅助的情况下,进行长期、多步骤规划的内在困难。这就像一个项目经理在连续工作了36小时后,忘记了项目的最终交付目标,而只记得自己一直在回复邮件。
3. 上下文混淆(Context Confusion)
定义:向模型提供过多,尤其是功能类似或描述模糊的工具(Tools/Functions)时,模型的性能会显著下降。它会难以选择正确的工具,或者在调用工具时传递错误的参数。
典型案例:假设我们正在构建一个旅行预订Agent。我们为它提供了三个工具:search_flights(destination, date),find_cheapest_flights(location, month) 和 get_flight_deals(city, timeframe)。这三个工具的功能高度重叠,描述也类似。当用户说“帮我找下个月去巴黎的便宜机票”时,模型可能会陷入“选择困难症”,或者错误地调用了 search_flights 并尝试传入一个 month 参数,导致调用失败。模型拥有的工具越多,这种混淆的概率就越高。
深层缘由:
语义类似性干扰:模型的工具选择能力,本质上是基于用户意图与工具描述之间的语义类似度匹配。当多个工具的描述在向量空间中超级接近时,模型就很难做出明确的区分。
认知过载:在每次推理时,模型都需要评估所有可用工具是否适用。当工具有数百个之多时,这个评估过程本身就构成了巨大的计算和认知负担,增加了出错的可能性。这就好比给一个厨师一本包含一万个食谱的菜单,让他为一位点菜模糊的顾客快速做决定。
4. 上下文冲突(Context Clash)
定义:当模型连续执行的两个或多个工具调用/动作在逻辑上相互矛盾或目标冲突时,模型的性能会下降,甚至导致任务失败。
典型案例:一个金融交易Agent,在前一个步骤中根据市场分析决定“在价格低于$100时买入10股A公司股票”,但在紧接着的下一个步骤中,可能由于上下文中的某个微弱信号(列如一条旧闻)的干扰,又生成了一个“立即卖出所有A公司股票”的指令。这两个背靠背的矛盾指令会导致系统逻辑混乱,或者造成实际的经济损失。
深层缘由:
状态管理不善:在长上下文中,模型很难维持一个连贯、一致的“世界状态”或“自身状态”。它可能在一个时间片内基于context_slice_A做出了决定A,在下一个时间片内又基于context_slice_B做出了与A冲突的决定B,而没有意识到这两个切片共同构成了一个需要一致性处理的整体。
多目标优化失败:复杂的任务往往包含多个子目标。在长上下文中,模型可能会在不同步骤中过分专注于不同的子目标,而忽略了它们之间的内在联系和潜在冲突,导致“按下葫芦浮起瓢”。
5. 性能与成本的隐性衰减
除了上述四种明显的“行为异常”,长上下文还带来了一个更普遍的问题:性能的普遍下降和成本的急剧上升。模型处理的Token越多,其响应延迟就越高,计算成本(无论是API费用还是本地部署的硬件资源)也越大。更重大的是,正如“迷失在中间”现象所揭示的,信息的增加并不总带来正面效益,有时反而会由于信噪比的降低,导致模型在基础问答、文本生成等任务上的准确率和创造力下降。
总结来说,这五大“诅咒”共同指向一个结论:上下文不是越多越好。我们必须从一个“信息投喂者”转变为一个“上下文建筑师”,主动地、智能地管理模型的认知空间。这正是“上下文工程”的用武之地。
第二部分:驾驭缰绳——上下文工程的五大核心策略
既然我们已经诊断了病症,接下来就要对症下药。上下文工程提供了一系列精妙的策略,它们的核心思想可以归结为:将无限的外部信息,转化为有限但高效的、AI可消费的上下文。
1. 上下文卸载(Offload Context)
核心思想:不要把所有东西都塞进上下文窗口。将上下文窗口视为昂贵、高速但易失的“内存(RAM)”,而将文件系统、数据库等外部存储视为廉价、大容量但稍慢的“硬盘(Hard Drive)”。让AI学会读写“硬盘”。
具体实践:
使用文件系统进行笔记(Notes):当Agent需要进行长期思考或在多个步骤中积累信息时,可以赋予它读写一个notes.md文件的能力。例如,一个研究员Agent在分析一篇论文时,可以一边阅读PDF,一边将关键发现、引用和自己的想法写入notes.md。这样,即使对话历史被清空,核心的思考成果也被持久化了。这正是Anthropic在其多Agent协作框架中实践的方法。
使用文件系统进行规划与进度跟踪:对于复杂的多步骤任务,可以引入一个todo.md文件。Agent在开始时读取todo.md来了解任务列表,每完成一项就在文件上标记(例如,用 [x] 替换 [ ]),然后读取下一项。这种方式将任务状态从易失的上下文中“卸载”到了稳定的文件系统中。Manus.io的Agent就精于此道,它通过维护一个任务清单来确保自己不会“分心”或“迷失”。
读写Token密集型上下文:当需要处理一个巨大的文件(如一个10MB的JSON或日志文件)时,强行塞入上下文是低效且昂贵的。更好的方法是让Agent拥有read_file_chunk(file, start_line, end_line)和write_to_file(file, content)这样的工具。Agent可以流式地读取、处理和写入数据,将上下文窗口始终保持在一个可控的范围内。
利用文件实现长期记忆:用户的偏好、过去的对话摘要、项目的特定配置……这些信息对于提供个性化体验至关重大,但又不必时刻占据上下文。可以将它们存储在preferences.json或memory.txt等文件中。在会话开始时,Agent可以读取这些文件来“加载”长期记忆。Ambient Agents的相关课程和代码库就深入探讨了如何构建这种基于外部文件的记忆系统。
上下文卸载是解决上下文分心和降低成本最直接有效的手段。
2. 上下文缩减(Reduce Context)
核心思想:如果信息必须存在于上下文中,那就让它尽可能地简短和精准。对进入上下文的信息进行“有损压缩”,用更少的Token承载最核心的语义。
具体实践:
总结Agent消息历史:随着对话的进行,上下文中的消息历史会迅速膨胀。可以实现一个“滚动总结”机制。例如,每当对话超过N条消息时,就调用一次LLM,将最早的N/2条消息总结成一句话,替换掉原文。Claude Code等编码助手就采用了类似策略,将冗长的代码迭代历史总结为“功能已实现,待修复Bug X”等关键信息。
修剪不相关的消息历史:比总结更进一步的是修剪。可以设定规则,自动删除或折叠那些对当前任务目标贡献不大的部分,例如用户的寒暄、Agent调用失败的工具日志、重复的调试输出等。Drew Breunig也提倡这种更具侵略性的修剪策略。
总结/修剪工具调用输出:许多API或工具的返回结果超级冗长(verbose),可能是一个包含大量元数据的庞大JSON对象。Agent往往只关心其中的一两个关键字段。可以在工具调用后增加一个“后处理”步骤,用一个专门的提示词(Prompt)或另一个小模型调用,将原始输出总结成最终用户或下一步Agent需要的信息。open-deep-research等开源项目中有许多关于如何精炼工具输出的探索。
在Agent间交接时进行总结:在多Agent协作系统中,当一个Agent(如“需求分析师”)将任务移交给下一个Agent(如“软件架构师”)时,不应该直接把它的全部工作历史丢过去。正确的做法是,让“需求分析师”Agent在完成工作后,生成一份简洁、结构化的“交接文档”(Briefing Document),只包含架构师需要知道的核心需求、约束和上下文。
重大警示:警惕信息丢失! Cognition和Manus.io的经验都表明,过度或不当的缩减会导致关键信息的丢失。一个看似无用的错误日志,可能恰恰是解决问题的关键线索。因此,缩减策略必须足够智能。可以思考:
分层总结:保留不同粒度的摘要,允许Agent在需要时“钻取”到更详细的版本。
保留元数据:在总结时,保留指向原始信息的索引或指针,以便在必要时进行回溯。
智能修剪:使用另一个LLM来判断哪些信息是“可安全修剪的”。
上下文缩减是应对性能衰减和成本问题的关键,但必须在效率和信息保真度之间找到精妙的平衡。
3. 上下文检索(Retrieve Context)
核心思想:从“大海捞针”变为“按需取针”。不要预先加载所有可能用到的信息,而是建立一个庞大的外部知识库(Vector DB、文本文件等),在需要时通过检索(Retrieval)技术,精准地找到当前最相关的信息片段,动态注入上下文。这便是大名鼎鼎的RAG(Retrieval-Augmented Generation)模式的精髓。
具体实践:
混合检索与重排(Re-ranking):单一的检索方法(如纯向量搜索)往往不够鲁棒。业界领先的实践是采用混合检索。例如,结合使用基于关键字的稀疏检索(如BM25)和基于语义的密集检索(向量搜索),然后将两者的结果合并。更关键的是下一步——重排。使用一个专门的、轻量的重排模型(Cross-encoder)对检索出的文档片段进行重新排序,确保最最相关的片段排在最前面,然后才将Top-K的结果注入上下文。这直接缓解了“迷失在中间”的问题。Windsurf的Varun的分享中就强调了这种多阶段检索流程的重大性。
智能提示词组装系统:高级的RAG不仅仅是“检索-拼接-提问”。像Cursor中的Preempt系统,它是一个复杂的提示词组装引擎。当用户提出一个关于代码库的问题时,Preempt会智能地决定需要检索哪些信息:相关的代码文件、Git历史、相关的文档、甚至是团队成员之前的讨论记录。然后,它会把这些异构信息用一种结构化的方式(例如,用Markdown标签清晰地标记每个信息来源)组装进最终的提示词中,极大地提升了模型回答的准确性和深度。
基于描述的工具检索:这是解决“上下文混淆”的利器。与其将200个工具的完整定义全部放入上下文,不如将它们的描述存储在一个向量数据库中。当需要使用工具时,先将用户的意图(或模型的中间思考)作为查询,去检索出最相关的Top 5-10个工具,然后只将这几个候选工具的详细定义注入上下文,供模型进行最终选择和调用。这种“两阶段”的方法,极大地降低了模型的认知负担。
上下文检索是扩展AI知识边界、同时保持上下文简洁高效的核心技术,是现代AI Agent的基石。
4. 上下文隔离(Isolate Context)
核心思想:分而治之。将一个庞大、单一的上下文,拆分到多个协同工作的、拥有各自独立且小得多的上下文的Agent中。
Context Engineering Meetup:
https://docs.google.com/presentation/d/16aaXLu40GugY-kOpqDU4e-S0hD1FmHcNyF0rRRnb1OU/edit?slide=id.g370b68d7aca_0_166&pli=1#slide=id.g370b68d7aca_0_166
具体实践:
多Agent架构:这是最典型的隔离策略。与其让一个“全能”Agent处理所有事情,不如设计一个“总监Agent”(Manager Agent)和多个“专家Agent”(Specialist Agents)。例如,一个软件开发任务可以被分解为:
总监Agent:负责理解总体需求,制定计划,并将任务分发给专家。它的上下文主要包含高级计划和各专家的进度报告。
文件系统Agent:专门负责读写文件,其上下文只包含文件路径和操作指令。
编码Agent:接收具体的编码任务,其上下文主要包含相关的代码片段和任务描述。
测试Agent:接收代码和测试要求,其上下文只包含待测代码和测试用例。
Anthropic的多Agent研究就展示了这种架构的巨大潜力。通过将上下文隔离在各个专家内部,每个Agent都能更专注、更高效地工作。
重大警示:警惕决策冲突! 正如Cognition的Walden Yan所指出的,天真的多Agent系统会引入新的问题,尤其是“上下文冲突”的加剧版。如果各个Agent之间缺乏有效的协调机制,它们可能会做出相互矛盾的决策。列如,编码Agent和测试Agent可能基于各自隔离的上下文,对同一个Bug产生了不同的理解,从而进行无效的修改和测试。
缓解策略:
建立层级结构,限制子Agent的决策权:open-deep-research的实践表明,一个更稳健的模式是,让子Agent(Sub-agents)更多地扮演“强化版工具”的角色,而不是完全自主的决策者。它们负责执行具体的、定义明确的任务,但不做高层级的战略决策。所有重大决策都由“总监Agent”基于从各子Agent汇总上来的信息统一做出。这样既享受了上下文隔离带来的效率提升,又避免了决策混乱的风险。
5. 上下文缓存(Cache Context)
核心思想:对于上下文中不变或变化缓慢的部分,进行缓存,以降低成本和延迟。
具体实践:
利用模型提供商的缓存机制:这是一个巨大的成本优化点。以Claude-Sonnet为例,其API对输入Token和输出Token的收费不同,且对缓存的输入Token有大幅度折扣(可能高达10倍)。这意味着,如果你的上下文大部分是重复的,那么后续调用的成本将大大降低。
前缀缓存(Prefix Caching):这是最常见的缓存策略。我们可以将一个典型的Agent上下文划分为两部分:
不可变前缀(Immutable Prefix):这部分内容在一次会话中基本不变,包括系统提示(System Prompt)、Agent的角色扮演指令、所有可用工具的详细描述等。这部分可以被预先处理和缓存。
可变后缀(Mutable Suffix):这部分是每次交互都会变化的内容,包括用户的最新消息、最近的对话历史、最新的观察结果等。
在每次调用API时,我们只需要发送可变后缀,并告知API使用哪个缓存好的前缀即可。这不仅能极大地降低Token成本,还能显著减少模型的处理延迟,由于模型无需每次都重新解析那个庞大的前缀。
上下文缓存,尤其是前缀缓存,是实现低成本、高响应速度Agent的关键工程技巧。
第三部分:综合与展望——构建一个上下文工程化的AI系统
以上五大策略——卸载、缩减、检索、隔离、缓存——并非相互排斥,而是一个现代AI Agent系统设计中相辅相成的组合拳。一个理想的、经过上下文工程优化的系统架构可能如下所示:
输入处理层:当用户请求到达时,第一进入检索模块(Retrieve)。该模块通过混合检索与重排,从外部知识库(代码、文档、历史对话)中获取最相关的信息。同时,工具检索器也在此阶段筛选出最可能用到的几个工具。
核心编排层:总监Agent接收用户请求和检索到的信息。它利用上下文卸载(Offload) 技术,读取并更新存储在文件系统中的长期计划(todo.md)和记忆(memory.json)。
执行层:总监Agent将具体的、原子化的任务分发给专家Agent(Isolate)。每个专家Agent都在一个被隔离的、小得多的上下文中工作。例如,编码Agent只接收到需要修改的函数和相关上下文。
记忆与历史管理层:在Agent的整个生命周期中,一个上下文缩减(Reduce) 模块持续在后台工作,它智能地总结和修剪对话历史与工具输出,确保工作上下文始终保持精简。
性能优化层:在与LLM API交互的最底层,上下文缓存(Cache) 机制被激活。系统将长而不变的系统提示和工具定义作为前缀进行缓存,极大地降低了每次调用的成本和延迟。
通过这样一套组合框架,我们就有可能在享受百万级Token带来的广阔知识视野的同时,有效规避长上下文的五大诅咒。
结论:未来属于“精雕细琢”的上下文
我们的到来。我们正处在一个关键的转折点,从对原始模型能力的惊叹,转向对如何系统性地驾驭这种能力的深入探索。百万级Token的上下文窗口为我们提供了一片广袤的画布,但若没有“上下文工程”这支精细的画笔,我们画出的可能只是一片混沌的色彩,而非一幅清晰的蓝图。
将上下文视为一个需要设计的系统,而不是一个被动填充的容器——这正是上下文工程带给我们的核心思想转变。它要求我们从过去的“数据投喂者”和“提示词工程师”,进一步升级为“AI认知建筑师”。我们的任务,是为模型构建一个干净、有序、高效的认知工作空间,让它能够在其中清晰地思考,而不是在信息的海洋中溺水。
这一转变对整个生态系统提出了新的要求。对于AI应用开发者而言,上下文工程将成为一项与模型选择、提示词设计、微调同等重大的核心能力。未来,我们评估一个AI Agent的优劣,不仅要看其底层模型的强劲与否,更要看其上下文管理策略的精妙程度。
对于模型提供商而言,竞赛的终点线不应仅仅是上下文窗口数字的攀比。更重大的是提供原生支持上下文工程的工具与API。我们期待看到更智能的缓存机制、更低成本的状态管理API、以及在模型层面就得到优化的注意力分布,能够从根本上缓解“迷失在中间”等问题。模型本身,也需要进化得更能“理解”上下文的结构,而不只是将其视为一串扁平的Token序列。
最终,上下文工程是我们通往真正健壮、可靠的自主AI Agent的必经之路。它是在长任务链条中维持AI“理智”和“专注”的缰绳。只有通过精心的卸载、缩减、检索、隔离与缓存,我们才能构建出那些不仅能在演示中惊艳众人,更能深入生产环境,日复一日地、稳定地执行复杂任务的AI系统。
从更宏大的视角看,上下文工程深刻地定义了未来人机协作的形态。它不只是技术,更是一种沟通的艺术。我们通过构建上下文,来引导AI的注意力,塑造其推理路径,弥补其天然的认知缺陷。这是一种更深层次的合作——我们不只是下达指令,更是为其思维过程提供脚手架。未来,最强劲的AI应用,必将誕生于那些最懂得如何与AI一起“思考”,并为其“精雕细琢”上下文的创造者手中。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:
https://blog.csdn.net/universsky2015/article/details/153872137
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










