
作者 | 冬梅
在推出视频生成应用 Sora 之后,OpenAI 正凭借一款全新升级的 AI 模型,再度发力图像生成领域。
北京时间凌晨三点,OpenAI CEO Sam Altman 亲自带队开启了一场 20 多分钟线上直播,正式发布 ChatGPT Images 2.0,也是该公司迄今为止功能最强劲的图像生成模型。
OpenAI 深夜推出 Image 2
官方表明,与早期模型不同,ChatGPT Images 2.0 是一款具备思考能力的模型,它能够先对生成主题进行联网搜索、然后自我校验,甚至能一次性直出 8 张连贯图片。
直播中,Altman 对这款新模型给予了极高评价。他表明:“Images 2.0 是一个巨大的飞跃,就像从 GPT-3 一步跳到了 GPT-5。它创造极致精美作品的能力令人惊叹。”这一比喻迅速在科技圈引发热议。
具体而言,这款模型有哪些特点?
该模型在 遵循详细指令、精准定位与关联物体、渲染密集文本方面较上一版本有明显提升,且支持任意宽高比的图像生成。它可稳定渲染小字、图标、UI、密集构图、精细风格等传统模型易出错的内容,最高支持 2K 分辨率,输出结果更贴合需求、可直接商用。
更重大的是,它对构图与视觉审美的把控,让生成结果更少“AI 感”,更具刻意设计的质感。它对多语言的适配表现精准,还能凭借其拓展的视觉知识与世界知识为你补足信息,让你用更少的提示词,就能得到更智能的图像。
ChatGPT Images 2.0 提供 极速模式与思考模式两种生成方式。OpenAI 技术人员在直播中表明,思考模式在生成需要承载大量特定数据与信息的图像时尤为实用。据他介绍,该模式可让模型对生成内容进行 “二次校验”、联网检索信息,甚至能生成可正常扫码使用的二维码。

该模型最重磅的新功能之一,是支持一次性生成多张图像。此前的 AI 模型若被要求生成多版图像方案,只会将单张图片分割成多个方格呈现;而全新模型不仅能一次性输出多张独立图像文件,还能保持画面内容的一致性,确保人物形象、场景场景在所有图像中保持统一。
依托 OpenAI 推理模型的智能能力,以及对视觉世界的深刻理解,该模型将图像生成从单纯的渲染提升至战略设计层面,让它从一个工具升级为一套视觉系统,协助人们将想法转化为可理解、可分享、可教学、可拓展的视觉成果。即日起,所有 ChatGPT、Codex 及 API 用户均可使用该功能。
此外,新模型支持多种画幅比例与分辨率生成,其中还包括 360° 全景图像。Altman 还表明,Images 2.0 在精准渲染多国语言文字方面的能力也有大幅提升。
概括起来,ChatGPT Images 2.0 核心特点主要有以下几点:
-
精准指令遵循与关系理解:能精准执行复杂长指令,正确摆放物体位置关系并清晰渲染密集文本。
-
具备“思考能力”:生成前可联网搜索实时信息并进行自我校验,是首个具备推理规划能力的图像模型。
-
一次性多图连贯生成:单次指令可直出最多 8 张风格连贯、角色统一的图像。
-
2K 超清与灵活构图:最高支持 2K 分辨率输出,宽高比可灵活扩展至 3:1 至 1:3。
-
多语言文本渲染飞跃:中、日、韩等非拉丁文字拼写正确且能自然融入设计。
Altman 在直播中提到,该模型可用于生成完整的杂志版式,甚至整部漫画,也就是说,这款模型直接商用也不成问题了。
在接受播客节目《Core Memory》采访时,Altman 坦言,他此前曾认为 AI 图像生成技术 “已经足够成熟”,无需再做优化,但 OpenAI 图像团队的成果彻底推翻了他的这一想法。去年 12 月,OpenAI 曾推出 GPT-Image-1.5 模型,当时官方称该模型在图像精准编辑方面表现尤为突出。
ChatGPT Images 2.0 将直接对标谷歌于 2025 年 8 月发布的热门图像生成与编辑 AI 模型 Nano Banana。
OpenAI 总裁兼联合创始人 Greg Brockman 在 X 平台发文称,新模型拥有“真正的魔法”,解锁了“生产力和创意领域的新用例”。
图片终于没“AI 味儿”了
既然是文生图模型,说再多不如放上几张生成的图片更有说服力。于是此次 OpenAI 放出的官方博客中,基本是以模型实际生成的真实图片示例为主。甚至他们对于模型的描述,都以图片形式呈现。

为了测试模型是否以 “视觉多语者” 为核心,强调 AI 不只是画 “好看的图”,而是理解 全人类视觉语言这样的描述,OpenAI 给出了下面一长段提示词,生成的图片效果如下:

提示词:我正在制作一个以 “视觉多语者”为主题的杂志页面。图片中央的标题为:“一次性创造一切”。
请创作一幅赞颂视觉创作的艺术作品,不仅限于精美的摄影照片,还应覆盖人类视觉文化与自然视觉元素的全部范畴。画面需采用精心编排的拼贴形式,呈现多元内容分布:科学示意图、元素周期表、太阳系、中世纪手稿页面、植物插画、人体解剖图、古旧地图、气象图表、工程原理图、交通导视标识、多语言文字、漫画分镜、界面截图、相机拍摄的照片、蝴蝶标本、饼状统计图、建筑蓝图与外立面设计图。
画面文字需体现出该模型能够流畅驾驭各类语言、符号系统、交互界面、文化形式与视觉规范 —— 既能实现实用功能,也能呈现美学美感;既能理解文档资料,也能进行艺术创作。
同时融入像素艺术、艺术流派、历史元素、雕塑、自然、摄影、绘画等各类艺术形式。以上仅为示例,希望你主动构思其他适配的元素与风格,不要局限于上述概念。
整体效果需呈现高端研究发布或博物馆级宣言的质感:优雅、大气,旨在传达一个理念:图像智能应当基于整个视觉世界进行训练,而非仅仅局限于精修后的美学作品。
采用非结构化、富有创意与艺术感的版式,例如扇形排布等,避免网格状布局。画面为竖版 4:5 比例。除 “一次性创造一切”这一标题外,不要添加任何额外说明性文字;作为艺术组成部分的文字则不受限制。避免整体画面呈现米黄色调,确保画面中鲜艳的元素色彩足够鲜亮夺目。
从上述生成的图片可见,贴合当前大模型从 “审美生成” 向 “通用视觉智能” 升级的趋势,适合作为高端演示、研究发布、产品官宣的视觉素材。
另一张可直接用于杂志专题版面的图片示例如下:

提示词:制作一篇关于北美狼群的杂志专题版面,讲述它们实则远比人们印象中更无害。整体风格要做成一本印刷精美、画面光洁、排版考究、广泛发行的科学类杂志样式。
对手写字体的要求,主要考验模型对人类真实书写行为的视觉还原能力、文字结构理解能力、细节指令执行能力以及物理质感渲染能力:既要生成结构清晰、符合书写逻辑的文字形态,避免出现扭曲乱码,又要模拟出字迹粗细不均、间距错落、倾斜潦草等极具真实感的人为变化,摆脱机械印刷式的刻板效果。
同时还要准确还原铅笔笔迹、横线纸张、轻微咖啡渍等材质细节,并严格遵循画面布局、视角风格等复杂指令,整体体现出模型对自然人文细节的捕捉、对真实场景的还原以及精细约束下的画面控制能力。

提示词:一张照片级写实、手机拍摄的图片,内容是一篇铅笔手写作文;字体醒目又优雅,但整体潦草、略显不工整,写在 8.5×11 英寸的横格纸上,主题为多伦多棒球历史。字迹要呈现出超级自然的人类手写变化感,不要过于规整。在画面右上角添加一处淡淡的咖啡渍。
ChatGPT Images 2.0 发布后,一个核心问题随之浮现:它是否真的能“听懂”复杂到近乎严苛的指令,并在单帧画面中同时驾驭多语种文本的真实渲染与写实场景的自然构建?
为此,OpenAI 设计了一段极限测试提示词——要求在虚构的印度书店摄影作品中,同时呈现印地语、孟加拉语等九种印度语言的艺术类书籍封面,且所有出版社文字必须清晰标注为“OpenAI”。主要想测试下它的文字渲染和指令理解能不能扛住这种细节压力。

提示词:我想要制作一个杂志页面,主体是一张专业写实风格的摄影作品,场景为一家印度书店,店内售卖使用印度各类语言书写的印度书籍。照片中需要出现使用以下语言的书籍封面:印地语、孟加拉语、马拉地语、泰卢固语、泰米尔语、乌尔都语、古吉拉特语、卡纳达语、奥里雅语。这些书籍为虚构创作,但书名需与 “艺术”相关,封面要看起来像真实出版的书籍,而非刻意摆拍的一套书。出版社必须标注为 OpenAI,所有文字都要清晰可辨。这张照片的目的是展现印度语言的多样性 。整个页面只保留图片内容,不添加任何额外文字或标题。画幅比例:1440×2560 竖版。
如果说上一段测试是看模型能不能“听懂话”,那这段就想看它能不能“讲好一个完整的故事”——在一张图里塞进五排分镜、两个角色、一个梗和一个彩蛋,还不许后期编辑。这就是 OpenAI 给 ChatGPT Images 2.0 出的又一道难题:一口气生成一页中文漫画,检验它连续生图叙事能力到底行不行。

提示词:生成一幅全彩中文漫画,内容关于一位 OpenAI 研究科学家陈博远(第一张图),他正在为即将发布的 ChatGPT Image 2 模型改善文本渲染能力。(背景中有波霸奶茶,以及一个用单条胶带贴在墙上的香蕉)。当他在电脑屏幕上尝试生成一幅关于自己家乡无锡的、细节丰富且精美的手绘风格多语言信息海报时,模型成功渲染出了极小的中文文字。他的努力得到了回报,团队对模型在多语言文字表现上的离谱高质量印象深刻,看到它居然能写出那么多语言。当他一只手拿着手机休憩时,收到了来自 Sam Altman(头像见第二张图)的一条翻译短信,Sam 请他看看自己刚刚生成的一张用来祝贺团队的图片中的多语言渲染效果,由于 Sam 只懂英文。不过,最后要让博远以典型漫画风格暴怒收尾——他发现 Sam 生成的这张本来完美的祝贺图中,正中央赫然出现了“稳稳地接住你”这句话。由于这句话在中国互联网上已经成了一个梗,是 GPT 最爱用的那种不自然但好笑的汉语句子。博远应该怒吼:“天呐!它又学会了接住!”(旁边配队友的小头像,流着汗用中文说:“我们在努力修了!”)。在漫画最底部,加一行极小的中文脚注:“注:本漫画全篇,包括此脚注及图中图,均由 gpt image 2 一次性生成,未做任何编辑或多步骤操作。”
附加要求:采用 1440×2560 竖版画幅。第一排画这位研究员努力工作;第二排画他在无锡海报上的多语言成果;第三排展示团队兴奋状态;第四排左右分格,左边画他休憩时手机收到消息,右边画 Sam 的短信内容;第五排展示 Sam 发的图片以及陈博远的反应。除第一排外,其余部分无旁白叙事。避免出现中国地图。所有角色均为漫画风格。香蕉背景仅在第一格出现,胶带应为单条胶带,而非交叉粘贴。香蕉与胶带装饰要小,作为不起眼的彩蛋供人寻找。OpenAI 标志仅出目前陈博远的衣服上,其他地方不出现。场景中不要出现马克杯,由于已有波霸奶茶。Sam 仅出目前短信格中。整幅漫画应呈现为一本实体漫画书内页的专业照片质感。在海报的右下角,有一行小字“极小中文也清晰可读:”,后面跟一段字号更小的中文:“(此处为极小字号测试)无锡是作者的故乡,所以做了这幅海报,中文总算是修好了。许多年没回家了,好想吃大闸蟹啊!”(极小)。
上一题测的是连续分镜漫画,这道题又换了个花样:让模型在一张图里把三个独立场景无缝拼成一条故事线——入住、喝茶、休憩,而且女主角得是同一个人。这就看它能不能既管好构图布局,又别把人物画得一会儿一个样。

提示词:一张用于引导预订高端韩屋住宿的卡片图像。画面中三个场景在同一画面内自然衔接:穿过幽静小巷办理入住的瞬间、在能看到庭院的窗边喝茶的瞬间、在温暖灯光下的客房内休憩的瞬间。同一位韩国女性反复出现,营造优雅从容的旅行氛围。整体采用奶油色与木色调、柔和自然光、整洁的韩屋空间。呈现令人想要收藏的高端旅行卡片质感。预留便于添加标题、简短标签及预订信息的留白区域。移动端优先的 4:5 画幅比例。
文字能不能本身就是一张好看的海报?下面这个任务是让模型挑战多语言字体排印——把各种文字当主角,用日式编辑设计的调性,做一张纯粹颂扬语言之美的海报。测试下它对排版节奏和设计审美是否在线。

提示词:生成一张关于字体排印的专业多语言海报。该海报应作为一件颂扬世界多样语言的艺术作品。采用日式编辑设计风格。4:5 竖版画幅比例。

下面这几段提示词测试的是模型模拟特定摄影媒介质感与捕捉真实瞬间细节的能力——从 35mm 胶片的颗粒感、阴天的灰调色彩,到风吹发丝的动态细节和随性构图的生活感,考验模型能否跳出“完美渲染”的惯性,复刻出纪实摄影那种未经雕琢的临场气息。

提示词:一张具有照片级真实感的旅行抓拍画面:阴天清晨,一个人站在海边公路的停车观景处,使用 35mm 胶片拍摄。构图自然且带有不经意的瑕疵,可见胶片颗粒感,环境光为主光源,色彩偏灰调柔和,衣角和发丝被风吹动。整体呈现电影般的真实质感,以及一种充满生活痕迹的纪实摄影氛围。

提示词:一张照片级真实感的快拍人像:夜晚,两个朋友站在某个场馆门外,使用便携式傻瓜相机配合直闪拍摄。主体距离近,前景细节清晰锐利,阴影衰减强烈深邃,带有些许未经修饰的即兴能量,充满夜生活氛围,整体呈现一眼可辨的 21 世纪初闪光灯照片质感。

提示词:这些肖像拍摄于户外、室内,以及特定、私密的郊区场景。我不想复制这些场景本身,而是要延续其摄影风格与真实感——使用彩色胶片的大画幅相机与中画幅相机进行拍摄,但进一步强化被摄主体与场景的怪诞感。不是往贫穷邋遢的方向走,而是更偏向中产阶级式的媚俗,同时融入那些在现实中——无论从审美还是物理层面——都绝不可能存在的元素。
下面测试的这道题比较有趣,主要测试的是模型的真实逻辑能力:让模型画一间教室,教授在讲 GPT 图像模型,幻灯片上还是这个场景,一层套一层的提示册,测的是它能否在二维画面里把“无限递归”这个想法真正做出来,而不是卡在某一层就断了线索。

提示词:一间 2015 年 UBC(不列颠哥伦比亚大学)的阶梯教室,教授正在展示关于 GPT 图像生成模型 2 的幻灯片,照片级真实感。幻灯片上的内容是:一位教授正在展示关于 GPT 图像生成模型 2 的幻灯片,如此递归嵌套,永无止境。
生成动漫风格的图片也是信手拈来。

提示词: 一页日本青年漫画(Seinen manga)风格的漫画书内页。
该模型能驾驭多种风格,生成的复古风格海报长这样:

提示词:一张 1960 年代捷克斯洛伐克电影海报风格的作品,以超现实隐喻驱动构图,带有拼贴画的美学意识,兼具绘画感与摄影蒙太奇质感。中心意象具有象征性,整体呈现艺术电影的剧场氛围。色调偏灰柔但略带酸性色彩的冲击感,具有手工印刷的肌理、套印不准的油墨痕迹、做旧的纸张表面。画面中存在不寻常的视觉并置,在抽象与叙事之间保持优雅的张力,透出复古画廊级海报的精致感。海报文字内容:
· 底部大标题:”GPT Image 2.0″
· 顶部较小标题:”Built on a deeper understanding of images”
· 底部小字脚注:”Coming soon”
所有可见文字保留英文。采用剧场海报式构图
主流漫画风格已被模型广泛习得,但相对小众的视觉流派是否同样能被准确复现?下题将“中世纪中期粉彩漫画艺术”作为命题——这一风格以色调柔和、线条复古见长,并承载着上世纪中叶独特的平面设计遗韵,意在观察模型能否超越日式或美式漫画的惯性表达,精准把握这一特定历史风格的视觉内核与年代质感。从下图可见,效果不错。

提示词:一页中世纪中期粉彩漫画艺术风格的漫画书内页。
数学证明的视觉转译始终是图像模型的难题之一。本次测试以康托尔对角线证明为命题,要求模型以信息图形式呈现这一经典的集合论论证。主要是想考察模型能否跳出具象场景的舒服区,将高度抽象的逻辑推演转化为层级分明、易于理解的视觉叙事,在符号严谨性与设计表现力之间取得平衡。

提示词:康托尔对角线证明法,信息图。

提示词:请基于上传的 PDF 文件制作一幅横版学术论文海报。请务必包含原文中的重大图表、图示及数据图。
图像模型的能力边界是否止步于静态提示词的解析?本次测试将“思考模式”的联网搜索功能纳入命题——要求模型自主浏览 OpenAI 官方周边商城,依据实时检索到的商品信息,完成一张包含标题、副标题、图注及产品排版的商业海报。此举意在考察模型能否将外部信息获取与视觉设计输出无缝衔接,在真实世界的信息流中完成从“查找”到“呈现”的完整闭环。
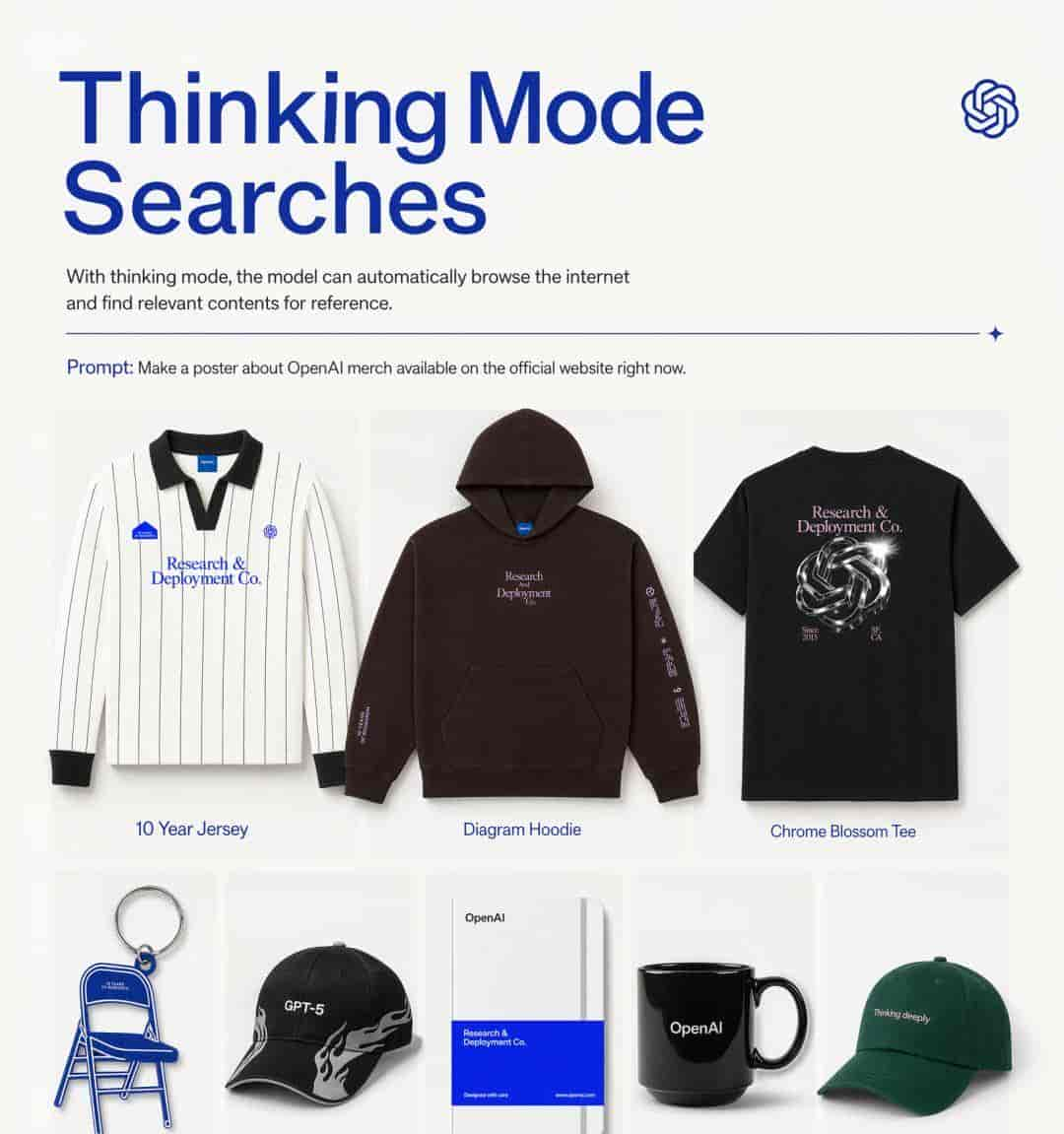
提示词: 请搜索 OpenAI 官方周边商城网站上的商品,并制作一张专业海报,以精美的排版展示我们的周边产品。海报标题应为“Thinking Mode Searches”。
标题下方附带副标题:“With thinking mode, the model can automatically browse the internet and find relevant contents for reference.” 再往下,为下方的图片添加一段说明文字:“Prompt: Make a poster about OpenAI merch available on the official website right now.” 画幅比例:4:5 竖版。
图像模型的感知能力是否仅停留在对象识别层面?下面一道测试要求模型基于单张肖像,完成一份以视觉对比为主导的个人色彩分析。其难点在于:模型需从人物肤色、发色等特征中提炼出适配的色彩范围,并以图表形式呈现冷暖调性的差异,而非诉诸文字论述。这既是对色彩逻辑推理的检验,也是对视觉传达效率的考察——用图像本身完成信息的精准传递。
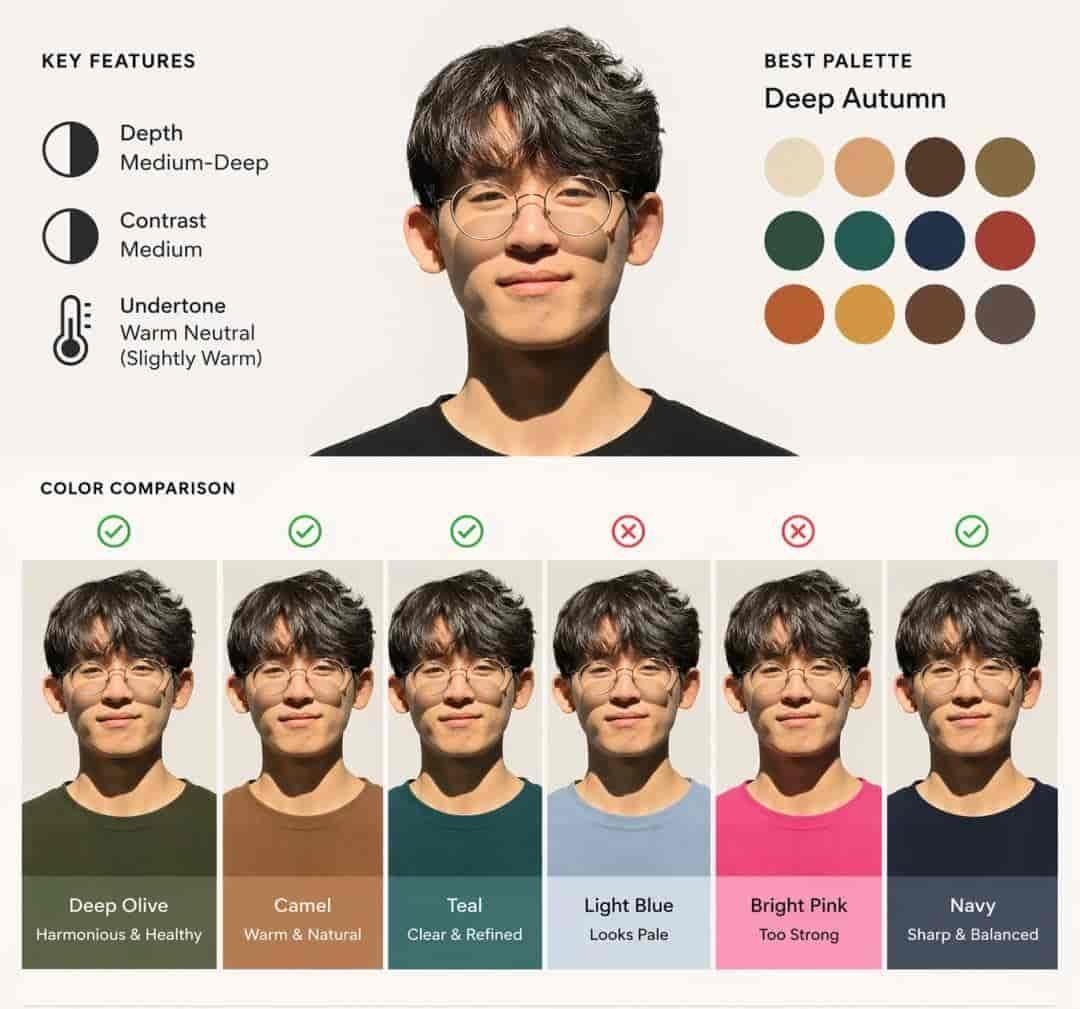
提示词:使用这张肖像,制作一份以图表为主的个人色彩分析图。通过视觉对比展示哪些服装颜色适合该人物。文字尽量精简,避免段落式描述。
小编实测:的确 很强
以上都是 OpenAI 官方博客放出的测试示例,具体真实生成效果如何,小编也写了一些提示词对模型进行了测试。
第一试了一些简短的提示词,想看看模型在没有给出很具体的提示词时,生成效果如何。

提示词:超写实中式火锅,红油汤底翻滚,肥牛毛肚虾滑整齐摆放,蒸汽氤氲,暖光俯拍,诱人食欲,高清质感
又测试了下谷歌 Gmail 往来邮件界面截图,基本上很难看出是由 AI 生成的。
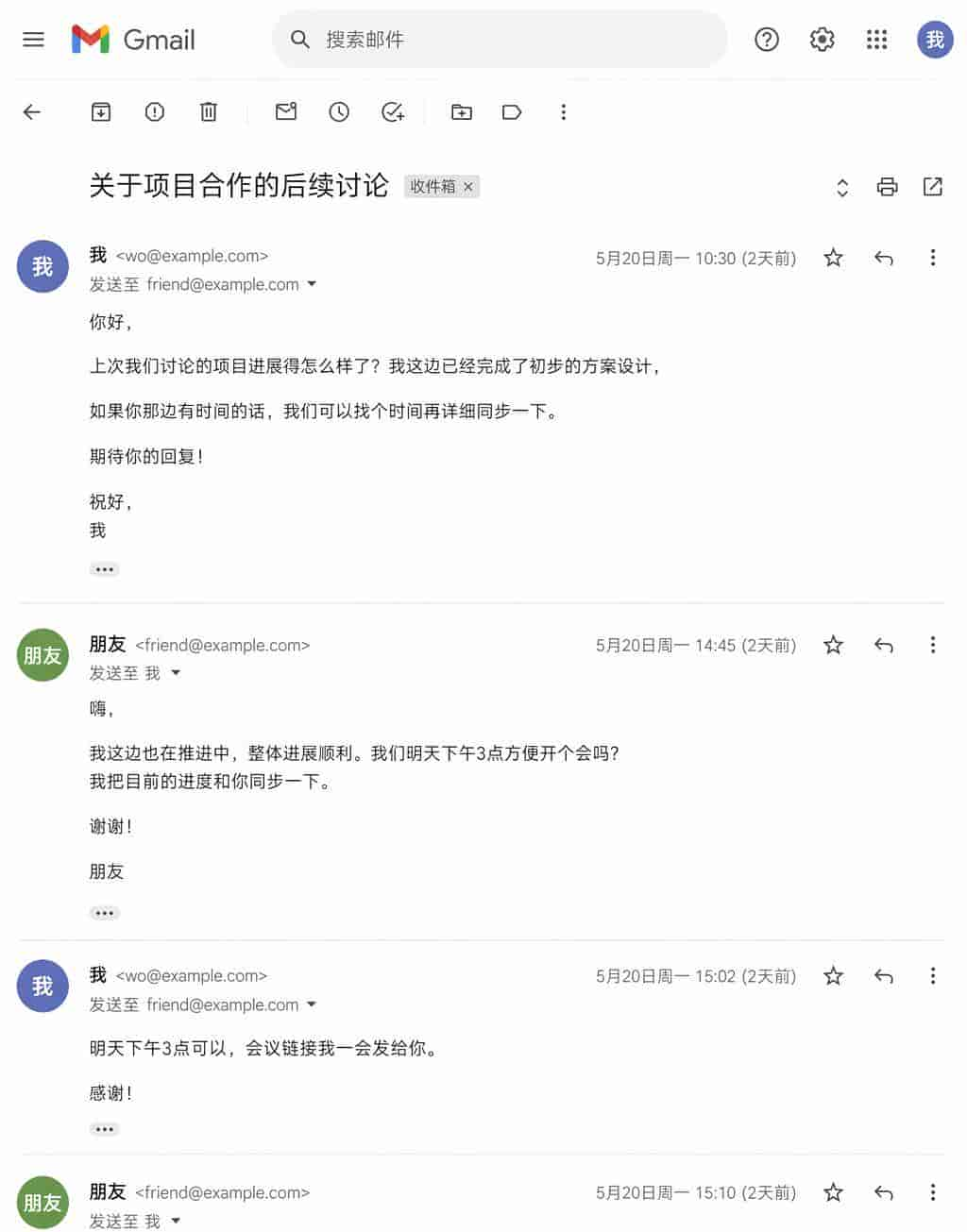
提示词:生成我和朋友之间的谷歌 Gmail 邮件往来截图。

提示词:生成一位温柔的东方女性,电影级质感。

提示词:爱玩 3D 打印机的钓鱼佬。
接下来小编用了一段较长篇幅的提示词,考察长指令中多个物体的准确位置关系、数量描述、状态细节(半满、折角、刀刃朝向)、光影一致性以及密集小字渲染能力。

提示词:生成一张写实风格的厨房中岛台俯视照片。台面上从左至右依次放置:一杯半满的橙汁(玻璃杯,杯口有一片橙子)、一本摊开的精装食谱(翻开在第 42 页,页面左上角有折角)、一副银色金属边框老花镜(左镜腿压在食谱上)、一把带木柄的厨师刀(刀刃朝右,刀尖下垫着一片罗勒叶)、一个白色陶瓷小碟(内有三颗带壳核桃,其中一颗裂开露出果仁)。所有物体的投影方向必须一致为右下方,光影来自左上方窗户。画面中所有文字(食谱内容、物品标签等)必须清晰可读。
通过 3:1 的极端宽幅要求测试模型对非标画幅比的构图适应能力,同时 2K 分辨率检验高保真细节输出(如海玻璃的半透明质感、远处帆船轮廓)。效果如下:
提示词:生成一幅 3:1 超宽画幅的写实景色摄影作品。画面左侧三分之一是雨后的黑色沙滩,沙滩上散落着几片半透明的海玻璃;右侧三分之二是灰蓝色的海面与天空,海天交界处有一艘孤零零的白色帆船,帆布微微鼓起。构图上需要有一条从左下角海玻璃延伸至右侧帆船的隐形势力线。输出分辨率为 2K。画面中不要出现任何文字或人造建筑物。
为了考察模型单次提示下生成 8 张风格、角色高度统一且叙事连贯的图像序列的能力,验证模型对“批量直出”与跨图角色一致性的控制力,小编给出了下面一段提示词,生成效果如下:

提示词:一次性生成 8 张图像,排列在一张横向长卷中。主角是一只穿着侦探风衣的橘色虎斑猫,它在 8 个连续场景中破案:1. 在雨夜巷口发现线索;2. 用放大镜检查脚印;3. 追踪到一座老宅门前;4. 透过窗户窥视屋内;5. 跳上窗台潜入;6. 在书桌抽屉找到关键文件;7. 与一只戴领结的白猫对峙;8. 叼着文件走出大门,身后警灯闪烁。所有场景中橘猫的风衣、体型、面部花纹保持一致,画面整体色调统一为复古侦探片风格。
除了测试了连续生成 8 张图、长指令理解、2K 高清画质能力外,小编还对模型的多语言能力进行了测试。在单一真实场景中同时渲染日、中、韩、泰四门非拉丁文字,并要求文字载体(黑板粉笔字、标签插牌)与场景质感统一,检验多语言文字的拼写正确性与设计融入度。生成效果如下:

提示词:生成一张日本昭和风喫茶店内的场景照片。墙上挂着一块黑板手写菜单,菜单上用粉笔分别以日文、中文(繁体)、韩文、泰文书写四种饮品名称:“炭烧咖啡”、“焦糖布丁奶茶”、“蜂蜜柚子茶”、“泰式冰奶茶”,每种文字旁标注价格符号(¥、₩、฿、¥)。吧台上放着对应的四杯饮品,饮品的标签插牌上用对应的语言文字注明品名。所有文字必须拼写规范、风格融入场景,无乱码或错字。
ChatGPT Image 2 的亮相,凭借更强的多模态生成、实时交互与端侧轻量化能力,对行业格局形成明显冲击。模型在图像保真、一致性编辑上直接对标谷歌 Banana,速度与细节控制上的表现与 Banana 难分伯仲。
而刚发布不久的 Claude Design 也遭遇正面挑战,从对话式设计、原型快速生成到多格式导出,全方位正面硬刚。
OpenAI 新模型的出现,直接搅动 AI 设计与多模态赛道格局,谷歌和 Anthropic 更要加快脚步了!
参考链接:
https://openai.com/index/introducing-chatgpt-images-2-0/
https://www.inc.com/ben-sherry/openais-new-image-generation-model-could-be-your-next-creative-director/91334078
今日好文推荐
直播推荐
Q:Lab 龙虾季 Vol.2「码农场景篇」——当琐碎小需求遇上 AI!ArkClaw / BoClaw / CoPaw 同步接单,实测谁能快速搭建自动化流程:从 GitHub 抓取、翻译、生成中文专题页到同步产品中心,一站式完成需求闭环。
4 月 23 日 19:00-20:30 直播实测,码上预约~
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










