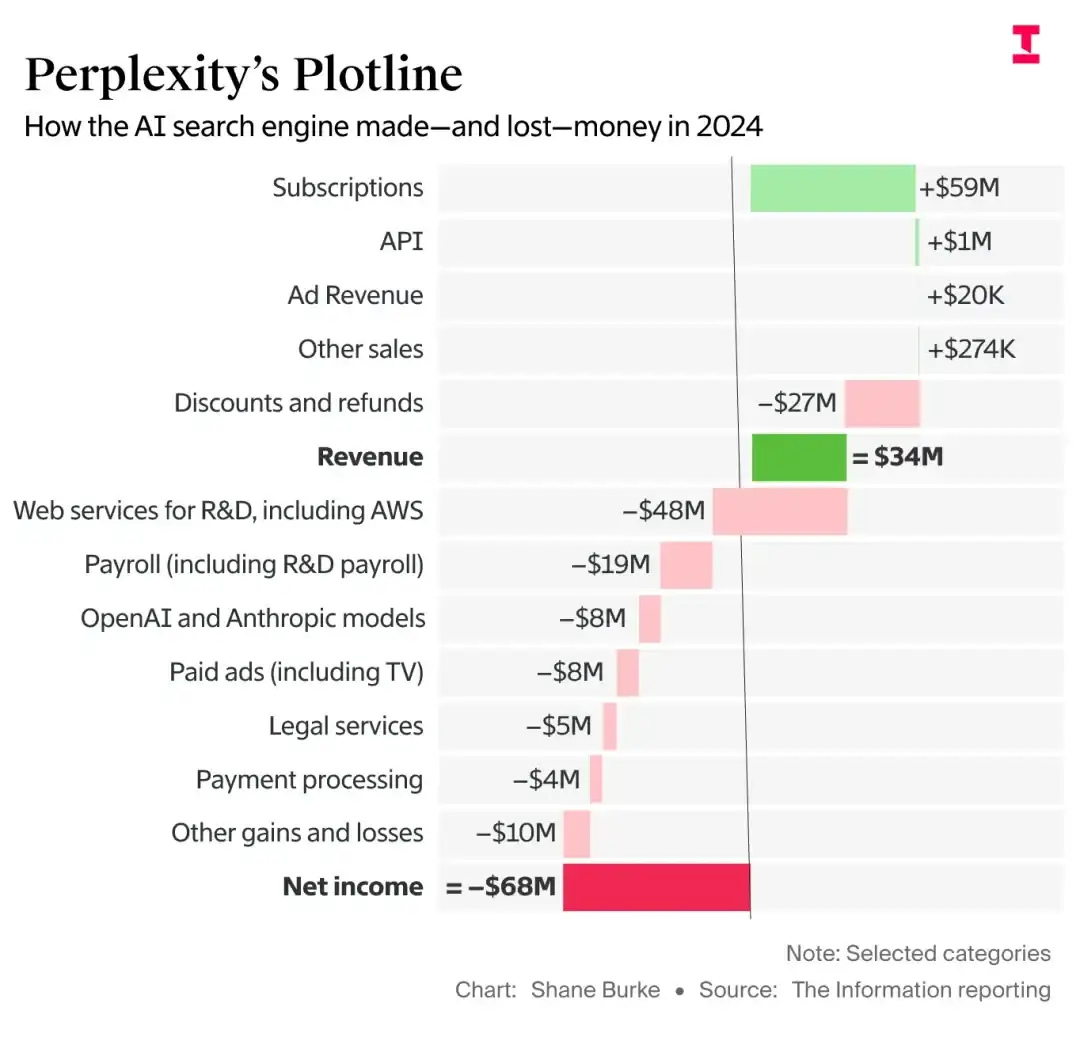
2026年2月,比利时布鲁塞尔自由大学的研究团队做了一件让数学界震惊的事:他们让一个名为ChatGPT-5.2(Thinking)的AI模型,在短短几周内,完成了一个悬而未决的数学猜想证明。

这个由数学家Ran与Teng在2024年提出的猜想,传统方法可能需要数年才能攻克,而AI与人类的协作,将其压缩到了“周”级。
这听起来像是科幻场景,但它真实发生了。更关键的问题是:为什么是ChatGPT做到了?它的竞争对手,列如Anthropic的Claude、谷歌的Gemini,为什么难以复制这种成功?
答案不在于谁更“机智”,而在于谁的设计更接近一个能独立探索未知的“研究员”,而不是一个等待指令的“解题机器”。
ChatGPT的核心优势,像一个能自己规划路线的司机
想象一下,你要去一个从没去过的地方。普通导航会告知你“左转、直行、右转”。但一个顶级的司机,不仅能看懂导航,还能在发现主路拥堵时,主动规划一条全新的小路,并最终抵达目的地。
ChatGPT在数学证明中扮演的,就是后者的角色。它的核心技术优势,是一种名为**“自主规划”** 的能力。在破解Ran与Teng猜想时,它不需要人类一步步告知它“先用这个定理,再推导那个公式”。
相反,它能自己提出多种可能的证明路径,搭建起核心的论证框架,然后通过与研究员的对话,不断迭代优化。
这个过程,被研究团队称为 “vibe-proving” 。你可以把它理解为一种高效的师徒协作:
- AI(探索者):负责在巨大的、黑暗的可能性森林里,快速点亮多个火把,找出哪条小路可能通向出口。它承担了最耗时的“探索”工作。
- 人类(导师):负责判断哪条路的方向是对的,并检查AI找到的路径是否坚固、逻辑是否严谨,补上关键的桥梁。
这种模式之所以高效,是由于它把人类从“漫无目的的苦力探索”中解放出来,专注于最擅长的“价值判断与逻辑校验”。而ChatGPT,是目前少数能担起“探索者”重任的模型。
竞品为何掉队?不是不努力,而是“设计理念”不同
那么,强劲的Claude和Gemini为什么难以复制这种成功?问题出在它们各自的技术“基因缺陷”上。
Claude的问题,是“过度谨慎”。
它就像一个配备了最严格安检的机场。多伦多大学2026年的一项测试揭示了一个关键问题:当面对一些格式特殊、表述不那么标准的数学题时,Claude Opus 4.7会直接拒绝回答其中41.7%的问题。
这不是由于它不会,而是它的安全过滤系统将这些超级规格式误判为“可疑攻击”,为了保护自己而选择了沉默。在探索全新数学证明时,思路往往是跳跃、超级规的,这种“自我保护”机制,反而成了它参与前沿探索的巨大枷锁。
Gemini的问题,是“格式依赖”。
它更像一个成绩优异的“竞赛选手”。Gemini 3.1 Pro能在国际数学奥赛中拿到金牌,解题能力一流。但它有一个隐藏弱点:对文本的呈现方式超级敏感。
同一道数学题,如果以标准的线性文本呈现,它能轻松解答;但如果把题目文字排成蛇形、栅栏密码等非标准格式,它的正确率会下降10%。这暴露了它对“标准考题”的依赖。真正的数学研究,思维是发散的,表达是随意的,这种对格式鲁棒性的不足,限制了它在非结构化探索中的发挥。
相比之下,ChatGPT-5.5在同样的“格式变换”压力测试中,正确率仅下降7%,展现了更强的适应能力。更重大的是,OpenAI似乎有意将GPT向“智能体”方向塑造——让它能自主调用工具、检查错误、持续推进任务,而不是被动响应指令。
这种设计理念,恰好与需要自主探索的数学研究完美契合。
成功无法简单复制,由于这是一套“组合优势”
所以,ChatGPT能攻克数学猜想而竞品难以复制,并非单一缘由。这是一套环环相扣的组合优势:
- 领先的自主推理引擎:在最具挑战性的FrontierMath Tier 4测试(博士后级别难题)中,GPT-5.5 Pro的得分(39.6%)接近Claude Opus 4.7(22.9%)的两倍。这证明了其在高阶推理上的绝对性能壁垒。
- 针对探索优化的“宽松度”:在保证安全的前提下,它对超级规思路和格式的容忍度更高,不会由于“看起来奇怪”就轻易拒绝,这是进行原创探索的前提。
- 与人类协作的高效范式(vibe-proving):这不是一个通用功能,而是基于其自主能力衍生出的特定使用方法,需要人类专家深度参与引导。
- OpenAI的持续专项优化:从GPT-5.2(Thinking)到GPT-5.5,OpenAI通过难题驱动训练等方式,持续强化其在数学和推理上的能力。
最终,这揭示了一个更深层的趋势:AI竞赛的下半场,胜负手不再是“参数大小”或“单项分数”,而是谁能将技术转化为解决复杂现实问题的系统能力。ChatGPT在数学证明上的突破,正是这种能力的体现——它不再是一个工具,而是一个能够与人类并肩作战、共同开疆拓土的“研究伙伴”。
对于其他竞品而言,追赶的路径已经清晰:不仅要提升考试的分数,更需要重新思考,如何设计一个敢于并善于在未知领域自主探索的“大脑”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...