就在 OpenAI 发布 GPT-5.5 后不久,国产 AI 重磅杀招 ——DeepSeek V4 预览版正式上线并开源,一口气推出 Pro 与 Flash 双版本,直接把百万 Token 超长上下文做成标配,成本腰斩式下降,综合性能碾压上代、硬刚全球顶级闭源模型。今天带大家实机测评,从长文本、代码、推理、成本四大维度,看它到底是 “吹爆” 还是 “真强”!
一、双版本齐发:百万上下文成标配,轻量化 + 高性能双兼顾
DeepSeek V4 采用 MoE 混合专家架构,推出两款定位清晰的模型,均支持 100 万 Token 超长上下文(约 75 万字),彻底告别长文档拆分痛点:
- V4-Pro(旗舰版):总参数 1.6T、激活参数 49B,对标 GPT-5.5、Claude Opus 4.6,主打顶级推理、代码与 Agent 能力。
- V4-Flash(轻量版):总参数 284B、激活参数 13B,性价比拉满,日常办公、轻量开发足够用,API 定价仅2 元 / 百万 Token 输出。

实测体验:上传整本百万字小说、百页合同或整套行业报告,无需拆分即可直接解析,总结、检索、问题分析一步到位,办公效率直接翻倍。对比主流模型 12.8 万 – 25.6 万 Token 的上下文窗口,V4 直接实现10 倍级长文本能力跃升。
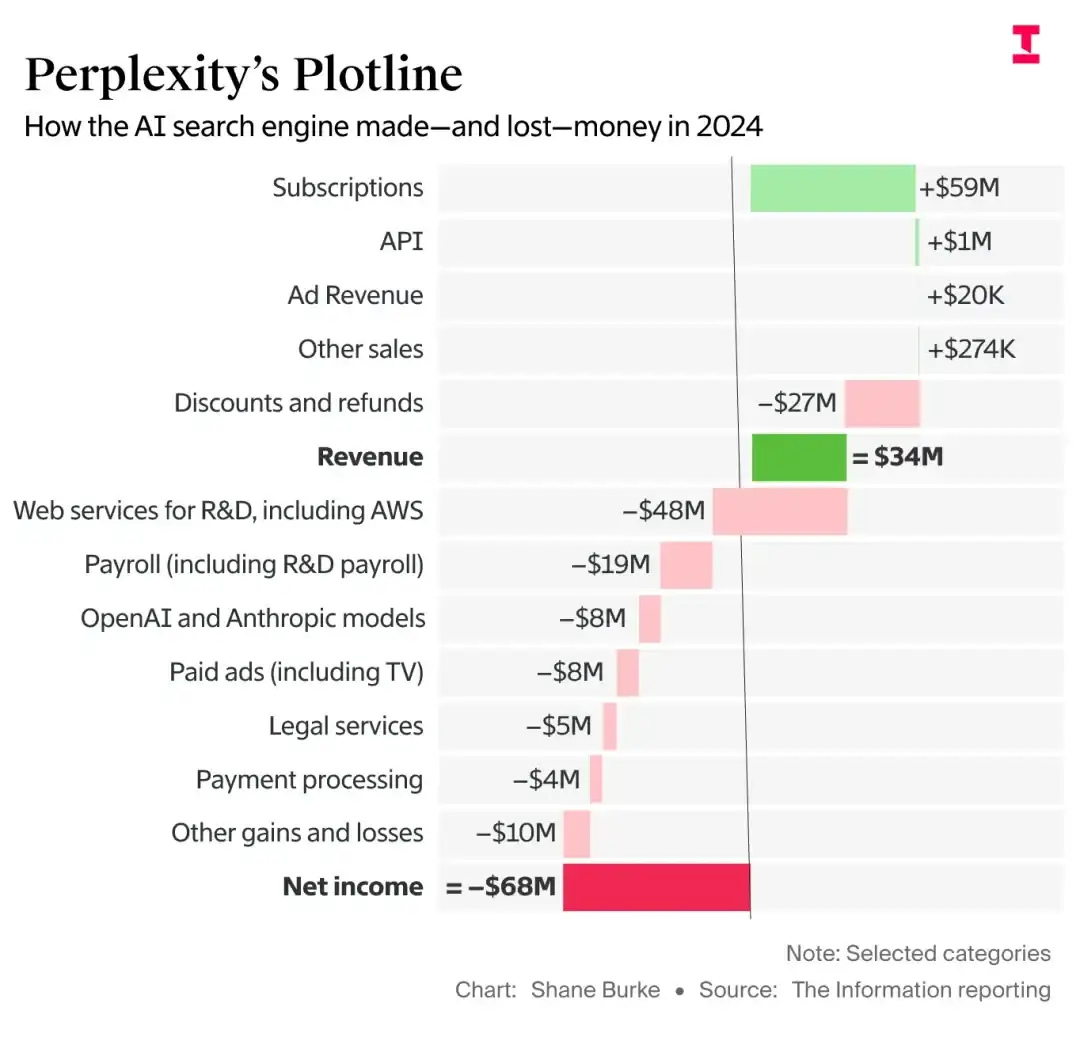
二、硬核性能实测:代码封神 + 推理拉满,开源第一实至名归
1. 代码能力:开源界天花板,碾压同级闭源模型
- SWE-Bench(真实编程任务):**83.7%** 通过率,媲美资深工程师水平,远超上代 V3.2。
- Vibe Code Bench:开源模型第一,碾压 Kimi K2.6、Gemini 3.1 Pro,较 V3.2 提升约 10 倍(V3.2 仅 5 分)。
- Codeforces Rating:3206 分,达到顶尖竞赛程序员水准。
实测场景:60 分钟连续编程任务中,V4-Pro 能自主规划 8 个核心模块 + 6 张数据表的完整数据库设计,全程无需人工干预,自我纠错与工具调用能力拉满。
2. 数学推理:竞赛级水准,IMO/STEM 双丰收
- AIME 2026:**99.4%** 正确率(接近满分)。
- IMO AnswerBench:**88.4%** 正确率,高难度数学推理稳定性突出。
- FrontierMath Tier 4:23.5% 正确率,据称比 GPT-5.2 高 11 倍。
3. Agent 能力:开源第一,复杂任务自主搞定
在真实智能体任务测评中,V4-Pro 得分1554,超越 Kimi K2.6、GLM-5.1等所有开源模型,位居榜首。从简单对话到多轮 Agent 规划、工具调用,全程自主推进,无需人工提示引导。
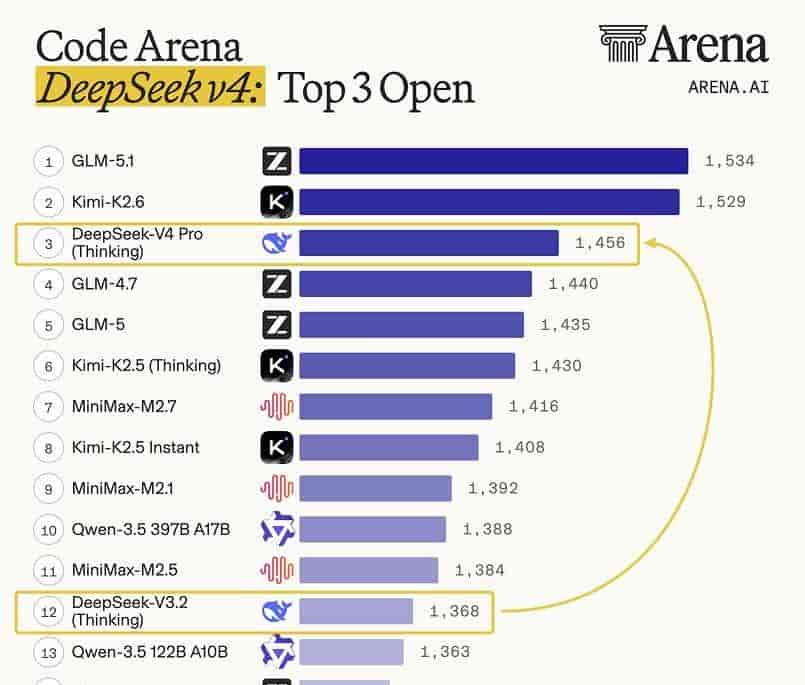
三、成本革命:单 Token 算力降 73%,KV 缓存仅上代 10%
V4 最大黑科技是混合注意力架构(CSA+HCA)+流形约束超连接(mHC),不堆算力堆效率,彻底解决长文本高耗能、高延迟痛点:
- 100 万 Token 上下文下:V4-Pro 单 Token 算力消耗仅为 V3.2 的27%(降 73%),KV 缓存占用压缩至上代10%。
- 推理模式三选一:快速响应(非思考)、中等推理(高思考)、极致深挖(极限思考),效率与精度自由切换。
实测成本:用 V4-Pro 处理百万字文档,成本仅为 V3.2 的 1/4;V4-Flash 日常调用几乎无成本压力,个人开发者、中小企业可 “无负担” 使用。
四、短板与实测翻车点:不是完美神,这些坑要注意
- 知识截止 2025 年:无法获取 2026 年最新实时信息,需搭配联网工具使用。
- 无原生视觉能力:上传图片仅提取文字,无文字图片无法处理。
- 轻量任务易 “过度思考”:Pro 版做简单问答时,偶尔因深度推理导致响应慢、甚至小错误,Flash 版更适合日常轻量场景。
- 幻觉率略升:高难度知识问答中,偶尔出现看似合理但错误的信息,需交叉验证。
五、总结:国产大模型里程碑,改写开源格局
DeepSeek V4 不是简单版本迭代,而是国产大模型的里程碑式突破:百万上下文普及、成本暴跌、性能硬刚 GPT-5.5,Agent 与代码能力坐稳开源第一。
- 普通用户:选V4-Flash,日常聊天、文案写作、长文档总结足够,性价比无敌。
- 开发者 / 企业:选V4-Pro,代码开发、复杂推理、Agent 任务直接对标顶级闭源模型,成本仅 1/4。
目前 V4 已在 DeepSeek 官网开放体验,API 同步上线,MIT 开源协议允许自由商用与二次开发。国产大模型终于在长文本、效率、成本三大核心领域实现弯道超车,未来可期!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...