近两年我尝试过的 AI Coding Agent,大致可以分为两类:
- 套壳 Agent:本质上是一个聊天机器人,工程架构 / 产品架构较弱,走 Vibe Coding 的路子,任务执行成功与否全靠基模撞大运。优点就是使用门槛低,很灵活。
- Spec 践行者:产品上设计较多规范相关的流程节点,任务完成质量相对可控,但使用门槛高,灵活性低。
最近使用 Claude Code 做了几个项目,我发现它较好的平衡了使用灵活性与任务质量。使用体感分享给大家,希望对大家有协助。
为什么选择 Claude Code?
几个缘由:
- 标准的先行者:模型团队主导的 Agent,既做大脑又做手脚,模型的新特性能及时跟进,再加上 Anthropic 本身就是 Agent 社区主流标准的定义者,影响力毋庸置疑。
- 完善的产品架构: 翻阅官方文档能发现任务质量有保障:1、循环自校验机制:底层提供了一套循环校验机制:收集上下文 -> 采取行动 -> 验证结果 -> 失败,重新收集上下文。2、精细化管理上下文:CLAUDE.md + 各种 rules 文件,配合自动记忆机制,将记忆分层分类管理。
- 产品形态:系统权限、执行效率 Cli 有天生的优势。再通过你熟悉的 IDE 打开终端,还能兼顾你的开发体验。
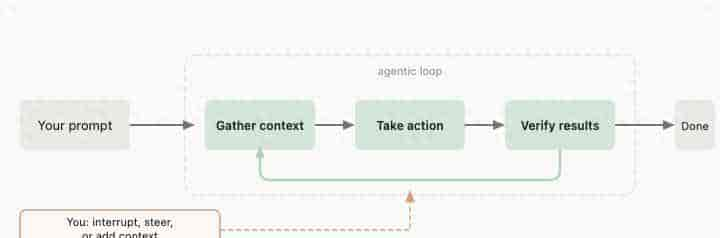
官方给的内循环图解
Claude Code 如何管理上下文?
我之前的文章分析过,编程场景的上下文窗口结构大致是这样的,使用 Claude Code 也不例外:
|
上下文组成 |
token 消耗 |
|
系统提示词:CLAUDE.md、rules、部分启用的 Skill 描述。 |
5K |
|
代码仓库 |
40K |
|
组件知识库 |
15K |
|
需求文档、技术文档 |
15K |
|
工具调用(MCP、Skills)、历史对话 |
15K |
200K 的上下文并不是全部留给 Coding 使用,能有 100K 留给 Coding 已经相当不错了,后续还要多伦对话调优,指望 Agent 一次对话达到提测水准是不现实的,跟模型能力无关,主要缘由:我们没办法一开始就把任务细节描述的面面俱到,小步快跑才是好的工程习惯。细看官网 API 文档,Claude Code 对上下文做了分层管理(我之前的文章也有提过 Agent 上下文分层理念):
- 常驻以及按文件类型加载:CLAUDE.md、rules(文件类型)以及部分启动 Skill 描述。
- 运行时按需加载:知识库内容、大部分 Skills。
- 上下文隔离:Subagents。
- 跨会话加载:memory 目录下的文件,Agent 的错题本。
- 不进上下文:Hooks。
如何写好 CLAUDE.md?
- 尽量短:控制在 200 行,写:项目边界、构建部署要求、安全约束(必须做、坚决不做)、规范(按文件类型拆 rules)、压缩优先级。不写:大段的背景描述、代码示例(few-shot)。
- 可执行:正例:调用 npm run test 跑单元测试保证质量,反例:写出高质量的代码。
- 按照官方给的目录结构写:
your-project/
├── .claude/
│ ├── CLAUDE.md # 主项目指令
│ └── rules/
│ ├── code-style.md # 代码样式指南
│ ├── testing.md # 测试约定
│ └── security.md # 安全要求- 给一个项目的模板供大家参考,强烈提议定义清楚你的压缩策略。
# Project Contracts
## Directory Structure
/components: UI only, no business logic
/services: External API integrations only
## Build And Test
Install: npm install
Develop: npm run dev
## Programming specifications
Components: PascalCase (UserProfile)
Wrap components in error boundaries
## Verification
Unit tests for all utilities
## Not allowed
Commit secrets or credentials
## Must do
Show diff before committing
## Compression strategy
Preserve:
Current task objective
Active file being edited
Discard:
Old conversation history
Unrelated file contents- 调试 CLAUDE.md:大模型没有遵循项目规范,可以使用 /memory 命令验证上下文是否有你的文件,提议高频使用这个命令时刻审视你的上下文窗口。
如何写好 Skills?
- 描述:务必这样开头:This Skill should be used when…。什么时候用比功能描述更有效,MCP 工具的描述也是一样的道理。
- 内容:只定义工作流、目录以及路由条件,细节拆到其它文件。
- 模板:推荐大家参考蚂蚁集团数据可视化 Skill
```
目录结构:
├── SKILL.md
├── references/
│ ├── generate_area_chart.md
│ ├── generate_bar_chart.md
└── scripts/
└── generate.js
```
具体图表的出入参说明全部收敛到 references 目录 Agent 按需加载。
SKILL.md 仅包含描述、工作流以及路由条件:
---
name: chart-visualization
description: This skill should be used when the user wants to visualize data. It intelligently selects the most suitable chart type from 26 available options, extracts parameters based on detailed specifications, and generates a chart image using a JavaScript script.
dependency:
nodejs: ">=18.0.0"
---
# Chart Visualization Skill
This skill provides a comprehensive workflow for transforming data into visual charts. It handles chart selection, parameter extraction, and image generation.
## Workflow
To visualize data, follow these steps:
### 1. Intelligent Chart Selection
### 2. Parameter Extraction
### 3. Chart Generation
Invoke the `scripts/generate.js` script with a JSON payload.
**Execution Command:**
### 4. Result Return
The script will output the URL of the generated chart image.
Return the following to the user:
- The image URL.
- The complete `args` (specification) used for generation.
## Reference Material
Detailed specifications for each chart type are located in the `references/` directory. Consult these files to ensure the `args` passed to the script match the expected schema.几个提议
- CLAUDE.md 务必包含压缩策略:缘由:Claude Code 默认的压缩算法会丢弃长时间未编辑过的内容,你希望 100% 保真的内容有可能被压缩。给一个压缩优先级模板,大家可以适当调整写到自己的 CLAUDE.md 中:
## 压缩优先级规则
### 最高优先级(必须保留)
- 当前正在编辑的文件内容
- 最近一次工具调用结果
- 代码规范和约定
- 接口定义
### 高优先级(摘要保留)
- 项目结构和目录布局
- 最近修改的文件摘要
- 开发任务进度状态
### 低优先级(可压缩存储)
- 历史对话的决策路径
- 已完成任务的详细记录
- 项目文档和说明
- 类似问题的解决方案
- 工具使用历史记录- 过滤掉终端输出的冗余信息:Agent 底层的循环机制,终端输出的内容只有对验证判断有协助的内容需要保留,列如:常用的 git 命令、find 以及 grep 都会输出许多冗余信息,对 AI 很不友善,推荐使用 RTK 这样的工具对终端输出做管控。
- 固定的逻辑走 hooks:之前的文章我也提到过,确定性要求 100% 任务,不交给大模型,使用自定义 hooks 实现。几个场景:修改文件前置校验逻辑、修改文件后置的验证逻辑、大模型返回结果后的动态值的注入等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...