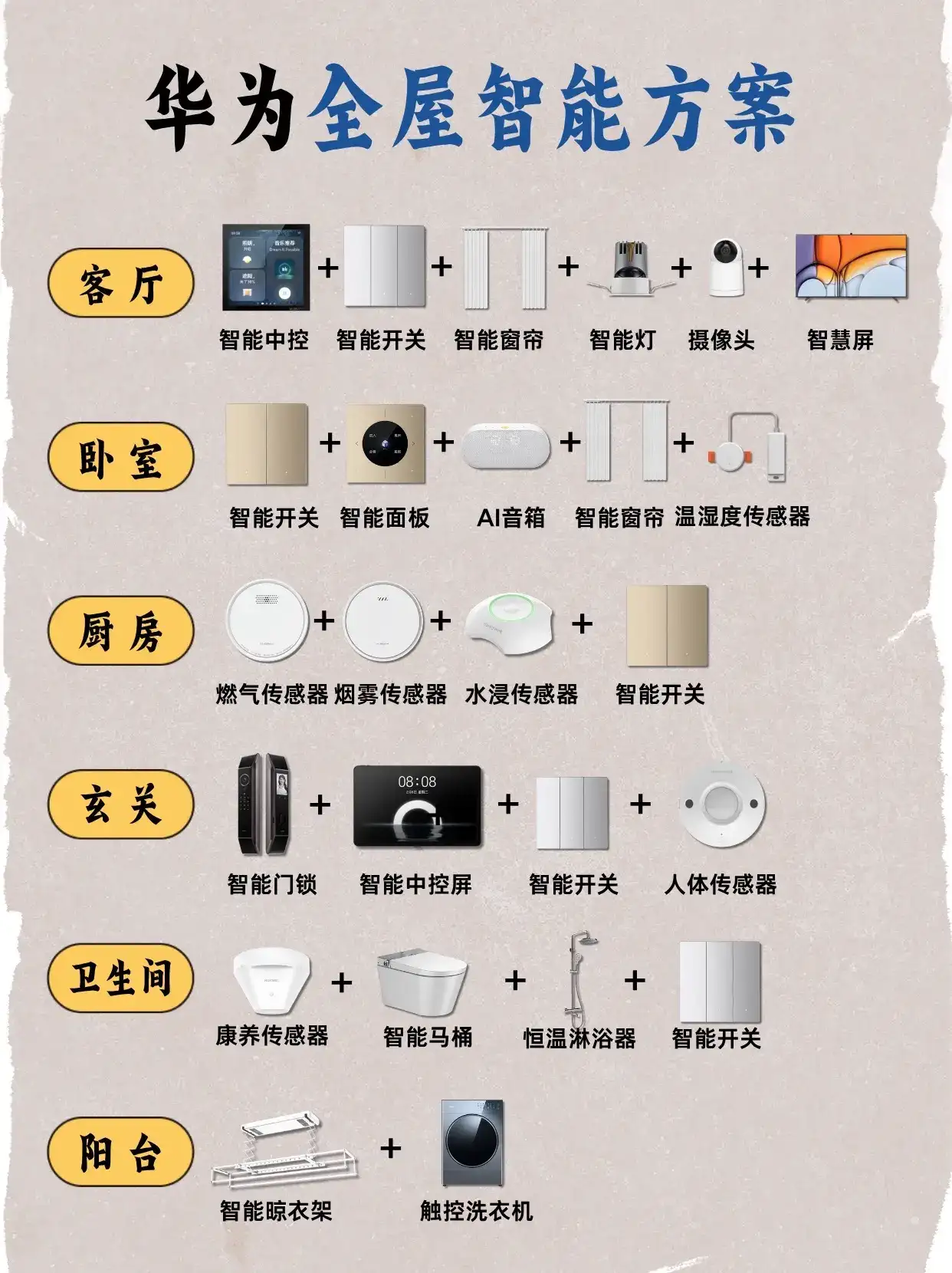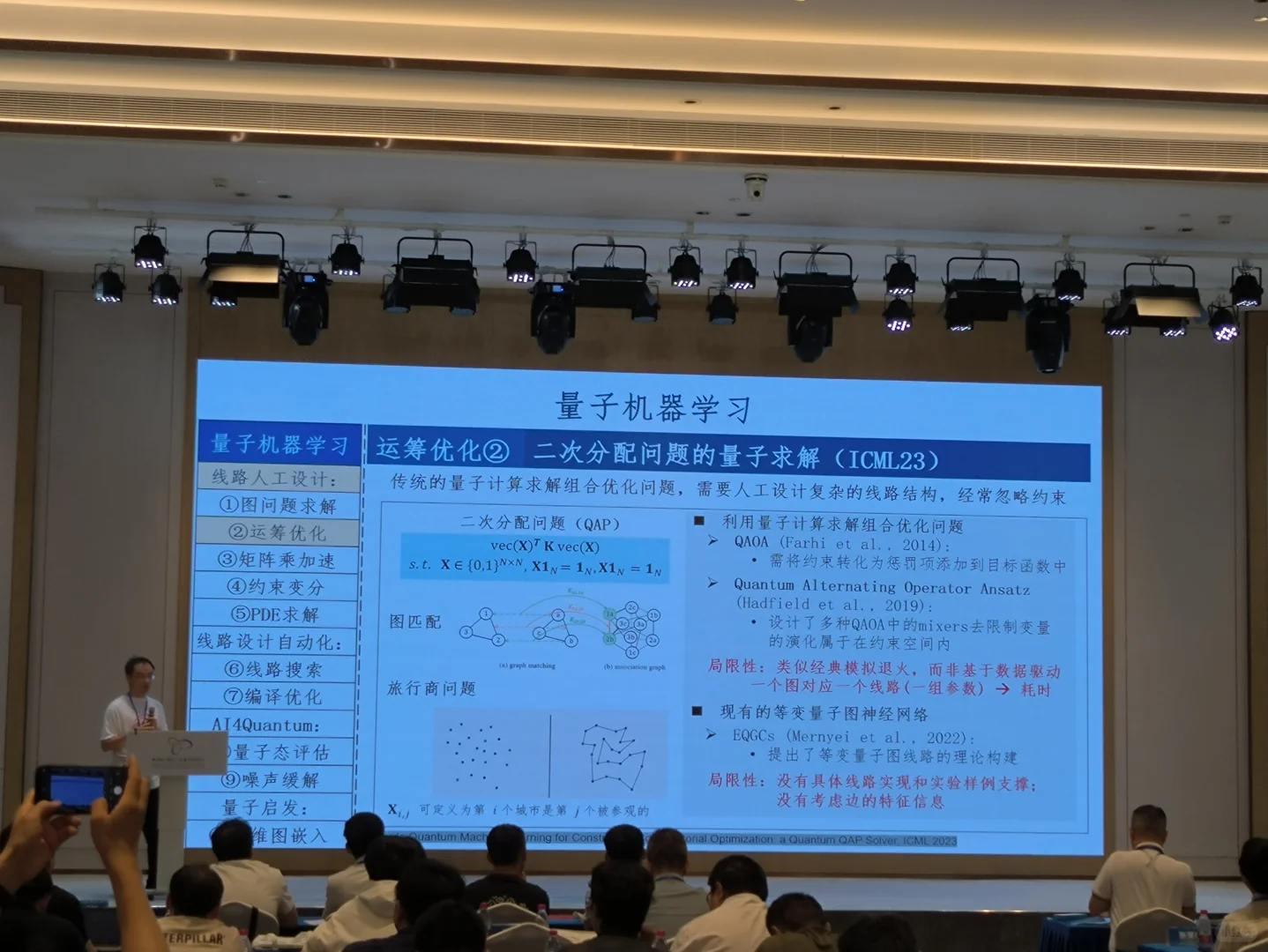
「128K的窗口已经够大了」

当朋友圈,还在炫耀自家模型能一口气吃下整本《三体》之时
MIT的实验室里,有人把1000万token的记录,直接甩给GPT,让它在5分钟内给出答案
而且准确率还翻倍了,你没听错,不是训练,不是堆卡,仅仅是把提示词变成了一段,可执行的Python代码
就好像把字典扔进微波炉,转上一圈,知识便自己冒出来了,
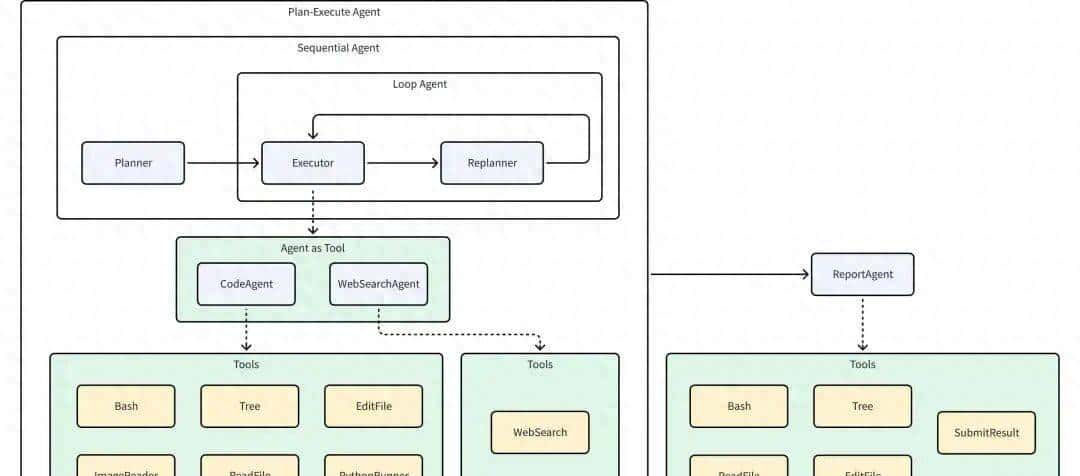
这套被叫做RLM的递归语言模型,将长文本当作变量,而非一次性喂进去的肥肉,模型就像一位深夜加班的项目经理
先grep关键词,再切片、过滤,甚至把自己叫回来做二次摘要,128K的胃并没有变大,只是学会了慢慢咀嚼,所以再长的报告,也能够吃得下。
1月3日公布的实验数据显示,同样是OOLONG长文本问答,当给GPT-5-mini套上RLM后
F1从42.1急剧上升到88.7,涨幅超过一倍,而且单条成本还下降到原来的65%
有人曾经算过这么一笔账,按照国内商用API的价格,一份30万字的招股书以往要花费24元,而目前只需8元就能搞定
节省下来的北京买,两杯外卖咖啡,还能附带一个环保标识
更令人悲伤的是,它不需要你重新进行训练,也不挑剔芯片
消费级的RTX4090,就能够运行10Mtoken的任务,而且显存占用不到9G,
上周,深圳一位券商分析师,把2025全年A股的公告全都,放进笔记本,然后出去陪客户喝喝咖啡,15分钟之后,手机弹出结果
全年净利润下滑被提及3274次,环比增长18%,他随意把截图甩进工作群,整个策略组马上就安静了
有人担心代码写错该怎么办
团队所采用的办法是,把REPL放到沙箱里面,模型只可以读取,而不能进行更改,任何越界操作都会被拦截,这就好像给好奇心安装了一个安全座椅一样
去年12月,一家头部律所进行试点,利用RLM来做尽调,发现敏感条款的漏检率从7.3%降到了0.4%,合伙人,赶紧连夜给IT部发放奖金,那数目,足够在国贸三期订一层景观位来跨年
北京地铁5号线的早高峰时段,还是拥挤得好像脚尖,都快离开地面了,在车厢里,有一个,穿着优衣库羽绒服的女孩把折叠屏手机折叠成像书本那样大小,对着麦克风说,「帮我查找一下昨晚那篇万字的医疗集采研报里,胰岛素价格下降的部分,」
没过多久,屏幕上就跳出三段高亮内容,她随手就把它复制到备忘录里了,旁边的大叔看了一眼,默默地把手里那本被荧光笔涂得都起毛了的打印稿放进,背包里面。
就在我们争论「大模型会不会让年轻人失业」的时候,它已经悄悄地把读完变成了查完,知识不再是堆放在桌子上的大山
而是悬在手指尖的电梯,按一下,就直接到达相应楼层,RLM给予的不是更长的绳子,而是一把折叠梯,收起来比手机还轻,展开却能够摸到10万米高空
窗外,2026年的第一场雪飘落在国贸三期的玻璃幕墙上,好像给城市增添了一层缓存,有人担心雪会压坏屋檐,有人已经在雪地里踩出了第一条,走向春天的脚印。
声明:本文内容95%左右为人工手写原创,少部分借助AI辅助,但是所有的内容都是本人经过严格审核和核对的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...