

ONNX准备:
我这个模块有一些特殊,ONNX不太支持动态网络,这里有两种算法,将python代码改成逻辑等效的计算方式,比如for循环单个计算需要动态计算的中间步骤;或者使用相关官方库,自定义算子,后者难度会比较大。
import numpy as np
import torch
import torch.nn.functional as F
import ctypes
import onnxruntime as ort # 新增:导入ONNX Runtime
# 注释掉的原版本有两个 ONNX 无法兼容的「动态特性」:
# 动态 groups 参数:groups=batch 中batch是运行时动态值(由输入 shape 决定),而 ONNX 是静态计算图,低版本 opset(<15)无法将groups作为动态张量参数导出,会被强制转为常量,导致推理时维度不匹配;
# 非常规 reshape 导致的维度混淆:
# x_reshaped = x.view(1, batch * in_channels, length) + weights_reshaped = weights.view(batch * out_channels, 1, kernel_size)
# 这种「合并 batch 和通道维度」的操作,ONNX 导出时容易丢失维度语义,生成的算子节点与 C++ 推理引擎不兼容;
# ONNX 支持「固定 groups=1」的卷积算子(所有 opset 版本都兼容),而groups=动态值仅高版本 opset 支持且易出问题;
# 逐样本卷积的效果 完全等价于原分组卷积(分组卷积的本质就是「按 batch 分组,每组独立卷积」),只是执行方式从 “一次性并行” 变为 “逐样本循环”,计算结果无差异;
# 循环逻辑在 ONNX 中会被导出为Loop节点(opset≥11 支持),是静态可追踪的,不会丢失维度信息。
'''
# 初始化模型+加载权重(float32)
model = DynamicConv1d(1, 1, 3, 2, 1)
model.eval() # 设置为评估模式
model.load_state_dict(torch.load('weights.pth'))
#torch.save(model.state_dict(), 'weights.pth')
INPUT_SHAPE = (1, 1, 512)
np.random.seed(42)
input_data = np.random.randn(*INPUT_SHAPE).astype(np.float32)
input_data = np.clip(input_data, -1.0, 1.0)
# PyTorch推理
x_torch = torch.tensor(input_data, dtype=torch.float32)output2 = model(x_torch)
print(output2)
import os
import torch
from torch import nn
import onnx
def transpose_onnx(model, dummy_input, model_path, save_path):
# 判断目标文件是否存在
if os.path.isfile(save_path):
print(f"The save file exists.")
return
# 将模型和变量转到CPU
# set the model to cpu
device = "cpu"
model = model.to(device)
dummy_input = dummy_input.to(device)
# set the model to inference mode
model.eval()
# 根据模型文件类型加载权重
mdl_type = model_path.split(".")
print(f"using {mdl_type[-1]} type file")
if mdl_type[-1] == "bin":
print(f"using {mdl_type[-1]} type")
checkpoint = torch.load(model_path, map_location='cpu')
model.load_state_dict(checkpoint['model_state_dict'])
elif mdl_type[-1] == "pth":
print(f"using {mdl_type[-1]} type")
checkpoint = torch.load(model_path, map_location='cpu')
if isinstance(checkpoint,nn.Module):
# if use torch.save(model, 'model.pth')) while saving model
model = checkpoint
else:
# if use torch.save(model.state_dict(), 'model.pth') while saving model
model.load_state_dict(checkpoint)
else:
print(f"using {mdl_type[-1]} type")
model = torch.load(model_path, map_location='cpu')
# 调用库函数
torch.onnx.export(model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
save_path, # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
input_names=['input'], # the model's input names
output_names=['output'], # the model's output names
dynamic_axes={'input': {0: 'batch_size'}, # variable length axes
'output': {0: 'batch_size'}})
print(" ")
print('Model has been converted to ONNX')
return
# 1、训练好的模型文件(.pth或.pt)的存放路径model_path; 即将生成的模型文件(.onnx)的存放路径save_path
model_path = 'weights.pth'
save_path = 'weights.onnx'
# 2、声明模型以及伪模型输入变量
model = DynamicConv1d(1, 1, 3, 2, 1)
dummy_input = x_torch
# 3、调用转换函数
transpose_onnx(model=model, dummy_input=dummy_input, model_path=model_path,save_path=save_path)部署流程:
🖥️ 阶段一:下载对应库
Onnx模型部署到Arm64进行推理_onnxruntime arm64-CSDN博客
已经下载了针对 ARM64 架构的 ONNX Runtime 运行时库。接下来,让我们按步骤完成这个单个模块在 ARM64 设备上的部署。整个过程可以分为以下几个阶段:
首先,请确保你已成功将目标模块(例如 DynamicConv1d)导出为独立的 .onnx 文件。具体步骤和代码示例已在上一轮回复中详细说明。请参照执行,并假设你导出的模型文件名为 weights.onnx。
🖥️ 阶段二:在ARM64设备上准备环境
传输文件:将下载的压缩包和导出的ONNX模型文件上传到你的ARM64设备(例如RK3568)。
(这一步依照你的板子有没有wifi,网线,共享网络的USB,U盘等情况传输)我的板子什么都没有,只依靠USB转TTL进行串口通信和U盘挂载传输文件,这部分看后文
# 假设使用scp,在开发机(x86)上执行:
scp /mnt/DEV2/ga/remix_eog_self_supervise/code/onnxruntime/onnxruntime-linux-aarch64-1.18.1.tgz user@<arm_device_ip>:~/
scp ./weights.onnx user@<arm_device_ip>:~/
解压运行时库:登录到你的ARM64设备,解压运行时库。
# 登录ARM64设备
ssh user@<arm_device_ip>
# 解压
tar -xzf onnxruntime-linux-aarch64-1.18.1.tgz
# 解压后,你会得到一个包含 `include` 和 `lib` 目录的文件夹,例如 `onnxruntime-linux-aarch64-1.18.1`
📝 阶段三:编写C++推理代码
在你的ARM64设备上(或在开发机上编写后传过去),创建一个 main.cpp 文件,编写一个专门用于测试你导出的单个模块的简单程序。其核心逻辑是:加载你的模块模型,准备一个随机输入张量,执行推理,并打印输出结果和形状。
#include "onnxruntime_cxx_api.h"
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <algorithm>
#include <cmath>
// 与Python中相同的随机数生成函数
std::vector<float> generate_input_data(size_t batch_size = 1) {
std::vector<float> input_data(batch_size * 1 * 512);
// 使用与Python相同的种子
std::mt19937 generator(42); // 种子42
std::uniform_real_distribution<float> distribution(-1.0f, 1.0f);
for (size_t i = 0; i < input_data.size(); i++) {
input_data[i] = distribution(generator);
}
return input_data;
}
// 检查ONNX模型的结构
void print_model_info(Ort::Session& session) {
Ort::AllocatorWithDefaultOptions allocator;
std::cout << "=== 模型信息 ===" << std::endl;
// 输入信息
size_t num_inputs = session.GetInputCount();
std::cout << "输入数量: " << num_inputs << std::endl;
for (size_t i = 0; i < num_inputs; i++) {
// ONNX Runtime 1.18.1使用新的API
Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(i, allocator);
std::string input_name = input_name_ptr.get();
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
std::vector<int64_t> input_shape = tensor_info.GetShape();
std::cout << " 输入[" << i << "]: " << input_name << std::endl;
std::cout << " 形状: [";
for (size_t j = 0; j < input_shape.size(); j++) {
if (input_shape[j] == -1) {
std::cout << "动态";
} else {
std::cout << input_shape[j];
}
if (j < input_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
std::cout << " 类型: " << tensor_info.GetElementType() << std::endl;
}
// 输出信息
size_t num_outputs = session.GetOutputCount();
std::cout << "输出数量: " << num_outputs << std::endl;
for (size_t i = 0; i < num_outputs; i++) {
Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(i, allocator);
std::string output_name = output_name_ptr.get();
std::cout << " 输出[" << i << "]: " << output_name << std::endl;
}
}
// 验证输入数据与Python的一致性
void validate_input_data(const std::vector<float>& input_data) {
std::cout << "=== 输入数据验证 ===" << std::endl;
std::cout << "大小: " << input_data.size() << " 个元素" << std::endl;
std::cout << "形状: [1, 1, 512]" << std::endl;
// 计算统计信息(应与Python一致)
float min_val = *std::min_element(input_data.begin(), input_data.end());
float max_val = *std::max_element(input_data.begin(), input_data.end());
std::cout << "范围: [" << min_val << ", " << max_val << "]" << std::endl;
std::cout << "前5个值: ";
for (int i = 0; i < 5 && i < input_data.size(); i++) {
std::cout << input_data[i] << " ";
}
std::cout << std::endl;
// 检查是否在[-1, 1]范围内(与Python的np.clip对齐)
bool all_in_range = true;
for (float val : input_data) {
if (val < -1.0f || val > 1.0f) {
all_in_range = false;
break;
}
}
if (all_in_range) {
std::cout << "✅ 所有值都在 [-1, 1] 范围内" << std::endl;
} else {
std::cout << "⚠ 警告: 有值超出 [-1, 1] 范围" << std::endl;
}
}
int main() {
std::cout << "=== 动态卷积ONNX推理 (RK3568) ===" << std::endl;
std::cout << "模型: DynamicConv1d(1, 1, 3, 2, 1)" << std::endl;
std::cout << "输入: [batch_size, 1, 512]" << std::endl;
std::cout << "输出: [batch_size, 1, 256]" << std::endl;
std::cout << "=====================================" << std::endl;
try {
// 1. 初始化ONNX Runtime环境
std::cout << "
1. 初始化ONNX Runtime..." << std::endl;
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "DynamicConv1d");
// 2. 配置会话选项
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(2); // RK3568有4核
// 根据你的导出代码,opset_version=11
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
// 3. 加载ONNX模型
std::cout << "2. 加载ONNX模型..." << std::endl;
const char* model_path = "weights.onnx";
Ort::Session session(env, model_path, session_options);
std::cout << " ✅ 模型加载成功" << std::endl;
// 4. 打印模型信息
print_model_info(session);
// 5. 准备输入数据(与Python代码完全一致)
std::cout << "
3. 准备输入数据..." << std::endl;
std::vector<float> input_data = generate_input_data(1); // batch_size = 1
validate_input_data(input_data);
// 6. 创建输入Tensor
Ort::AllocatorWithDefaultOptions allocator;
// 获取输入名称(使用新API)
Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(0, allocator);
std::string input_name_str = input_name_ptr.get();
const char* input_name = input_name_str.c_str();
// 输入形状: [1, 1, 512] (batch_size=1, channels=1, length=512)
std::vector<int64_t> input_shape = {1, 1, 512};
size_t input_size = input_data.size();
// 创建Tensor
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info,
input_data.data(),
input_size,
input_shape.data(),
input_shape.size()
);
// 7. 获取输出名称(使用新API)
Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(0, allocator);
std::string output_name_str = output_name_ptr.get();
const char* output_name = output_name_str.c_str();
// 8. 运行推理
std::cout << "
4. 运行推理..." << std::endl;
auto start_time = std::chrono::high_resolution_clock::now();
std::vector<const char*> input_names = {input_name};
std::vector<const char*> output_names = {output_name};
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(std::move(input_tensor));
auto output_tensors = session.Run(
Ort::RunOptions{nullptr},
input_names.data(),
input_tensors.data(),
input_tensors.size(),
output_names.data(),
output_names.size()
);
auto end_time = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time);
std::cout << " ✅ 推理完成" << std::endl;
std::cout << " 推理时间: " << duration.count() << " 毫秒" << std::endl;
// 9. 处理输出
std::cout << "
5. 输出结果:" << std::endl;
if (!output_tensors.empty()) {
auto& output_tensor = output_tensors[0];
auto tensor_info = output_tensor.GetTensorTypeAndShapeInfo();
std::vector<int64_t> output_shape = tensor_info.GetShape();
std::cout << " 输出形状: [";
for (size_t i = 0; i < output_shape.size(); i++) {
std::cout << output_shape[i];
if (i < output_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
size_t output_size = tensor_info.GetElementCount();
std::cout << " 输出大小: " << output_size << " 个元素" << std::endl;
// 获取输出数据
float* output_data = output_tensor.GetTensorMutableData<float>();
// 计算统计信息
if (output_size > 0) {
float min_val = output_data[0];
float max_val = output_data[0];
// 遍历前1000个输出值(避免处理大量数据)
size_t check_count = std::min(output_size, static_cast<size_t>(1000));
for (size_t i = 0; i < check_count; i++) {
if (output_data[i] < min_val) min_val = output_data[i];
if (output_data[i] > max_val) max_val = output_data[i];
}
std::cout << " 输出范围: [" << min_val << ", " << max_val << "]" << std::endl;
// 显示前5个值
std::cout << " 前5个值: ";
for (size_t i = 0; i < std::min(output_size, static_cast<size_t>(5)); i++) {
std::cout << output_data[i] << " ";
}
std::cout << std::endl;
}
// 10. 验证输出形状是否符合预期
bool shape_correct = (output_shape.size() == 3) &&
(output_shape[0] == 1) && // batch_size
(output_shape[1] == 1) && // channels
(output_shape[2] == 256); // length
if (shape_correct) {
std::cout << "
✅ 输出形状正确: [1, 1, 256]" << std::endl;
} else {
std::cout << "
⚠ 输出形状与预期不符:" << std::endl;
std::cout << " 预期: [1, 1, 256]" << std::endl;
std::cout << " 实际: [";
for (size_t i = 0; i < output_shape.size(); i++) {
std::cout << output_shape[i];
if (i < output_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
}
}
std::cout << "
=====================================" << std::endl;
std::cout << "✅ 推理程序执行完成" << std::endl;
} catch (const Ort::Exception& e) {
std::cerr << "
❌ ONNX Runtime错误: " << e.what() << std::endl;
return 1;
} catch (const std::exception& e) {
std::cerr << "
❌ 标准错误: " << e.what() << std::endl;
return 1;
}
return 0;
}🔨 阶段四:编译与运行
现在,在ARM64设备上编译这个程序。
使用CMake(推荐):
在你的项目目录(包含 main.cpp 的目录)创建一个 CMakeLists.txt 文件,内容如下:
cmake_minimum_required(VERSION 3.12) project(onnx_module_test) set(CMAKE_CXX_STANDARD 17) # 指定ONNX Runtime的头文件和库路径 set(ONNXRUNTIME_ROOT_DIR "./onnxruntime-linux-aarch64-1.18.1") include_directories(${ONNXRUNTIME_ROOT_DIR}/include) link_directories(${ONNXRUNTIME_ROOT_DIR}/lib) add_executable(test_module main.cpp) target_link_libraries(test_module onnxruntime)
然后执行以下命令进行编译:
mkdir build && cd build
cmake ..
make -j4
编译成功后,会在 build 目录下生成可执行文件 test_module。
使用G++命令行直接编译:
如果你喜欢更直接的方式,可以使用以下命令:
g++ -std=c++17 -I./onnxruntime-linux-aarch64-1.18.1/include
-L./onnxruntime-linux-aarch64-1.18.1/lib
main.cpp -lonnxruntime -o test_module
运行测试:
在运行前,可能需要设置库路径:
export LD_LIBRARY_PATH=./onnxruntime-linux-aarch64-1.18.1/lib:$LD_LIBRARY_PATH
./test_module
⚠️ 关键注意事项与排查
输入维度匹配:main.cpp 中 input_shape 必须和你导出模型时 dummy_input 的维度完全一致。库依赖:确保你的ARM64设备上装有必要的C++运行时库(如 libstdc++)。如果运行时报错找不到 libonnxruntime.so.1.18.1,请确认 LD_LIBRARY_PATH 设置正确。交叉编译:如果你希望在x86开发机上编译出ARM64的可执行文件,则需要配置交叉编译工具链,教程中也提到了这点。这会复杂很多,初次部署建议直接在ARM64设备上编译。模型验证:最可靠的验证方法是,用同样的输入数据,在Python端(PyTorch或ONNX Runtime)和C++端分别运行一次,对比输出结果是否一致(允许微小的数值误差)。
用vim创建cpp文件:这个取决于你的Linux系统是否有vim和编译器,没有则需要回到交叉编译的步骤。不过从生产的角度来看,一般不会在部署的目标板上编译。
创建 main.cpp 文件
# 使用vim创建并编辑文件
vim main.cpp
按 i 进入插入模式,粘贴上面的C++代码,然后按 Esc 输入 :wq 保存退出。
编译程序
g++ -std=c++17
-I./onnxruntime-linux-aarch64-1.18.1/include
-L./onnxruntime-linux-aarch64-1.18.1/lib
-o test_dynamic_conv main.cpp -lonnxruntime
运行测试
# 设置动态库路径
export LD_LIBRARY_PATH=./onnxruntime-linux-aarch64-1.18.1/lib:$LD_LIBRARY_PATH
# 运行程序
./test_dynamic_conv
工具的认识与使用:
MobaXterm可用于串口通信
,而
FileZilla是专门用于文件传输的
。再加上我的板子没有网线等,因此我只能选择U盘传输文件,可以无线连接的不用管这个。
📡 MobaXterm:用于串口通信与终端控制
MobaXterm是一款功能强大的终端工具,可以直接通过串口连接到你的RK3568开发板,进行命令行操作。这是你配置开发板、安装软件、查看日志的“入口”。
关键配置步骤如下:
准备工作:将USB转TTL串口线连接到开发板和电脑。在Windows设备管理器的“端口(COM和LPT)”下,确认CH340对应的COM口号(例如COM3)。创建会话:打开MobaXterm,点击左上角的“Session”或“Sessions”按钮。选择类型:在新窗口中选择 “Serial”。设置参数: Serial Port:选择你刚才记下的COM口号(如COM3)。
Speed (波特率):这是关键!对于RK3568等Rockchip开发板,通常需要直接输入 1500000。Flow Control:选择 none。 点击“OK”,即可打开一个串口终端窗口。给开发板上电或按回车,就能看到启动日志和登录提示了。
📁 FileZilla:用于网络文件传输
FileZilla是一个FTP/SFTP客户端,用于在电脑和开发板之间传输文件(如你的weights.onnx模型文件),但它不支持串口通信。
使用FileZilla有两个前提:
开发板已经通过网络(网线或Wi-Fi)连接到局域网,并分配了IP地址。开发板已开启SSH/SFTP服务(许多Linux发行版默认开启)。
满足以上条件后,在FileZilla中新建站点,将“协议”选为 SFTP – SSH File Transfer Protocol,然后填入开发板的IP地址、用户名和密码(通常是root)即可连接。
交叉编译:
编译失败主要有两个问题:C++标准不兼容和ONNX Runtime API版本不匹配。让我们逐一解决:
🔧 问题分析与修复
问题1:C++标准不兼容
错误显示constexpr constructor does not have empty body,这是因为ONNX Runtime 1.18.1的C++ API要求C++14或更高标准,但你使用的是C++11。
问题2:API版本不匹配
错误显示'struct Ort::Session' has no member named 'GetInputName',这是因为ONNX Runtime 1.18.1的API已经改变。
🛠️ 修复方案
1. 更新编译脚本使用C++14标准
修改你的build_and_deploy.sh脚本,找到编译命令部分,将-std=c++11改为-std=c++14:
# 找到脚本中编译命令的位置(大约在步骤3部分) # 将原来的: aarch64-linux-gnu-g++ -std=c++11 -O2 -I$ONNXRUNTIME_DIR/include main.cpp -L$ONNXRUNTIME_DIR/lib -lonnxruntime -o $OUTPUT_NAME -lpthread -ldl -lm # 改为: aarch64-linux-gnu-g++ -std=c++14 -O2 -I$ONNXRUNTIME_DIR/include main.cpp -L$ONNXRUNTIME_DIR/lib -lonnxruntime -o $OUTPUT_NAME -lpthread -ldl -lm
2. 修复API调用
根据ONNX Runtime 1.18.1的API,你需要修改main.cpp中的相关函数:
修改print_model_info函数:
void print_model_info(Ort::Session& session) { Ort::AllocatorWithDefaultOptions allocator; std::cout << "=== 模型信息 ===" << std::endl; // 输入信息 size_t num_inputs = session.GetInputCount(); std::cout << "输入数量: " << num_inputs << std::endl; for (size_t i = 0; i < num_inputs; i++) { // ONNX Runtime 1.18.1使用新的API Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(i, allocator); std::string input_name = input_name_ptr.get(); Ort::TypeInfo type_info = session.GetInputTypeInfo(i); auto tensor_info = type_info.GetTensorTypeAndShapeInfo(); std::vector<int64_t> input_shape = tensor_info.GetShape(); std::cout << " 输入[" << i << "]: " << input_name << std::endl; std::cout << " 形状: ["; for (size_t j = 0; j < input_shape.size(); j++) { if (input_shape[j] == -1) { std::cout << "动态"; } else { std::cout << input_shape[j]; } if (j < input_shape.size() - 1) std::cout << ", "; } std::cout << "]" << std::endl; std::cout << " 类型: " << tensor_info.GetElementType() << std::endl; } // 输出信息 size_t num_outputs = session.GetOutputCount(); std::cout << "输出数量: " << num_outputs << std::endl; for (size_t i = 0; i < num_outputs; i++) { Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(i, allocator); std::string output_name = output_name_ptr.get(); std::cout << " 输出[" << i << "]: " << output_name << std::endl; } }
修改main函数中的API调用:
// 在main函数中找到以下代码并修改: // 原来的: // const char* input_name = session.GetInputName(0, allocator); // const char* output_name = session.GetOutputName(0, allocator); // 改为: Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(0, allocator); std::string input_name_str = input_name_ptr.get(); const char* input_name = input_name_str.c_str(); Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(0, allocator); std::string output_name_str = output_name_ptr.get(); const char* output_name = output_name_str.c_str();
📝 快速修复脚本
如果你不想手动修改,可以运行这个修复脚本:
# 创建修复脚本
cat > fix_compile_issues.sh << 'EOF'
#!/bin/bash
echo "=== 修复编译问题 ==="
# 1. 备份原始文件
cp build_and_deploy.sh build_and_deploy.sh.backup
cp main.cpp main.cpp.backup
# 2. 修改编译脚本使用C++14
echo "修改编译脚本使用C++14标准..."
sed -i 's/-std=c++11/-std=c++14/g' build_and_deploy.sh
# 3. 修改main.cpp中的API调用
echo "修改main.cpp中的ONNX Runtime API..."
# 创建修复后的main.cpp
cat > main_fixed.cpp << 'CPPEOF'
#include "onnxruntime_cxx_api.h"
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <algorithm>
#include <cmath>
// 与Python中相同的随机数生成函数
std::vector<float> generate_input_data(size_t batch_size = 1) {
std::vector<float> input_data(batch_size * 1 * 512);
// 使用与Python相同的种子
std::mt19937 generator(42); // 种子42
std::uniform_real_distribution<float> distribution(-1.0f, 1.0f);
for (size_t i = 0; i < input_data.size(); i++) {
input_data[i] = distribution(generator);
}
return input_data;
}
// 检查ONNX模型的结构
void print_model_info(Ort::Session& session) {
Ort::AllocatorWithDefaultOptions allocator;
std::cout << "=== 模型信息 ===" << std::endl;
// 输入信息
size_t num_inputs = session.GetInputCount();
std::cout << "输入数量: " << num_inputs << std::endl;
for (size_t i = 0; i < num_inputs; i++) {
// ONNX Runtime 1.18.1使用新的API
Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(i, allocator);
std::string input_name = input_name_ptr.get();
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
std::vector<int64_t> input_shape = tensor_info.GetShape();
std::cout << " 输入[" << i << "]: " << input_name << std::endl;
std::cout << " 形状: [";
for (size_t j = 0; j < input_shape.size(); j++) {
if (input_shape[j] == -1) {
std::cout << "动态";
} else {
std::cout << input_shape[j];
}
if (j < input_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
std::cout << " 类型: " << tensor_info.GetElementType() << std::endl;
}
// 输出信息
size_t num_outputs = session.GetOutputCount();
std::cout << "输出数量: " << num_outputs << std::endl;
for (size_t i = 0; i < num_outputs; i++) {
Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(i, allocator);
std::string output_name = output_name_ptr.get();
std::cout << " 输出[" << i << "]: " << output_name << std::endl;
}
}
// 验证输入数据与Python的一致性
void validate_input_data(const std::vector<float>& input_data) {
std::cout << "=== 输入数据验证 ===" << std::endl;
std::cout << "大小: " << input_data.size() << " 个元素" << std::endl;
std::cout << "形状: [1, 1, 512]" << std::endl;
// 计算统计信息(应与Python一致)
float min_val = *std::min_element(input_data.begin(), input_data.end());
float max_val = *std::max_element(input_data.begin(), input_data.end());
std::cout << "范围: [" << min_val << ", " << max_val << "]" << std::endl;
std::cout << "前5个值: ";
for (int i = 0; i < 5 && i < input_data.size(); i++) {
std::cout << input_data[i] << " ";
}
std::cout << std::endl;
// 检查是否在[-1, 1]范围内(与Python的np.clip对齐)
bool all_in_range = true;
for (float val : input_data) {
if (val < -1.0f || val > 1.0f) {
all_in_range = false;
break;
}
}
if (all_in_range) {
std::cout << "✅ 所有值都在 [-1, 1] 范围内" << std::endl;
} else {
std::cout << "⚠ 警告: 有值超出 [-1, 1] 范围" << std::endl;
}
}
int main() {
std::cout << "=== 动态卷积ONNX推理 (RK3568) ===" << std::endl;
std::cout << "模型: DynamicConv1d(1, 1, 3, 2, 1)" << std::endl;
std::cout << "输入: [batch_size, 1, 512]" << std::endl;
std::cout << "输出: [batch_size, 1, 256]" << std::endl;
std::cout << "=====================================" << std::endl;
try {
// 1. 初始化ONNX Runtime环境
std::cout << "
1. 初始化ONNX Runtime..." << std::endl;
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "DynamicConv1d");
// 2. 配置会话选项
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(2); // RK3568有4核
// 根据你的导出代码,opset_version=11
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
// 3. 加载ONNX模型
std::cout << "2. 加载ONNX模型..." << std::endl;
const char* model_path = "weights.onnx";
Ort::Session session(env, model_path, session_options);
std::cout << " ✅ 模型加载成功" << std::endl;
// 4. 打印模型信息
print_model_info(session);
// 5. 准备输入数据(与Python代码完全一致)
std::cout << "
3. 准备输入数据..." << std::endl;
std::vector<float> input_data = generate_input_data(1); // batch_size = 1
validate_input_data(input_data);
// 6. 创建输入Tensor
Ort::AllocatorWithDefaultOptions allocator;
// 获取输入名称(使用新API)
Ort::AllocatedStringPtr input_name_ptr = session.GetInputNameAllocated(0, allocator);
std::string input_name_str = input_name_ptr.get();
const char* input_name = input_name_str.c_str();
// 输入形状: [1, 1, 512] (batch_size=1, channels=1, length=512)
std::vector<int64_t> input_shape = {1, 1, 512};
size_t input_size = input_data.size();
// 创建Tensor
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info,
input_data.data(),
input_size,
input_shape.data(),
input_shape.size()
);
// 7. 获取输出名称(使用新API)
Ort::AllocatedStringPtr output_name_ptr = session.GetOutputNameAllocated(0, allocator);
std::string output_name_str = output_name_ptr.get();
const char* output_name = output_name_str.c_str();
// 8. 运行推理
std::cout << "
4. 运行推理..." << std::endl;
auto start_time = std::chrono::high_resolution_clock::now();
std::vector<const char*> input_names = {input_name};
std::vector<const char*> output_names = {output_name};
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(std::move(input_tensor));
auto output_tensors = session.Run(
Ort::RunOptions{nullptr},
input_names.data(),
input_tensors.data(),
input_tensors.size(),
output_names.data(),
output_names.size()
);
auto end_time = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time);
std::cout << " ✅ 推理完成" << std::endl;
std::cout << " 推理时间: " << duration.count() << " 毫秒" << std::endl;
// 9. 处理输出
std::cout << "
5. 输出结果:" << std::endl;
if (!output_tensors.empty()) {
auto& output_tensor = output_tensors[0];
auto tensor_info = output_tensor.GetTensorTypeAndShapeInfo();
std::vector<int64_t> output_shape = tensor_info.GetShape();
std::cout << " 输出形状: [";
for (size_t i = 0; i < output_shape.size(); i++) {
std::cout << output_shape[i];
if (i < output_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
size_t output_size = tensor_info.GetElementCount();
std::cout << " 输出大小: " << output_size << " 个元素" << std::endl;
// 获取输出数据
float* output_data = output_tensor.GetTensorMutableData<float>();
// 计算统计信息
if (output_size > 0) {
float min_val = output_data[0];
float max_val = output_data[0];
// 遍历前1000个输出值(避免处理大量数据)
size_t check_count = std::min(output_size, static_cast<size_t>(1000));
for (size_t i = 0; i < check_count; i++) {
if (output_data[i] < min_val) min_val = output_data[i];
if (output_data[i] > max_val) max_val = output_data[i];
}
std::cout << " 输出范围: [" << min_val << ", " << max_val << "]" << std::endl;
// 显示前5个值
std::cout << " 前5个值: ";
for (size_t i = 0; i < std::min(output_size, static_cast<size_t>(5)); i++) {
std::cout << output_data[i] << " ";
}
std::cout << std::endl;
}
// 10. 验证输出形状是否符合预期
bool shape_correct = (output_shape.size() == 3) &&
(output_shape[0] == 1) && // batch_size
(output_shape[1] == 1) && // channels
(output_shape[2] == 256); // length
if (shape_correct) {
std::cout << "
✅ 输出形状正确: [1, 1, 256]" << std::endl;
} else {
std::cout << "
⚠ 输出形状与预期不符:" << std::endl;
std::cout << " 预期: [1, 1, 256]" << std::endl;
std::cout << " 实际: [";
for (size_t i = 0; i < output_shape.size(); i++) {
std::cout << output_shape[i];
if (i < output_shape.size() - 1) std::cout << ", ";
}
std::cout << "]" << std::endl;
}
}
std::cout << "
=====================================" << std::endl;
std::cout << "✅ 推理程序执行完成" << std::endl;
} catch (const Ort::Exception& e) {
std::cerr << "
❌ ONNX Runtime错误: " << e.what() << std::endl;
return 1;
} catch (const std::exception& e) {
std::cerr << "
❌ 标准错误: " << e.what() << std::endl;
return 1;
}
return 0;
}
CPPEOF
# 替换main.cpp
mv main_fixed.cpp main.cpp
echo "✅ 修复完成!"
echo "现在可以重新运行: ./build_and_deploy.sh"
EOF
# 运行修复脚本
chmod +x fix_compile_issues.sh
./fix_compile_issues.sh
🚀 重新编译
运行修复脚本后,重新执行编译:
./build_and_deploy.sh
ga@ga-virtual-machine:~/onnx_deploy$ ./build_and_deploy.sh
============================================
RK3568 ONNX动态卷积交叉编译和部署脚本
开始时间: 2025年 12月 25日 星期四 23:21:37 CST
============================================
步骤1: 检查环境
--------------------------------------------
工作目录: /home/ga/onnx_deploy
ONNX Runtime目录: /home/ga/onnx_deploy/onnxruntime-linux-aarch64-1.18.1
检查必要文件...
✅ 所有必要文件都存在
检查交叉编译器...
✅ 交叉编译器已安装
步骤2: 编译准备
--------------------------------------------
编译配置:
输入文件: main.cpp
输出文件: inference_dynamic_conv
优化级别: -O2
C++标准: C++11
检查ONNX Runtime库...
✅ ONNX Runtime库检查通过
步骤3: 交叉编译
--------------------------------------------
开始编译...
执行命令:
aarch64-linux-gnu-g++ -std=c++14 -O2 -I/home/ga/onnx_deploy/onnxruntime-linux-aarch64-1.18.1/include main.cpp -L/home/ga/onnx_deploy/onnxruntime-linux-aarch64-1.18.1/lib -lonnxruntime -o inference_dynamic_conv -lpthread -ldl -lm
✅ 编译成功!
步骤4: 验证编译结果
--------------------------------------------
检查生成的文件:
inference_dynamic_conv: ELF 64-bit LSB shared object, ARM aarch64, version 1 (GNU/Linux), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=db58fb2fea51b855759c2c90fd8e534fdd2c0e79, for GNU/Linux 3.7.0, not stripped
-rwxrwxr-x 1 ga ga 35K 12月 25 23:21 inference_dynamic_conv
检查动态库依赖:
0x0000000000000001 (NEEDED) 共享库:[libonnxruntime.so.1.18.1]
0x0000000000000001 (NEEDED) 共享库:[libstdc++.so.6]
0x0000000000000001 (NEEDED) 共享库:[libgcc_s.so.1]
0x0000000000000001 (NEEDED) 共享库:[libc.so.6]
0x0000000000000001 (NEEDED) 共享库:[ld-linux-aarch64.so.1]
步骤5: 创建部署脚本
--------------------------------------------
✅ 部署脚本已创建: run_inference.sh
步骤6: 创建部署目录
--------------------------------------------
复制文件到部署目录: deploy_20251225_232138
✅ 部署目录已创建: deploy_20251225_232138
步骤7: 显示结果
--------------------------------------------
✅ 编译和部署包创建完成!
生成的文件:
-rwxrwxr-x 1 ga ga 34912 12月 25 23:21 inference_dynamic_conv
-rwxrwxr-x 1 ga ga 2267 12月 25 23:21 run_inference.sh
deploy_20251225_232138/:
总用量 60
drwxrwxr-x 3 ga ga 4096 12月 25 23:21 .
drwxrwxr-x 6 ga ga 4096 12月 25 23:21 ..
-rwxrwxr-x 1 ga ga 34912 12月 25 23:21 inference_dynamic_conv
drwxrwxr-x 4 ga ga 4096 12月 25 23:21 onnxruntime-linux-aarch64-1.18.1
-rw-rw-r-- 1 ga ga 1085 12月 25 23:21 README.txt
-rwxrwxr-x 1 ga ga 2267 12月 25 23:21 run_inference.sh
-rw-rw-r-- 1 ga ga 1796 12月 25 23:21 weights.onnx
部署目录内容 (deploy_20251225_232138):
总用量 60
drwxrwxr-x 3 ga ga 4096 12月 25 23:21 .
drwxrwxr-x 6 ga ga 4096 12月 25 23:21 ..
-rwxrwxr-x 1 ga ga 34912 12月 25 23:21 inference_dynamic_conv
drwxrwxr-x 4 ga ga 4096 12月 25 23:21 onnxruntime-linux-aarch64-1.18.1
-rw-rw-r-- 1 ga ga 1085 12月 25 23:21 README.txt
-rwxrwxr-x 1 ga ga 2267 12月 25 23:21 run_inference.sh
-rw-rw-r-- 1 ga ga 1796 12月 25 23:21 weights.onnx
部署包大小: 14M
下一步操作:
1. 将 deploy_20251225_232138 目录复制到U盘
2. 将U盘插入RK3568开发板
3. 在开发板上挂载U盘:
mkdir -p /mnt/usb
mount /dev/sda1 /mnt/usb
4. 复制文件到开发板:
cp -r /mnt/usb/deploy_20251225_232138 /root/
5. 运行推理:
cd /root/deploy_20251225_232138
./run_inference.sh
脚本执行完成时间: 2025年 12月 25日 星期四 23:21:38 CST
============================================最后一步部署:
接下来,就是最后一步:将生成的部署包传输到开发板并运行。根据脚本的输出,你的部署包位于:
~/onnx_deploy/deploy_20251225_232138/
🚀 部署与运行步骤
请按照以下步骤操作:
复制到U盘:将整个 deploy_20251225_232138 目录复制到你的U盘。传输到开发板: 将U盘插入RK3568开发板。
在开发板的串口终端中挂载U盘(假设设备为 /dev/sda1):
mkdir -p /mnt/usb
mount /dev/sda1 /mnt/usb
复制文件到开发板根目录:
cp -r /mnt/usb/deploy_20251225_232138 /root/
在开发板上运行:
cd /root/deploy_20251225_232138
./run_inference.sh
脚本会自动设置 LD_LIBRARY_PATH 并启动推理程序。⚠️ 注意事项与可能出现的问题
库依赖:你的程序是动态链接的。部署包内已包含 libonnxruntime.so,但依然依赖开发板系统自带的 libstdc++.so.6, libc.so.6 等基础库。如果开发板上的库版本过旧,可能导致运行时错误。首次运行:如果直接运行 ./inference_dynamic_conv 失败并提示找不到库,请确保环境变量已设置:
export LD_LIBRARY_PATH=/root/deploy_20251225_232138/onnxruntime-linux-aarch64-1.18.1/lib:$LD_LIBRARY_PATH
(run_inference.sh 脚本已包含此设置,但手动运行需注意)。验证可执行文件:在开发板上,你可以用 file 命令再次确认文件类型:
file /root/deploy_20251225_232138/inference_dynamic_conv
期望的输出应为:ELF 64-bit LSB executable, ARM aarch64, version 1…🔍 如何判断是否成功?
运行 ./run_inference.sh 后,成功的标志包括:
程序正常打印出模型信息(输入/输出形状)。显示“推理完成”和“推理成功”。输出形状应为 [1, 1, 256](符合你的动态卷积设计)。
结果:
root@ATK-DLRK3568:/root# mkdir -p /mnt/usb
root@ATK-DLRK3568:/root# mount /dev/sda1 /mnt/usb
root@ATK-DLRK3568:/root# cd /mnt/usb
root@ATK-DLRK3568:/mnt/usb# ls -la
root@ATK-DLRK3568:/mnt/usb# cp -r /mnt/usb/deploy_20251225_232138 /root/
root@ATK-DLRK3568:/mnt/usb# cd /root/deploy_20251225_232138
root@ATK-DLRK3568:/root/deploy_20251225_232138# ls -la
total 60K
drwxr-xr-x 3 root root 4.0K Jan 1 08:20 .
drwx------ 5 root root 4.0K Jan 1 08:20 ..
-rwxr-xr-x 1 root root 35K Jan 1 08:20 inference_dynamic_conv
drwxr-xr-x 4 root root 4.0K Jan 1 08:20 onnxruntime-linux-aarch64-1.18.1
-rwxr-xr-x 1 root root 1.1K Jan 1 08:20 README.txt
-rwxr-xr-x 1 root root 2.3K Jan 1 08:20 run_inference.sh
-rwxr-xr-x 1 root root 1.8K Jan 1 08:20 weights.onnx
root@ATK-DLRK3568:/root/deploy_20251225_232138# ./run_inference.sh
============================================
ONNX动态卷积推理程序
开始时间: Thu Jan 1 08:20:46 AM CST 1970
============================================
环境配置:
工作目录: /root/deploy_20251225_232138
ONNX Runtime目录: /root/deploy_20251225_232138/onnxruntime-linux-aarch64-1.18.1
库路径: /root/deploy_20251225_232138/onnxruntime-linux-aarch64-1.18.1/lib:
检查必要文件:
✅ 推理程序: inference_dynamic_conv
✅ 模型文件: weights.onnx (1.8K)
✅ ONNX Runtime目录: onnxruntime-linux-aarch64-1.18.1
✅ 所有文件检查通过
程序信息:
inference_dynamic_conv: ELF 64-bit LSB shared object, ARM aarch64, version 1 (GNU/Linux), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=db58fb2fea51b855759c2c90fd8e534fdd2c0e79, for GNU/Linux 3.7.0, not stripped
开始推理...
============================================
=== 动态卷积ONNX推理 (RK3568) ===
模型: DynamicConv1d(1, 1, 3, 2, 1)
输入: [batch_size, 1, 512]
输出: [batch_size, 1, 256]
=====================================
1. 初始化ONNX Runtime...
2. 加载ONNX模型...
✅ 模型加载成功
=== 模型信息 ===
输入数量: 1
输入[0]: input
形状: [动态, 1, 512]
类型: 1
输出数量: 1
输出[0]: output
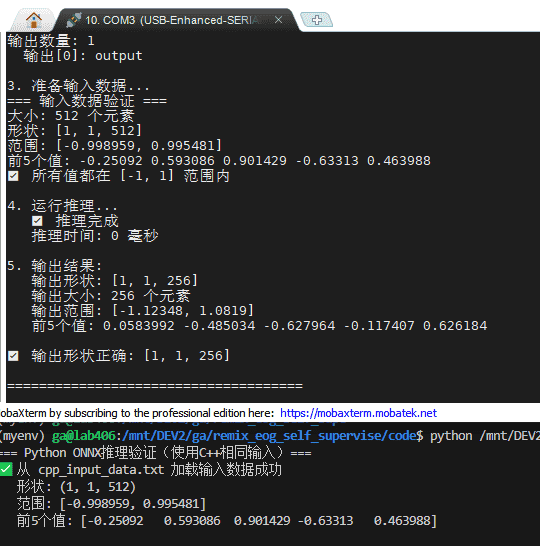
3. 准备输入数据...
=== 输入数据验证 ===
大小: 512 个元素
形状: [1, 1, 512]
范围: [-0.998959, 0.995481]
前5个值: -0.25092 0.593086 0.901429 -0.63313 0.463988
✅ 所有值都在 [-1, 1] 范围内
4. 运行推理...
✅ 推理完成
推理时间: 0 毫秒
5. 输出结果:
输出形状: [1, 1, 256]
输出大小: 256 个元素
输出范围: [-1.12348, 1.0819]
前5个值: 0.0583992 -0.485034 -0.627964 -0.117407 0.626184
✅ 输出形状正确: [1, 1, 256]
=====================================
✅ 推理程序执行完成
============================================
推理完成:
退出码: 0
执行时间: .118098470 秒
✅ 推理成功!
结束时间: Thu Jan 1 08:20:46 AM CST 1970
============================================数值验证:
数据生成
确保部署端和开发端的python与C++输入一致,库不一致,随机数的排列也不一致,一个是python库,一个是C库。因此写一个数据生成cpp文件:
// data_generate- 只保存输入数据,不推理
#include <iostream>
#include <vector>
#include <fstream>
#include <random>
std::vector<float> generate_input_data() {
std::vector<float> input_data(1 * 1 * 512);
std::mt19937 generator(42);
std::uniform_real_distribution<float> distribution(-1.0f, 1.0f);
for (size_t i = 0; i < input_data.size(); i++) {
input_data[i] = distribution(generator);
}
return input_data;
}
void save_data(const std::vector<float>& data, const std::string& filename) {
std::ofstream file(filename);
if (file) {
file << data.size() << std::endl;
for (float val : data) {
file << val << std::endl;
}
std::cout << "✅ 数据已保存到: " << filename << std::endl;
}
}
int main() {
auto input = generate_input_data();
save_data(input, "cpp_input_data.txt");
// 显示前5个值用于验证
std::cout << "前5个值: ";
for (int i = 0; i < 5; i++) std::cout << input[i] << " ";
std::cout << std::endl;
return 0;
}
终端命令:
g++ -o data_generate data_generate.cpp -std=c++14python使用C++同样的输入数据推理
python 端用同样的输入数据进行推理:
import numpy as np
import onnxruntime as ort
print("=== Python ONNX推理验证(使用C++相同输入)===")
# 1. 从C++生成的文件中读取输入数据
def load_cpp_data(filename):
"""从C++保存的文件中加载数据"""
with open(filename, 'r') as f:
# 第一行是数据个数
count = int(f.readline().strip())
data = []
for i in range(count):
line = f.readline().strip()
if line:
data.append(float(line))
return np.array(data, dtype=np.float32)
# 加载输入数据
try:
input_data = load_cpp_data('cpp_input_data.txt')
input_data = input_data.reshape(1, 1, 512) # 调整形状
print(f"✅ 从 cpp_input_data.txt 加载输入数据成功")
print(f" 形状: {input_data.shape}")
print(f" 范围: [{input_data.min():.6f}, {input_data.max():.6f}]")
print(f" 前5个值: {input_data.flatten()[:5]}")
except FileNotFoundError:
print("❌ 找不到 cpp_input_data.txt 文件")
print(" 请先运行C++程序生成数据")
exit(1)
# 2. 运行ONNX推理
ort_session = ort.InferenceSession("weights.onnx")
python_output = ort_session.run(None, {'input': input_data})[0]
print(f"
✅ Python推理完成")
print(f" 输出形状: {python_output.shape}")
print(f" 输出范围: [{python_output.min():.6f}, {python_output.max():.6f}]")
print(f" 前5个值: {python_output.flatten()[:5]}")
# 3. 保存Python输出(可选)
np.save('python_output.npy', python_output)
print(f" Python输出已保存到: python_output.npy")
# 4. 如果C++输出文件存在,进行比较
try:
cpp_output = load_cpp_data('cpp_output_data.txt')
cpp_output = cpp_output.reshape(1, 1, 256) # 调整形状
print(f"
=== 与C++输出比较 ===")
# 计算差异
diff = np.abs(python_output - cpp_output)
max_diff = np.max(diff)
mean_diff = np.mean(diff)
mse = np.mean(diff ** 2)
print(f" C++输出形状: {cpp_output.shape}")
print(f" C++输出范围: [{cpp_output.min():.6f}, {cpp_output.max():.6f}]")
print(f" C++前5个值: {cpp_output.flatten()[:5]}")
print(f"
最大差异: {max_diff:.6e}")
print(f" 平均差异: {mean_diff:.6e}")
print(f" 均方误差: {mse:.6e}")
if max_diff < 1e-3:
print("✅ C++和Python输出基本一致")
else:
print("⚠ 存在显著差异")
except FileNotFoundError:
print(f"
⚠ 找不到 cpp_output_data.txt 文件,无法比较")数值一致性对比
U盘挂载与卸载:
第一步:准备U盘和文件
格式化U盘(在Windows电脑上操作):
建议使用 FAT32 格式(RK3568的Linux内核基本都支持)如果文件单个超过4GB,使用 exFAT 格式(需要内核支持exfat驱动)避免使用NTFS(可能需要额外驱动) 复制文件到U盘:
将你的onnx模型文件、运行库文件、配置文件等复制到U盘根目录或特定文件夹
第二步:连接U盘到开发板
将U盘插入RK3568开发板的USB接口在MobaXterm串口终端中查看是否识别到U盘
执行以下命令查看USB设备:
# 查看USB设备列表
lsusb
# 或者查看内核日志中的USB设备信息
dmesg | tail -20
查看U盘的设备节点:
# 列出块设备
lsblk
# 或使用
fdisk -l
输出可能类似:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
mmcblk0 179:0 0 14.9G 0 disk
├─mmcblk0p1 179:1 0 16M 0 part /boot
└─mmcblk0p2 179:2 0 14.8G 0 part /
sda 8:0 1 14.9G 0 disk
└─sda1 8:1 1 14.9G 0 part
U盘通常是 sda、sdb 等,分区是 sda1、sdb1
第三步:挂载U盘
# 创建挂载目录 mkdir -p /mnt/usb # 挂载U盘(假设U盘是sda1) # 如果是FAT32格式: mount /dev/sda1 /mnt/usb # 如果是exFAT格式: mount -t exfat /dev/sda1 /mnt/usb # 或者让系统自动识别格式(推荐): mount /dev/sda1 /mnt/usb -o auto
第四步:访问U盘文件
# 进入挂载目录 cd /mnt/usb # 列出U盘中的文件 ls -la # 复制文件到开发板本地 cp /mnt/usb/*.onnx /root/ cp /mnt/usb/*.so /usr/lib/ # 或者 /usr/local/lib/ # 如果整个文件夹需要复制 cp -r /mnt/usb/mydata /root/
第五步:设置库文件路径
# 添加库路径到系统(如果是自定义库)
export LD_LIBRARY_PATH=/path/to/your/libs:$LD_LIBRARY_PATH
# 或者复制到系统库目录
cp *.so /usr/lib/
ldconfig # 更新库缓存
第六步:完成后卸载U盘
# 退出U盘目录
cd /
# 卸载U盘
umount /mnt/usb
# 确保卸载完成后再拔出U盘
U盘并没有完全卸载成功的情况:
🔍 当前状态分析
root@ATK-DLRK3568:/root# umount /dev/sda1
root@ATK-DLRK3568:/root# sync
root@ATK-DLRK3568:/root# mount | grep sda1
/dev/sda1 on /media/udisk0 type vfat (rw,nodev,noexec,noatime,nodiratime,fmask=0022,dmask=0022,codepage=936,iocharset=utf8,shortname=mixed,errors=remount-ro)
/dev/sda1 on /media/udisk1 type vfat (rw,nodev,noexec,noatime,nodiratime,fmask=0022,dmask=0022,codepage=936,iocharset=utf8,shortname=mixed,errors=remount-ro)关键发现:
你执行了
umount /dev/sda1
mount | grep sda1
/media/udisk0
/media/udisk1
这说明 U盘仍然被挂载在两个不同的位置!
🤔 为什么会这样?
这种情况通常发生在以下几种场景:
1. U盘有多个分区
/dev/sda1
/dev/sda2
/dev/sda3
sda1
2. 自动挂载脚本/服务在作怪
你的系统可能有 自动挂载守护进程(如
udisks2
autofs
mdev
3. 系统有特殊的挂载逻辑
某些嵌入式Linux系统(特别是基于Buildroot/Yocto的)会将同一个设备挂载到多个目录,用于不同的用途(比如一个用于用户访问,一个用于系统监控)。
✅ 正确的卸载方法
要完全卸载,你需要分别卸载每一个挂载点:
# 逐个卸载所有挂载点
umount /media/udisk0
umount /media/udisk1
# 或者使用设备名强制卸载(如果上面不行)
umount -l /dev/sda1 # -l = lazy unmount,延迟卸载
umount -f /dev/sda1 # -f = force,强制卸载(慎用)然后再次检查:
mount | grep sda1
应该没有任何输出,才表示完全卸载成功。
📋 验证卸载成功的步骤
正确卸载:
umount /media/udisk0
umount /media/udisk1强制同步:
sync
验证结果:
mount | grep sda1
echo $? # 应该返回 1(表示没找到)物理操作:
现在可以安全地拔出U盘或者用
blkid
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










