
在数字化时代,PDF 作为跨平台、保格式的核心文档格式,已深度渗透科研、办公、教育等领域。不过,传统 OCR 工具在处理复杂 PDF 时屡屡碰壁:多列布局文字顺序错乱、公式表格识别失真、页眉页脚干扰有效信息、手写体与旧扫描件识别率低下等问题,成为信息提取的 “拦路虎”。尤其对于需要批量处理文献、构建 LLM 训练数据集的科研人员和企业而言,高效、精准的 PDF 文本化需求愈发迫切,而现有工具要么收费高昂,要么功能残缺,难以兼顾实用性与性价比。
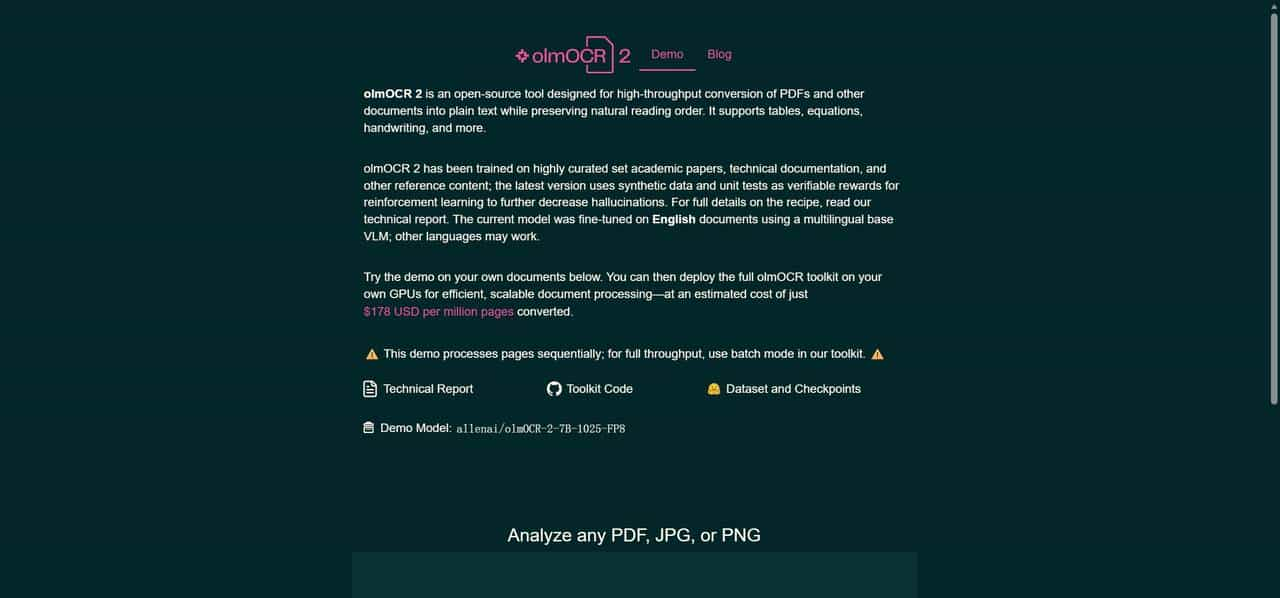
由 AllenNLP 开源的 olmOCR,正是针对这一痛点的突破性解决方案。作为一款基于视觉语言模型(VLM)的文档转换工具包,它不仅能将 PDF、PNG、JPEG 等格式精准转为干净的 Markdown 文本,更攻克了复杂格式识别的诸多难题,且保持着极低的使用成本。olmOCR 的开源发布,不仅为个人用户提供了专业级文档处理工具,更为企业和科研机构大规模处理文档、解锁海量文本数据提供了可行路径,有望推动文档数字化处理领域的效率革命。

简介
olmOCR 是 AllenNLP 开源的一款文档转换工具包,项目托管于 GitHub(
https://github.com/allenai/olmocr),采用 Apache-2.0 开源协议。olmOCR 的核心定位是将图像类文档(PDF、PNG、JPEG)转换为结构化、高可读性的纯文本(主要为 Markdown 格式),其核心优势体目前多维度的功能突破:
- 格式兼容性极强,不仅支持标准 PDF,还能处理图片格式文档,尤其擅长识别公式、表格、手写体等复杂元素,解决了传统 OCR 的核心痛点;
- 智能排版优化,能够自动识别多列布局、嵌入式图表与文本插图,按自然阅读顺序重组内容,同时精准去除页眉页脚等冗余信息;
- 效率与成本平衡,基于 VLM 模型与 vllm 推理 pipeline 优化,单页处理速度快,且百万页处理成本控制在 200 美元以内,远低于同类商业工具;
- 部署灵活,支持本地单机、Docker 容器、AWS S3 多节点集群等多种部署方式,满足个人用户与企业级大规模处理需求。
在应用场景方面,olmOCR 展现出极强的通用性:科研领域可用于批量转换 ArXiv 论文、会议文献,快速提取研究成果与公式数据,构建科研知识库;办公场景能处理多格式报告、合同文件,实现文本检索与内容复用,提升办公效率;教育领域可将教材、课件转为纯文本,方便二次编辑与无障碍阅读;数据构建场景则能为 LLM 训练解锁海量 PDF 中的文本资源,生成高质量训练数据。此外,项目还配套推出了 olmOCR-Bench 基准测试套件,涵盖 7000 余个测试用例、1400 余份文档,为 OCR 系统性能评估提供了标准化工具。
从性能表现来看,olmOCR 在基准测试中展现出显著优势。在 olmOCR-Bench 的综合评分中,v0.1.75 版本以 75.5 分的成绩超越 Marker、MinerU、Mistral OCR API 等同类工具,尤其在旧扫描件(42.2 分)、公式(71.2 分)、表格(71.0 分)等传统难点场景中,识别率大幅领先。这一成绩得益于其优化的 prompt 策略、温度参数调节与 vllm 推理框架的引入,使其在复杂场景下的鲁棒性远超同类工具。
使用
olmOCR 基于视觉语言模型开发,核心依赖 GPU 加速推理,具体环境要求如下:
- 硬件要求:NVIDIA GPU(已测试 RTX 4090、L40S、A100、H100),显存≥20GB;磁盘空间≥30GB(用于存储模型、依赖与输出文件)。
- 系统支持:优先推荐 Ubuntu/Debian 系统(兼容性最佳),Windows 与 macOS 需通过 Docker 或 WSL2 运行。
- 基础依赖:需安装 poppler-utils(PDF 渲染工具)与多种字体包(确保文本渲染准确性)。
第一更新系统包管理器,并安装必需的依赖工具与字体:
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools -y上述依赖包含 PDF 渲染核心工具、微软核心字体与开源替代字体,确保不同语言、不同格式的文本都能正常识别。
使用 conda 创建并激活 olmocr 专属环境
conda create -n olmocr python=3.11 -y
conda activate olmocr根据使用场景选择不同安装版本,GPU 版本需额外指定 PyTorch CUDA 镜像源:
# 仅用于运行基准测试(CPU-only,不支持文档转换)
pip install olmocr[bench]
# GPU版本(推荐,支持文档转换,CUDA 12.8)
pip install olmocr[gpu] --extra-index-url https://download.pytorch.org/whl/cu128
# 可选:安装flash infer加速GPU推理(性能提升30%+)
pip install https://download.pytorch.org/whl/cu128/flashinfer/flashinfer_python-0.2.5%2Bcu128torch2.7-cp38-abi3-linux_x86_64.whlolmOCR 通过命令行工具olmocr.pipeline实现文档转换,支持单个 / 多个 PDF、图片文件的批量处理,核心参数–markdown可将结果保存为结构化 Markdown 文件。
转换单个 PDF 文件
# 步骤1:下载官方样本PDF(用于测试)
curl -o olmocr-sample.pdf https://olmocr.allenai.org/papers/olmocr_3pg_sample.pdf
# 步骤2:执行转换(指定输出目录为./localworkspace,生成Markdown文件)
python -m olmocr.pipeline ./localworkspace --markdown --pdfs olmocr-sample.pdf转换完成后,Markdown 文件存储在
./localworkspace/markdown/目录下,可通过以下命令查看:
cat ./localworkspace/markdown/olmocr-sample.md转换图片格式文档(PNG/JPEG)
olmOCR 支持直接处理图片类文档,命令格式与 PDF 转换一致:
# 假设本地有图片文件random_page.png,执行转换
python -m olmocr.pipeline ./localworkspace --markdown --pdfs random_page.png支持的图片格式包括 PNG、JPEG,即使是手写体图片或模糊扫描件,也能精准识别文本内容。
批量转换多个 PDF 文件
通过通配符*可批量指定多个 PDF 文件,适合处理文件夹内的批量文档:
# 转换tests/gnarly_pdfs目录下的所有PDF文件
python -m olmocr.pipeline ./localworkspace --markdown --pdfs tests/gnarly_pdfs/*.pdf批量转换时,工具会自动保持输入文件的目录结构,输出 Markdown 文件将按原路径组织,方便后续管理。
总结
olmOCR 作为 AllenNLP 开源的文档转换工具包,以 精准识别、高效处理、低成本部署 为核心优势,彻底解决了传统 OCR 工具在复杂场景下的痛点。其核心功能覆盖 PDF、图片等多种格式,支持公式、表格、手写体、多列布局等复杂元素的精准识别,自动去除页眉页脚冗余信息,输出结构化 Markdown 文本,完美平衡了识别精度与可读性。技术层面,基于 7B 参数 VLM 模型与 vllm 推理框架,结合 flash infer 加速技术,使其在 20GB 显存 GPU 上即可高效运行,百万页处理成本不足 200 美元,显著低于商业工具。此外,olmOCR 提供了完整的部署方案,从本地单机到大规模集群,从原生环境到 Docker 容器,满足不同用户的使用场景。
在数字化转型加速的今天,olmOCR 的应用价值远超单纯的PDF 转文本。对于科研人员,它能快速提取文献中的核心信息与公式数据,构建个人知识库;对于企业,它可批量处理合同、报告等办公文档,降低信息提取成本,提升协作效率;对于 AI 开发者,它能解锁海量 PDF 中的文本资源,为 LLM 训练提供高质量数据集。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












olmOCR 作为 AllenNLP 开源的文档转换工具包,以精准识别、高效处理、低成本部署 为核心优势,彻底解决了传统 OCR 工具在复杂场景下的痛点。其核心功能覆盖 PDF、图片等多种格式,公式、表格、手写体、多列布局等复杂元素的精准识别,自动去除页眉页脚冗余信息,输出结构化 Markdown 文本,完美平衡了识别精度与可读性。技术层面,基于 7B 参数 VLM 模型与 vllm 推理框架,结合 flash infer 加速技术,使其在 20GB 显存 GPU 上即可高效运行,百万页处理成本不足 200 美元,显著低于商业工具。此外,olmOCR 提供了完整的部署方案,从本地单机到大规模集群,从原生环境到 Docker 容器,满足不同用户的使用场景。
苹果m4可以使用不?
收藏了,感谢分享