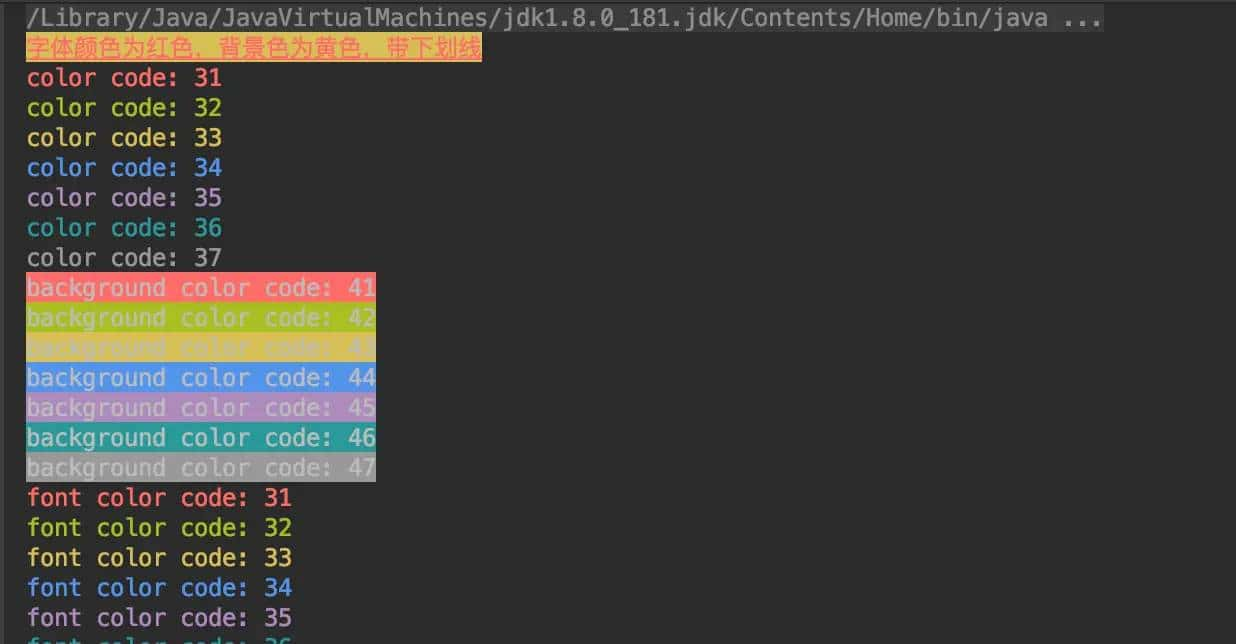
这个代码是一个用于爬取国家统计局网站数据的Python脚本。下面我将详细解释代码的各个部分及其设计思路。
代码结构概述
import requests # 发送HTTP请求
from bs4 import BeautifulSoup # 解析HTML
import pandas as pd # 数据处理和存储
import time # 时间控制
import random # 随机数生成
import os # 文件系统操作
import re # 正则表达式函数设计思路
1. 请求头设置

headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp...',
'referer': 'https://www.stats.gov.cn/sj/zxfbhjd/202508/t20250822_1960866.html'
}设计思路:
模拟真实浏览器行为,避免被网站反爬机制拦截
设置Referer头,使请求看起来是从合法页面跳转而来
使用常见的User-Agent字符串,增加请求的合法性
2. 随机延迟机制
time.sleep(random.uniform(1, 3))设计思路:
避免过于频繁的请求导致IP被封
使用随机时间间隔,模拟人类操作的不规律性
1-3秒的间隔既不会太慢影响效率,也不会太快触发反爬
3. 请求与响应处理
response = requests.get(url, headers=headers, timeout=30)
response.encoding = 'utf-8' # 设置编码设计思路:
设置30秒超时,避免长时间等待无响应
显式设置编码为UTF-8,确保中文正确显示
检查状态码,确保请求成功
4. 表格解析与处理
tables = soup.find_all('table')
# 分析表格结构
max_cols = 0
for j, row in enumerate(rows):
cells = row.find_all(['td', 'th'])
if len(cells) > max_cols:
max_cols = len(cells)设计思路:
查找页面中的所有表格
分析每个表格的结构,确定最大列数
确保每行数据有相同的列数,避免DataFrame创建时出错
代码解析
1.
tables = soup.find_all('table')
tables = soup.find_all('table')
作用:查找HTML文档中的所有
<table>
设计思路:国家统计局的数据通常以表格形式展示,所以首先找到所有表格
2.
cells = row.find_all(['td', 'th'])
cells = row.find_all(['td', 'th'])
作用:在每一行中查找所有的
<td>
<th>
为什么同时查找td和th:
<td>
<th>
两者都需要提取,因为表头也包含重要信息
有些表格可能混合使用td和th,或者使用th作为行标题
3.
if len(cells) > max_cols: max_cols = len(cells)
if len(cells) > max_cols: max_cols = len(cells)
作用:确定表格的最大列数
为什么需要这个:
HTML表格可能有不规则结构(某些行可能有合并的单元格)
为了创建规整的DataFrame,需要知道表格的最大宽度
确保所有行都有相同的列数,不足的用空值填充
设计思路详解
1. 处理不规则表格
HTML表格可能有不规则结构,例如:
<table>
<tr>
<th>标题1</th>
<th>标题2</th>
<th>标题3</th>
</tr>
<tr>
<td>数据1</td>
<td colspan="2">合并单元格</td> <!-- 这一行只有2个单元格,但占据2列 -->
</tr>
</table>在这种情况下,代码会:
第一行:找到3个单元格(th),设置max_cols=3
第二行:找到2个单元格(td),但max_cols保持3
后续处理时,第二行会被填充到3列(添加一个空单元格)
2. 确保数据规整性
通过确定最大列数,可以:
创建统一结构的DataFrame
避免因列数不一致导致的数据错位
保持数据的完整性,便于后续分析
3. 完整的工作流程
这段代码是完整表格处理流程的一部分:
找到所有表格
对每个表格,确定最大列数
逐行处理,确保每行有相同的列数
创建规整的二维数组
转换为DataFrame进行后续处理
这种方法是处理网页表格数据的标准做法,确保了即使面对不规则HTML表格,也能提取出规整的结构化数据。
5. 数据清理
text = cell.get_text().strip()
text = re.sub(r's+', ' ', text) # 移除多余的空格和换行符设计思路:
去除文本前后的空白字符
使用正则表达式将多个连续空白字符替换为单个空格
确保数据整洁,便于后续处理
代码解析
1.
text = cell.get_text().strip()
text = cell.get_text().strip()
cell.get_text()
.strip()
示例:
<td> GDP数据 <br/>2023年 </td>使用
get_text()
" GDP数据
2023年 "
使用
.strip()
"GDP数据
2023年"
2.
text = re.sub(r's+', ' ', text)
text = re.sub(r's+', ' ', text)
r's+'
s
+
re.sub(pattern, replacement, string)
这里将所有连续的空白字符替换为单个空格
示例:
输入:
"GDP数据
2023年"
输出:
"GDP数据 2023年"
设计思路
1. 处理HTML中的不规则空白
HTML中的文本经常包含:
用于布局的额外空格
换行符(
)
制表符(
其他不可见字符
这些字符在数据分析和处理中通常是无用甚至有害的,需要清理。
2. 保持数据可读性
完全移除所有空白会使文本难以阅读(如”GDP数据2023年”)
保留单个空格确保文本仍然可读(”GDP数据 2023年”)
3. 确保数据一致性
不同单元格可能有不同的空白格式
统一处理确保所有数据格式一致
便于后续的数据比较和分析
4. 完整的清理流程
这两行代码提供了一个简单但有效的文本清理流程:
移除首尾空白(避免边缘空白影响)
规范化内部空白(确保内部空白一致)
实际应用场景
假设从国家统计局网站提取的表格数据如下:
原始HTML:
<td>
地区生产总值
<br>
(亿元)
</td>
<td> 123,456.78 </td>处理过程:
get_text()
"
地区生产总值
<br>
(亿元)
"
.strip()
"地区生产总值
<br>
(亿元)"
re.sub(r's+', ' ', text)
"地区生产总值 (亿元)"
最终得到整洁的文本:
"地区生产总值 (亿元)"
这种文本清理方法是网页数据抓取中的标准做法,确保了提取的数据既整洁又保持了原有的语义结构。
6. 多种格式保存
df.to_csv(filepath, index=False, header=False, encoding='utf-8-sig')
df.to_excel(excel_filepath, index=False, header=False)设计思路:
同时保存CSV和Excel两种格式
CSV格式通用且轻量,Excel格式保持更好的表格结构
使用
utf-8-sig
不保存索引和标题行(index=False, header=False),因为原始表格已包含表头
7. 输出目录管理
os.makedirs('stats_data', exist_ok=True)设计思路:
创建专门目录存储爬取的数据
exist_ok=True
保持文件组织有序
8. 时间戳命名
timestamp = time.strftime("%Y%m%d_%H%M%S")设计思路:
使用时间戳确保文件名唯一
格式化的时间戳便于排序和查找最新文件
避免覆盖之前爬取的数据
9. 汇总文件创建
with pd.ExcelWriter(summary_filepath) as writer:
for i, df in enumerate(all_data):
df.to_excel(writer, sheet_name=f'Table_{i+1}', index=False, header=False)设计思路:
将所有表格整合到一个Excel文件中
每个表格放在单独的工作表(sheet)中
便于用户一次性查看所有数据
代码解析
1.
with pd.ExcelWriter(summary_filepath) as writer:
with pd.ExcelWriter(summary_filepath) as writer:
pd.ExcelWriter
summary_filepath
with ... as writer:
2.
for i, df in enumerate(all_data):
for i, df in enumerate(all_data):
all_data
enumerate(all_data)
循环处理每个 DataFrame
3.
df.to_excel(writer, sheet_name=f'Table_{i+1}', index=False, header=False)
df.to_excel(writer, sheet_name=f'Table_{i+1}', index=False, header=False)
df.to_excel()
writer
sheet_name=f'Table_{i+1}'
index=False
header=False
设计思路
1. 使用上下文管理器
with
即使发生异常,文件也会被正确关闭
避免文件损坏或资源泄漏
2. 多工作表设计
将每个表格放在单独的工作表中
避免单个工作表过于庞大难以管理
保持原始表格的结构和分离性
3. 动态命名工作表
f'Table_{i+1}'
确保每个工作表有唯一的名称
名称中包含表格序号,便于识别
4. 控制输出内容
index=False
header=False
实际应用场景
假设爬取了国家统计局的三个表格,这段代码会:
创建一个 Excel 文件(如
stats_gov_data_20230815_143022_summary.xlsx
在文件中创建三个工作表:
Table_1
Table_2
Table_3
每个工作表只包含原始表格数据,没有额外的索引或列名
10. 异常处理
try:
# 主要代码
except requests.exceptions.Timeout:
print("请求超时,请检查网络连接或稍后重试")
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {str(e)}")
except Exception as e:
print(f"爬取过程中发生错误: {str(e)}")
import traceback
traceback.print_exc()设计思路:
专门处理请求超时情况
处理一般网络请求错误
使用try-except捕获所有可能的异常
打印详细错误信息和堆栈跟踪,便于调试
代码解析
1. 整体结构
这是一个标准的 try-except 结构,用于捕获和处理代码执行过程中可能出现的异常。
2. 分层异常处理
代码使用了多个 except 块,按照从特定到一般的顺序处理异常:
a. 处理请求超时异常
except requests.exceptions.Timeout:
print("请求超时,请检查网络连接或稍后重试")专门处理:只捕获请求超时异常
用户友好提示:提供明确的解决方案建议
设计思路:超时是网络爬虫常见问题,单独处理可以提供更具体的指导
b. 处理其他网络请求异常
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {str(e)}")通用网络异常:捕获所有与网络请求相关的异常
显示错误详情:通过
str(e)
设计思路:网络问题可能多种多样(连接错误、DNS解析失败等),统一处理但显示具体信息
c. 处理其他所有异常
except Exception as e:
print(f"爬取过程中发生错误: {str(e)}")
import traceback
traceback.print_exc()兜底处理:捕获所有未被前面 except 块处理的异常
详细错误信息:不仅显示错误消息,还打印完整的堆栈跟踪
动态导入:只在需要时导入 traceback 模块,减少不必要的导入
设计思路
1. 用户体验优先
提供清晰、友好的错误消息,而不是让程序突然崩溃
根据异常类型给出针对性的建议
帮助用户理解问题所在和可能的解决方案
2. 调试支持
对于未知异常,提供详细的堆栈跟踪信息
使用
traceback.print_exc()
区分已知问题和未知问题,提供不同级别的详细信息
3. 代码健壮性
确保程序不会因为意外错误而完全崩溃
即使部分功能失败,也能提供有用的反馈信息
允许程序在遇到错误后继续执行其他操作或优雅退出
4. 异常分类处理
区分不同类型的异常,提供不同的处理方式
网络超时 vs 其他网络错误 vs 程序逻辑错误
从特定到一般的处理顺序,确保每个异常都能被适当处理
实际应用场景
场景1: 网络连接问题
用户网络不稳定,请求超时
程序会提示:”请求超时,请检查网络连接或稍后重试”
场景2: 网站服务器问题
目标网站暂时不可用或返回错误状态码
程序会提示:”网络请求错误: [具体错误信息]”
场景3: 代码逻辑错误
解析HTML时遇到意外结构或数据格式
程序会提示错误消息并打印完整的堆栈跟踪,帮助开发者调试
11. 详细日志输出
print(f"找到{len(tables)}个表格")
print(f"表格{i+1}有{len(rows)}行")
print(f"表格{i+1}最大列数: {max_cols}")设计思路:
提供详细的处理进度信息
帮助用户了解爬虫当前状态
便于调试和问题排查
整体设计理念
稳健性:通过异常处理、随机延迟和请求头设置,提高爬虫的稳定性和成功率
用户体验:提供详细的进度信息和错误提示,便于用户了解情况
数据完整性:多种格式保存,确保数据可用性
可扩展性:模块化设计,便于后续添加新功能或修改现有功能
合规性:设置合理的请求间隔,尊重目标网站的服务器负载
这个爬虫设计考虑到了实际使用中的各种情况,是一个相对成熟和稳健的数据采集解决方案。
完整代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
import os
import re
def get_stats_gov_data():
# 爬取国家数据
# 设置表头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'referer':'https://www.stats.gov.cn/sj/zxfbhjd/202508/t20250822_1960866.html'
}
# 国家统计局URL
url = "https://www.stats.gov.cn/sj/zxfbhjd/202508/t20250822_1960866.html"
try:
# 添加随机延迟,避免请求过于频繁
time.sleep(random.uniform(1, 3))
# 发送请求,增加超时时间
print("正在访问国家统计局...")
response = requests.get(url, headers=headers, timeout=30)
response.encoding = 'utf-8' # 设置编码
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
return None
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找数据表格
tables = soup.find_all('table')
if not tables:
print("未找到数据表格")
return None
print(f"找到{len(tables)}个表格")
# 创建输出目录
os.makedirs('stats_data', exist_ok=True)
timestamp = time.strftime("%Y%m%d_%H%M%S")
# 提取表格数据
all_data = []
for i, table in enumerate(tables):
print(f"
{'='*60}")
print(f"处理第{i+1}个表格...")
print(f"{'='*60}")
# 获取表格中的所有行
rows = table.find_all('tr')
print(f"表格{i+1}有{len(rows)}行")
# 分析表格结构
max_cols = 0
for j, row in enumerate(rows):
cells = row.find_all(['td', 'th'])
if len(cells) > max_cols:
max_cols = len(cells)
print(f"表格{i+1}最大列数: {max_cols}")
# 创建二维数组来存储表格数据
table_data = []
for row in rows:
cells = row.find_all(['td', 'th'])
row_data = []
for cell in cells:
# 获取单元格文本并清理
text = cell.get_text().strip()
# 移除多余的空格和换行符
text = re.sub(r's+', ' ', text)
row_data.append(text)
# 确保每行有相同的列数
if len(row_data) < max_cols:
row_data.extend([''] * (max_cols - len(row_data)))
table_data.append(row_data)
# 创建DataFrame
df = pd.DataFrame(table_data)
# 保存为CSV
filename = f"stats_gov_data_{timestamp}_table_{i+1}.csv"
filepath = os.path.join('stats_data', filename)
df.to_csv(filepath, index=False, header=False, encoding='utf-8-sig')
print(f"表格{i+1}已保存到 {filepath}")
# 保存为Excel格式,提供更好的格式保持
excel_filename = f"stats_gov_data_{timestamp}_table_{i+1}.xlsx"
excel_filepath = os.path.join('stats_data', excel_filename)
df.to_excel(excel_filepath, index=False, header=False)
print(f"表格{i+1}Excel版本已保存到 {excel_filepath}")
# 显示表格内容
print(f"
表格{i+1}内容:")
print("-" * 80)
# 设置pandas显示选项,确保所有内容都能显示
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', None)
# 显示整个表格
print(df.to_string(index=False, header=False))
# 重置pandas显示选项
pd.reset_option('display.max_rows')
pd.reset_option('display.max_columns')
pd.reset_option('display.width')
pd.reset_option('display.max_colwidth')
all_data.append(df)
print(f"
表格{i+1}处理完成")
print(f"{'='*60}")
# 创建一个汇总的Excel文件,包含所有表格
summary_filename = f"stats_gov_data_{timestamp}_summary.xlsx"
summary_filepath = os.path.join('stats_data', summary_filename)
with pd.ExcelWriter(summary_filepath) as writer:
for i, df in enumerate(all_data):
df.to_excel(writer, sheet_name=f'Table_{i+1}', index=False, header=False)
print(f"
所有表格的汇总文件已保存到 {summary_filepath}")
print("数据爬取和保存完成!")
return all_data
except requests.exceptions.Timeout:
print("请求超时,请检查网络连接或稍后重试")
return None
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {str(e)}")
return None
except Exception as e:
print(f"爬取过程中发生错误: {str(e)}")
import traceback
traceback.print_exc()
return None
# 运行爬虫
if __name__ == "__main__":
data = get_stats_gov_data()
if data:
print("
数据爬取成功!")
print(f"共爬取了 {len(data)} 个表格")
# 显示每个表格的基本信息
for i, df in enumerate(data):
print(f"
表格{i+1}:")
print(f" 行数: {df.shape[0]}")
print(f" 列数: {df.shape[1]}")
print(f" 前5行数据:")
print(df.head().to_string(index=False, header=False))© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...






![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/8.jpg)



