

开篇引入:当数据量突破千万级,单库单表还能撑多久?
平台订单系统遭遇了典型的”数据膨胀危机”:随着用户量突破500万,订单表数据量以每月80万条的速度激增,单表记录在半年内从300万飙升至780万。随之而来的是查询性能断崖式下降——原本200ms的订单查询延迟增至1.5秒,数据库连接池频繁耗尽,甚至出现部分交易超时失败。
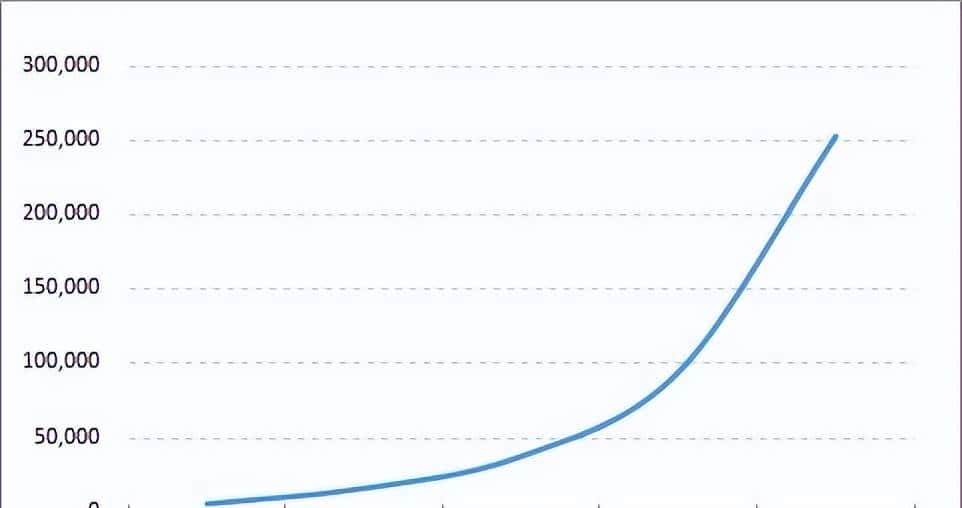
这种增长曲线在互联网业务中极为常见。根据阿里数据库团队的实践经验,MySQL单表数据量超过500万行时,B+树索引深度增加导致查询效率骤降;当达到1000万行时,即使最优索引也难以避免全表扫描的性能损耗。分库分表成为突破瓶颈的必然选择,而Sharding-JDBC作为轻量级Java中间件,以其无侵入性和高性能特性,成为多数Java团队的首选方案。
核心原理:一文读懂Sharding-JDBC的”黑盒”机制
架构设计:为什么Sharding-JDBC比MyCat更轻量?
Sharding-JDBC采用客户端直连架构,无需额外部署代理服务,直接以Jar包形式嵌入应用。这种设计带来两个核心优势:一是性能损耗低于7%(远优于代理模式的20%+损耗),二是避免代理层成为单点故障。其架构可分为三层:
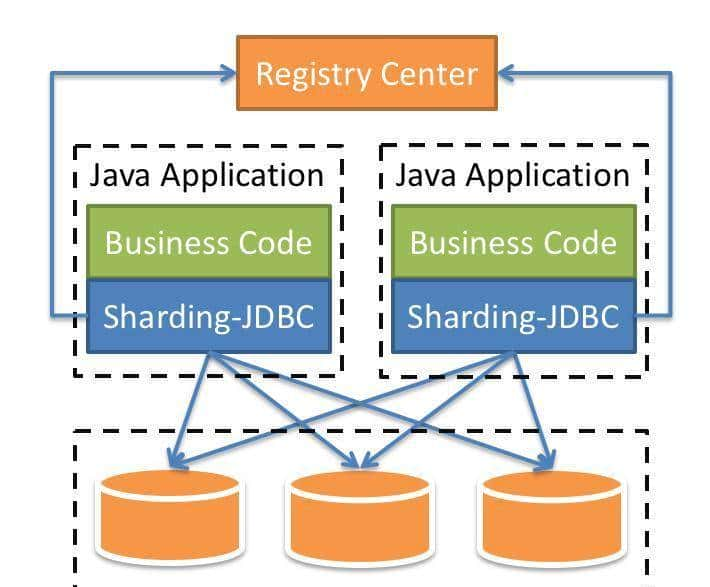
- 应用层:业务代码通过标准JDBC接口操作逻辑表(如t_order),完全感知不到物理分库分表的存在。
- 核心层:包含四大引擎协同工作
- SQL解析引擎:将SQL解析为抽象语法树(AST),提取表名、分片键、条件表达式等关键信息
- 路由引擎:根据分片规则计算数据所在的物理库表,支持准确路由、范围路由、广播路由等策略
- 改写引擎:将逻辑SQL改写为物理SQL,如将SELECT * FROM t_order改写为SELECT * FROM t_order_0
- 执行引擎:多线程并发执行物理SQL,并合并结果集返回
- 数据层:由多个物理数据库组成,Sharding-JDBC通过数据源代理实现对多库的透明访问。
SQL解析流程:一条SQL如何穿越分片迷宫?
以订单查询SELECT * FROM t_order WHERE order_id = 12345 AND user_id = 678为例,Sharding-JDBC的处理流程如下:
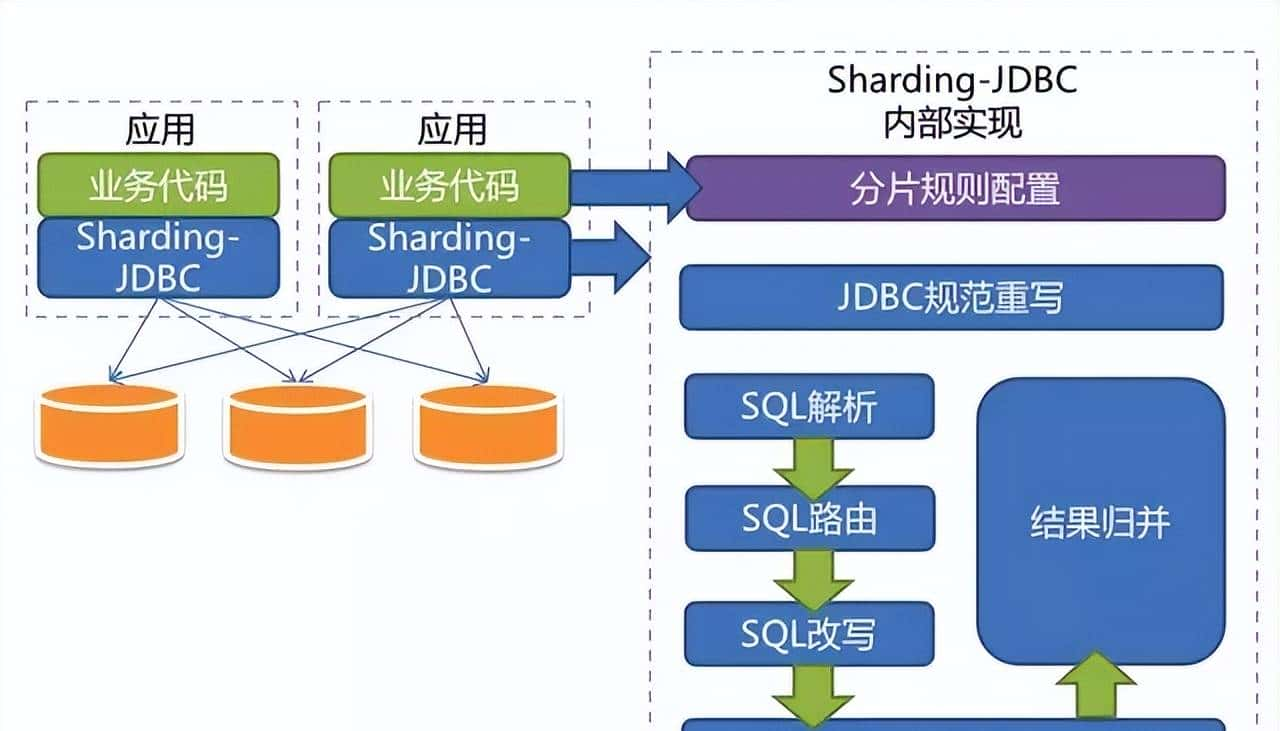
- 词法解析:识别SQL中的关键字、表名、字段等Token
- 语法解析:构建AST抽象语法树,确定查询类型为SELECT,涉及表t_order
- 分片路由:
- 提取分片键order_id=12345(假设配置order_id为分片键)
- 应用分片算法(如order_id % 4)计算得到分片索引2
- 路由至物理表t_order_2
- SQL改写:将逻辑表名替换为物理表名
- 执行归并:执行改写后的SQL并返回结果
中间件对比:3大方案怎么选?
|
特性 |
Sharding-JDBC |
MyCat |
Sharding-Proxy |
|
部署方式 |
嵌入应用 |
独立服务 |
独立服务 |
|
性能损耗 |
<7% |
20-30% |
15-25% |
|
语言支持 |
仅Java |
多语言 |
多语言 |
|
分布式事务 |
支持XA/BASE |
弱XA |
支持XA/BASE |
|
适用场景 |
高性能OLTP |
多语言需求 |
运维管控优先 |
选型提议:Java应用优先选Sharding-JDBC,多语言架构可选Sharding-Proxy,MyCat由于社区活跃度下降已逐渐被ShardingSphere替代。
实战配置:Spring Boot集成Sharding-JDBC全流程
环境准备
本次实战基于Spring Boot 2.7.18 + Sharding-JDBC 5.1.1,实现订单表的分库分表(2库4表)和读写分离。核心依赖如下:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.18</version>
</dependency>
数据源与分片规则配置
spring:
shardingsphere:
datasource:
names: master0,master1,slave0,slave1
# 主库0配置
master0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db0
username: root
password: 123456
max-active: 50
min-idle: 10
# 主库1配置(省略,结构同上)
# 从库0/1配置(省略,结构同上)
rules:
sharding:
tables:
t_order:
actual-data-nodes: master$->{0..1}.t_order_$->{0..1}
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: order_db_inline
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: order_table_inline
key-generate-strategy:
column: order_id
key-generator-name: snowflake
# 读写分离规则
readwrite-splitting-rules:
order_ds:
type: Static
props:
write-data-source-name: master$->{0..1}
read-data-source-names: slave$->{0..1}
load-balancer-name: round_robin
# 分片算法
sharding-algorithms:
order_db_inline:
type: INLINE
props:
algorithm-expression: master$->{user_id % 2}
order_table_inline:
type: INLINE
props:
algorithm-expression: t_order_$->{order_id % 2}
# 分布式主键
key-generators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
props:
sql-show: true # 打印SQL
核心代码实现
1. 实体类
@Data
@TableName("t_order")
public class Order {
private Long orderId;
private Long userId;
private BigDecimal amount;
private String status;
private LocalDateTime createTime;
}
2. Mapper接口
public interface OrderMapper extends BaseMapper<Order> {
// 按用户ID查询订单(带分片键,路由到单库)
List<Order> selectByUserId(@Param("userId") Long userId);
// 按时间范围查询(范围路由)
@Select("SELECT * FROM t_order WHERE create_time BETWEEN #{start} AND #{end}")
List<Order> selectByTimeRange(@Param("start") LocalDateTime start, @Param("end") LocalDateTime end);
}
3. 测试验证
@SpringBootTest
public class OrderTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testInsert() {
Order order = new Order();
order.setUserId(1000L); // 用户ID=1000,分库算法1000%2=0 → master0
order.setAmount(new BigDecimal("99.99"));
order.setStatus("PAID");
order.setCreateTime(LocalDateTime.now());
orderMapper.insert(order);
// 控制台输出SQL:INSERT INTO master0.t_order_1 ...
// (order_id由雪花算法生成,假设order_id%2=1 → t_order_1)
}
}
避坑指南:生产环境必踩的5个”深坑”
1. 分布式事务:数据一致性如何保障?
问题:跨库操作时,单库事务无法保证全局一致性。例如订单创建和库存扣减分别操作不同数据库,可能出现部分成功部分失败的情况。
解决方案:
- LOCAL事务:适用于单库操作,性能最优但不保证跨库一致性
- XA事务:通过两阶段提交保证强一致性,性能损耗约30%
@Transactional
@ShardingTransactionType(TransactionType.XA)
public void createOrder(Order order, List<OrderItem> items) {
orderMapper.insert(order);
orderItemMapper.batchInsert(items); // 跨库操作
}
- BASE事务:采用Seata AT模式实现最终一致性,性能损耗<10%
@GlobalTransactional // Seata注解
public void createOrder(Order order, List<OrderItem> items) {
// 业务逻辑
}
2. 跨库JOIN:关联查询怎么办?
问题:用户表按userId分片,订单表按orderId分片,查询”用户订单列表”需跨库JOIN。
解决方案矩阵:
|
方案 |
适用场景 |
实现复杂度 |
性能 |
|
绑定表 |
主子表同分片键(如order和order_item都按order_id分片) |
低 |
高 |
|
广播表 |
小表(如字典表) |
低 |
高 |
|
冗余字段 |
读多写少场景 |
中 |
高 |
|
应用层聚合 |
无法同分片的关联查询 |
高 |
中 |
最佳实践:
# 配置绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
3. 数据迁移:不停机怎么玩?
问题:现有单库数据需迁移至分库分表架构,如何避免业务中断?
双写迁移方案:
- 部署双写服务:同时向老库和新库写入数据
- 全量同步:使用Sharding-Scaling工具同步历史数据
- 数据校验:对比新老库数据一致性
- 流量切换:逐步将读流量切换至新库
- 下线老库:确认无误后停写老库
4. 分页查询:越往后翻页越慢?
问题:LIMIT 100000, 20在分片环境下会被改写为LIMIT 0, 100020,导致大量数据传输。
优化方案:
- “禁止跳页”查询:记录上次查询的最大ID,改为WHERE id > lastId LIMIT 20
- 二次查询法:先查主键再查详情
// 优化前
List<Order> page = orderMapper.selectPage(new Page(5000, 20), queryWrapper);
// 优化后
List<Long> ids = orderMapper.selectIdPage(new Page(5000, 20), queryWrapper);
List<Order> details = orderMapper.selectBatchIds(ids);
5. 索引设计:分片键必须是主键吗?
问题:分片键与查询条件不匹配导致全表扫描。例如按order_id分片,查询条件却只用user_id。
最佳实践:
- 优先选择高频查询字段作为分片键
- 复合索引必须包含分片键,如(user_id, order_id)
- 避免使用范围查询字段作为分片键(易导致数据倾斜)
性能调优:从”能用”到”好用”的3个维度
连接池配置:不是越大越好
连接池参数直接影响系统吞吐量,以下为生产环境优化值:
|
参数 |
提议值 |
说明 |
|
maximumPoolSize |
20-50 |
按CPU核心数*2+有效磁盘数计算 |
|
minimumIdle |
5-15 |
为maximumPoolSize的30% |
|
connectionTimeout |
3000ms |
避免长时间阻塞 |
|
maxLifetime |
1800000ms |
30分钟,小于数据库wait_timeout |
配置示例:
spring.shardingsphere.datasource.master0.maximum-pool-size: 30
spring.shardingsphere.datasource.master0.minimum-idle: 10
spring.shardingsphere.datasource.master0.connection-timeout: 3000
分片算法:取模vs范围怎么选?
|
算法 |
数据分布 |
扩容难度 |
适用场景 |
|
取模分片 |
均匀 |
难(需数据迁移) |
用户ID、订单ID等 |
|
范围分片 |
可能倾斜 |
易(新增分片) |
时间序列数据 |
|
哈希分片 |
均匀 |
中 |
高并发读写场景 |
性能对比:在1000万数据量下,取模分片查询延迟比范围分片低15-20%,但范围分片支持按时间范围快速归档。
缓存策略:命中率提升30%的秘诀
- 本地缓存:使用Caffeine缓存热点数据
@Bean
public Cache<String, User> userCache() {
return Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
}
- 二级缓存:MyBatis二级缓存+Redis分布式缓存
<cache type="org.mybatis.caches.redis.RedisCache"/>
- 查询结果缓存:Sharding-JDBC内置SQL解析缓存,开启后可减少30%解析耗时
spring.shardingsphere.props.sql-parser.cache: true
通过三级缓存协同,可将热点数据查询命中率从50%提升至80%以上,显著降低数据库压力。
总结:分库分表的”道”与”术”
Sharding-JDBC作为轻量级分库分表解决方案,通过无侵入架构和灵活配置,让Java应用以最小成本突破数据瓶颈。但技术选型需牢记”三分技术,七分业务”——没有银弹方案,只有适合业务场景的选择。
最佳实践原则:
- 业务优先:分片键选择必须贴合查询模式
- 循序渐进:从单表到分表,再到分库,逐步演进
- 监控先行:通过ShardingSphere-UI监控分片性能
- 预案充足:提前规划扩容策略和数据迁移方案
随着业务发展,分库分表只是开始,后续还需结合读写分离、数据归档、弹性伸缩等手段,构建真正的分布式数据库架构。而Sharding-JDBC作为Apache顶级项目,持续迭代的分布式事务、数据治理等功能,将为这些挑战提供更完善的解决方案。
#Sharding-JDBC实战# #分库分表解决方案# #Java中间件# #数据库性能优化# #Spring Boot集成#
感谢关注【AI码力】,获得更多Java秘籍!
© 版权声明
文章版权归作者所有,未经允许请勿转载。












太难了
Sharding-JDBC实战:5大模块解决分库分表难题
收藏了,感谢分享