

背景
在 Nginx 1.15.10 版本之后,引入了 listen port1-port2 监听范围端口的语法,可以方便的在一个 server 块同时监听多个端口,如下所示:
worker_processes 128;
........
server {
listen 127.0.0.1:2000-5000 backlog=20480 ssl reuseport;
listen 6000-8000;
..........这样就可以在 127.0.0.1 这个IP下同时监听 2000 到 5000 这范围内所有端口;同时在一个 server 块下,可以同时配置多条 listen 语句。
问题
之前在基于定制 Nginx 的项目需要,预先监听必定数量的端口,尽可能不触发 nginx reload 过程。在测试环境下,按如下配置时, 即开启 128 worker 预监听 3000 多个端口,reload 过程超级慢(而刚启动时速度很迅速),预计达到 7 min 左右。
分析
通过在 ngx_init_cycle 函数里面手动插入日志分析发现,reload 卡在从 old_cycle->listening 中监听描述符 fd 复用到新的 cycle->listening 这段逻辑里面
if (old_cycle->listening.nelts) {
ls = old_cycle->listening.elts;
for (i = 0; i < old_cycle->listening.nelts; i++) {
tmp = *(struct sockaddr_in *)ls[i].sockaddr;
// 调试加入日志
ngx_log_error(NGX_LOG_NOTICE, old_cycle->log, 0, "================> listening addr_text: %s:%d, fd: %d, worker: %d",
inet_ntoa(tmp.sin_addr), ntohs(tmp.sin_port), ls[i].fd, ls[i].worker);
ls[i].remain = 0;
}
nls = cycle->listening.elts;
// 调试加入日志
ngx_log_error(NGX_LOG_NOTICE, cycle->log, 0, "====================> cycle->listening.nelts: %d, old_cycle->listening.nelts: %d", cycle->listening.nelts, old_cycle->listening.nelts);
for (n = 0; n < cycle->listening.nelts; n++) {
tmp = *(struct sockaddr_in *)nls[n].sockaddr;
// 调试加入日志
ngx_log_error(NGX_LOG_NOTICE, cycle->log, 0, "================> listening addr_text: %s:%d, fd: %d, worker: %d",
inet_ntoa(tmp.sin_addr), ntohs(tmp.sin_port), nls[n].fd, ls[i].worker);
for (i = 0; i < old_cycle->listening.nelts; i++) {
if (ls[i].ignore) {
continue;
}
if (ls[i].remain) {
continue;
}
if (ls[i].type != nls[n].type) {
continue;
}
if (ngx_cmp_sockaddr(nls[n].sockaddr, nls[n].socklen,
ls[i].sockaddr, ls[i].socklen, 1)
== NGX_OK)
{
nls[n].fd = ls[i].fd;
nls[n].previous = &ls[i];
ls[i].remain = 1;
if (ls[i].backlog != nls[n].backlog) {
nls[n].listen = 1;
}
.................................从 12 行代码开始有两个 for 循环用于查找对应的 listening 配置,查找算法为 O(n**2). 目前 worker_processes 设置为 50,listen 范围改成 2000-3000 个端口测试一下
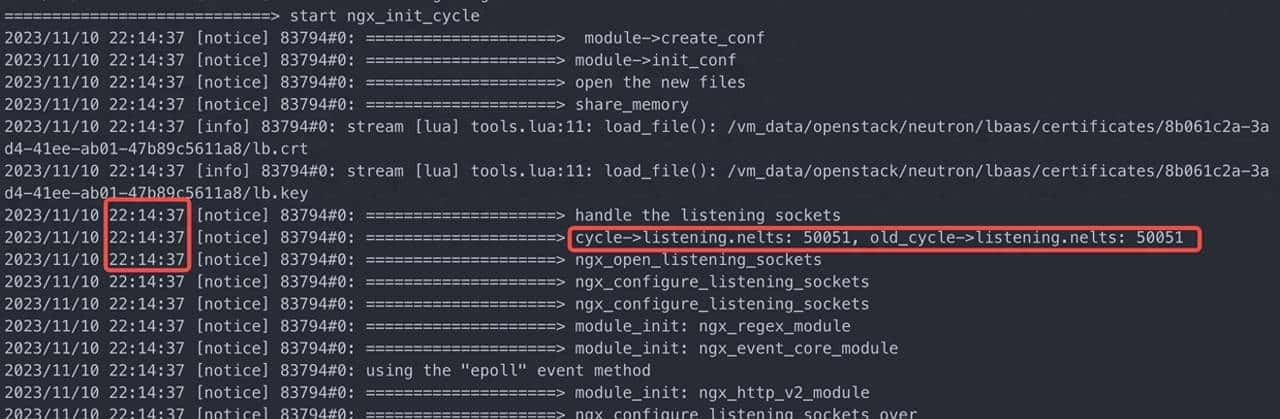
红框里面三行日志看起来是一样的,实则第二行到第三行之间中间隔了好几秒,但这里打印的时间却是一样的。
缘由在于 ngx_log_error 里面使用的是 ngx_cached_err_log_time,顾名思义这里使用的是缓存的时间,以便提高输出日志性能。ngx_cached_err_log_time 的更新是在 ngx_time_update() 函数里面,
而 ngx_time_update() 又只会在 nginx 事件处理函数才会被更新调用,目前 nginx block 在这里,自然不会调用 ngx_time_update() 更新时间, 所以在上面两行日志输出之前手动加上 ngx_time_update() 函数,得到如下
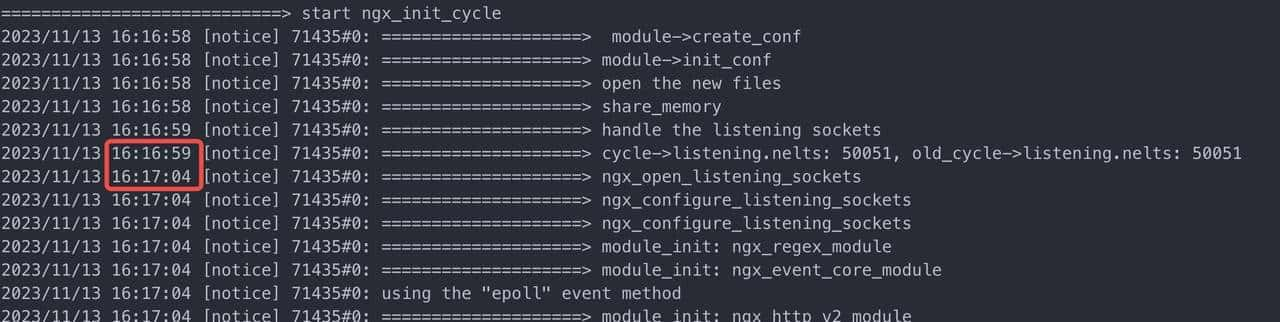
可见这里就花了 5s 多,另外有一点疑惑,这里为什么会是 50051 个监听项呢?已知目前是 listen 127.0.0.1:2000-3000 (共 1001 个端口,且配置了 reuseport);还有 80 管理端口,这里没有设置 reuseport;
所以 1001 * 50 + 1 = 50051 才对得上这个数目。将监听数目减少一下点(3个端口,5个worker),额外打印详细日志,可以验证这一结论:
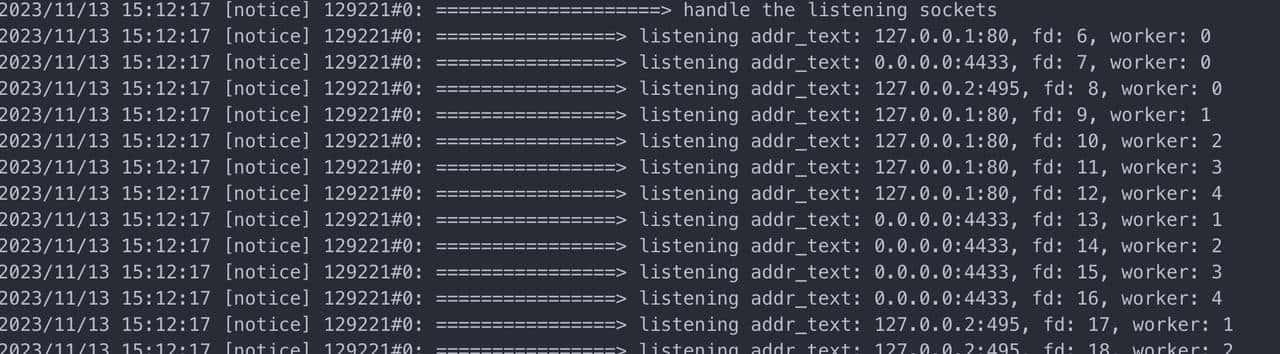
查看 Nginx 源码可知,当监听项配置了 reuseport 时,会额外增加 WorkerNum – 1 个监听项
// src/event/ngx_event.c:459
#if (NGX_HAVE_REUSEPORT)
ls = cycle->listening.elts;
for (i = 0; i < cycle->listening.nelts; i++) {
if (!ls[i].reuseport || ls[i].worker != 0) {
continue;
}
if (ngx_clone_listening(cycle, &ls[i]) != NGX_OK) {
return NGX_CONF_ERROR;
}
/* cloning may change cycle->listening.elts */
ls = cycle->listening.elts;
}
#endif
...................
// src/core/ngx_connection.c:115
for (n = 1; n < ccf->worker_processes; n++) {
/* create a socket for each worker process */
ls = ngx_array_push(&cycle->listening);
if (ls == NULL) {
return NGX_ERROR;
}
*ls = ols;
ls->worker = n;
}正由于此,当配置了 reuseport 时,cycle->listening 数目会乘以 worker 数这一放大系数,而监听项复用算法又是O(n**2)规模,于是 128 worker 配置 (3001 + 1)端口时,监听项会达到 128 * 3001 + 1 = 384129,需要处理 384129*384129 次匹配,处理耗时高达了 7min, 而刚开始时 50 worker + 1000 端口大致就 5s 左右,可见越到后面,耗时放大更明显。
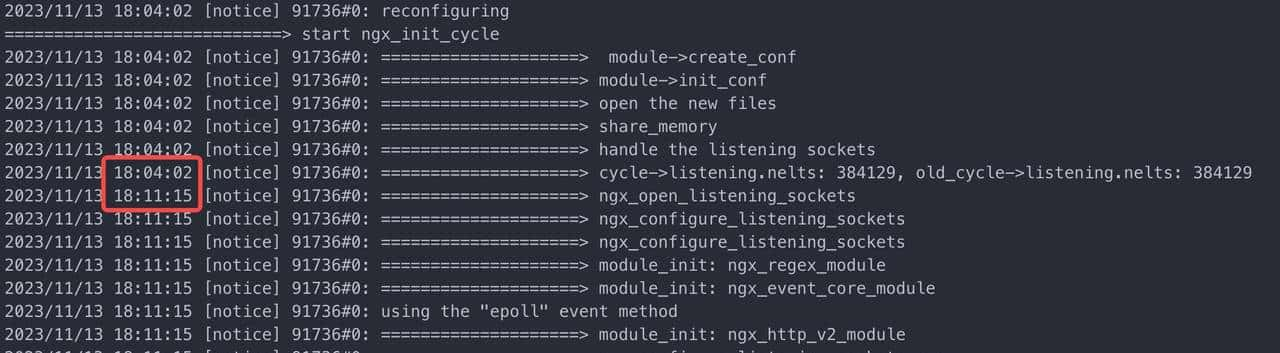
缓解方案
查看了最新上游的 Nginx 的代码,这一块的处理没有变化,依旧跟目前的一样。由于它的目的是复用监听 fd,可以思考有以上三种缓解方案:
- 简单粗暴地做法是不复用,直接重新新建 fd,此时 fd 数量将翻倍。由于 reuseport 的放大作用,可能会突破 master 进程最大打开文件数限制;
- 由于动态 server 基本上不会触发 reload 流程,预监听端口数可一次配置为单机可服务的上限,所以变配时保证不改变端口,那么此处可以思考一次顺序遍历,按数组下标一次复制即可;
- 保证变配时的顺序性,即如有新增端口,将 listen 语句在最后添加,原有 listen 语句相对顺序不变,此时可以用双指针来优化匹配。
方案二、三都有必定的前提条件,避免了方案一的全部重建,极端情况不保证所有监听 fd 都能得到有效地复用,后面依然可以通过
ngx_open_listening_sockets 新建 fd 来弥补,保证后续流程正确性。

欢迎关注微信公众号【抽象网元】
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









