一、双雄同期登场:国产编程模型的舆论与实测撕裂
9 月底的 AI 圈迎来 “神仙打架” 时刻:DeepSeek V3.2-Exp 与智谱 GLM-4.6 几乎同步发布,两款 355B 级旗舰模型迅速引发行业热议。从公开舆论看,GLM-4.6 凭借权威榜单的亮眼表现收获大量好评,官方更是宣称其 “代码能力对齐 Claude Sonnet 4”,俨然一副 “国产编程王者” 的姿态。
但程序员的世界从不是 “榜单说了才算”。带着对舆论的好奇,我以Web 前端开发这一大模型最擅长的领域为核心,用完全一样的提示词对两款模型进行 “零修改单次生成” 盲测。结果却与舆论预期大相径庭 —— 被低估的 DeepSeek V3.2 反而展现出更扎实的实战能力。
二、先看舆论场:GLM-4.6 的榜单霸权
不可否认,GLM-4.6 在公开测评中的确 拿出了统治级表现。在 SWE-Bench Verified、LCB v6 等 8 大国际基准测试中,其多项核心指标超越 DeepSeek V3.2:
- 代码准确率:GLM-4.6 在 Claude Code 环境的 74 个真实任务中达 92%,较 DeepSeek V3.2 高出 8 个百分点;
- 长上下文能力:上下文窗口从 128K 升级至 200K,可一次性处理 50 万字内容,较 DeepSeek V3.2 理论上更适配大型项目;
- 硬件适配性:率先实现寒武纪芯片 FP8+Int4 混合量化部署,推理成本降低显著,这也是其获得企业端关注的重大缘由。
智谱公开的 Agent 轨迹与测试数据可复现性,进一步强化了外界对其 “国产最强 Coding 模型” 的认知。但这些数据真能直接等同于前端开发的实战体验吗?
三、前端盲测实录:DeepSeek V3.2 的反转时刻
为还原真实开发场景,测试工具采用claude code,目前两家模型都是同时支持claude的API的。
任务提示词:
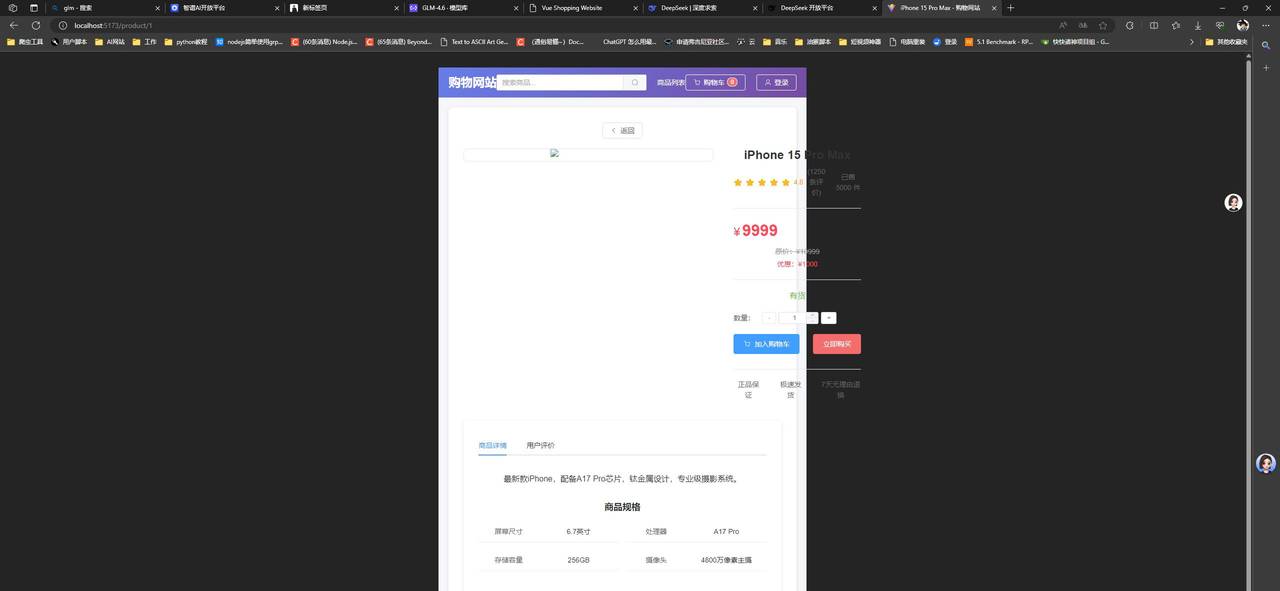
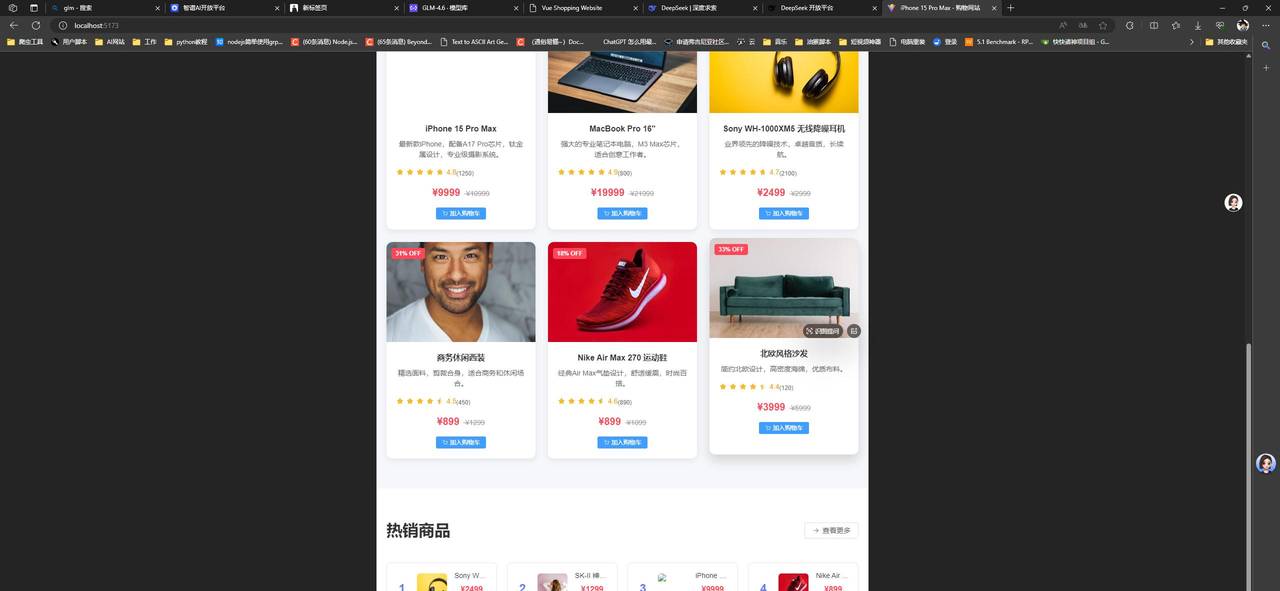
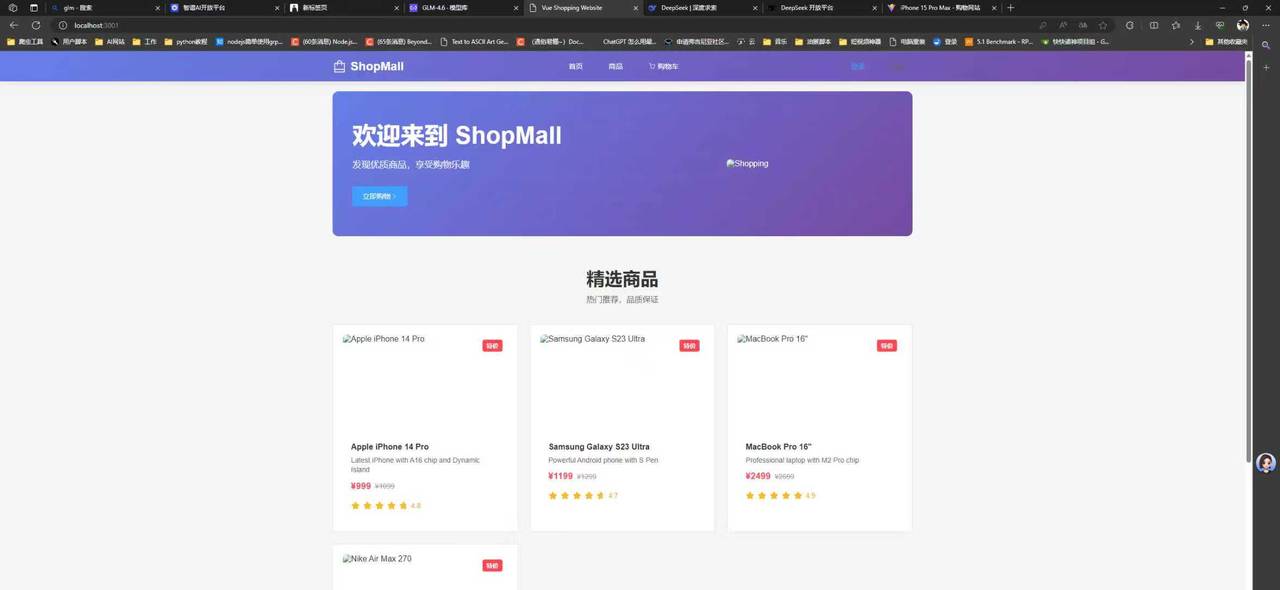
vite+vue3+elementui写一个纯前端的购物网站,要求页面优美大方,包含登录注册,购物车,商品详情页面,商品列表和搜索分类下面是GLM4.6的生成效果:

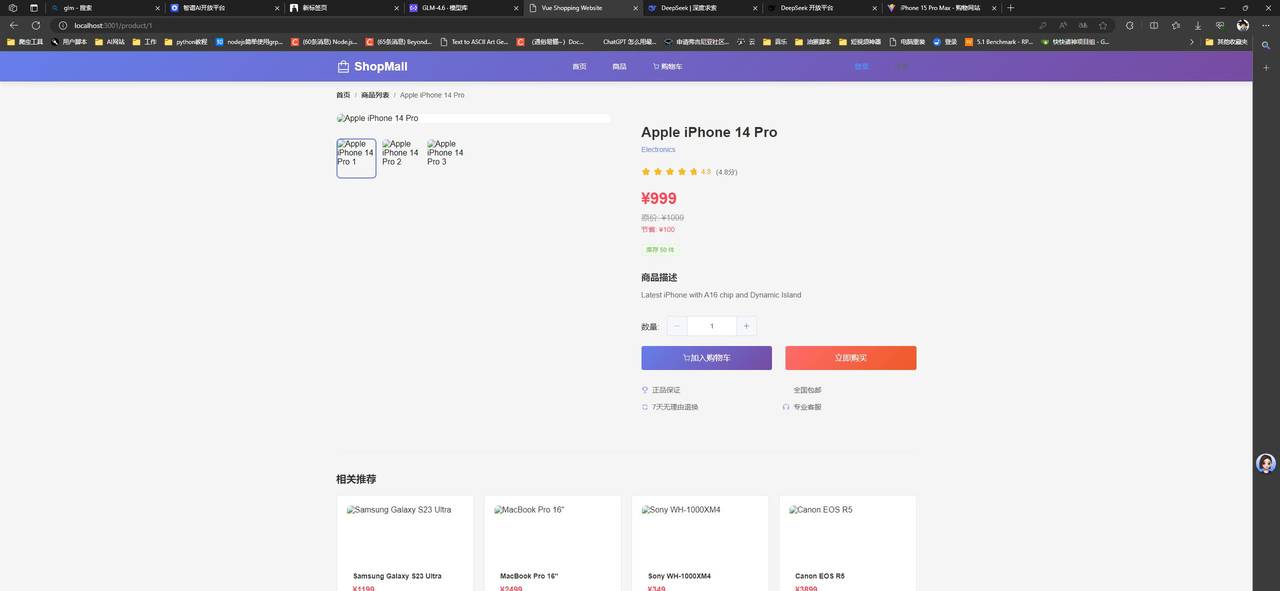
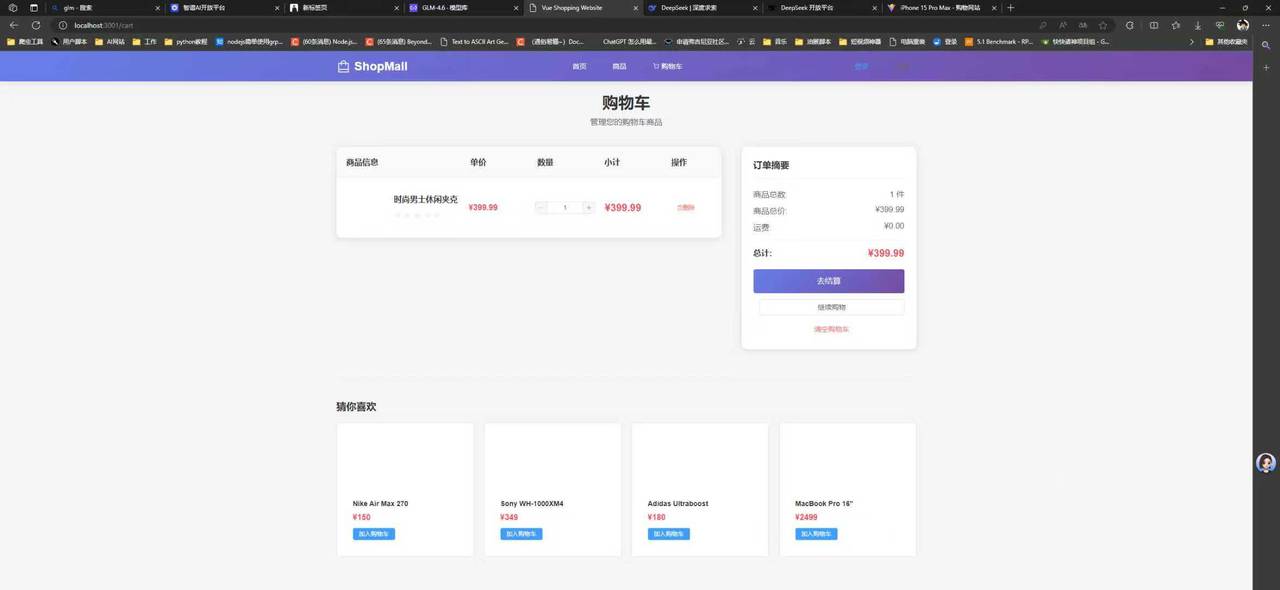
下面是deepseekV3.2的生成效果
这边声明一下,两个网站都是一次提示词生成,中间没有经过任何二次对话的环节
根据图片对比我们不难发现,两者在功能的完成度来讲都是可用的。GLM在提示词外功能补全会更丰富一些,但是致命的缺陷就是UI适配做得很差劲,就说这样的布局看起来不像是移动端的也不像是PC端的。反观deepseek表现的比较稳定,所有页面都保持了一样的间距尺寸,没有出现布局异常的情况。
实则对于这个结果小编也是挺意外的,一是GLM4.6居然在最擅长的领域翻车了,二是deepseek做出来的美观程度相对以前好太多了。我愿称deepseek国产最强,不知道大家有什么不一样的见解欢迎留言讨论。
© 版权声明
文章版权归作者所有,未经允许请勿转载。













我只知道两者的价格天差地别,相差很多
deepseek3.2性能相比于3.1是降低的,优势是成本
3.2代码能力提升了不少
顺便看了作者的两篇文章 写得真好 果断关注
这些ai生成的网页都挺喜欢用这个丑土紫的
编程必须是qwen3,有时候比claude还强
GML 就是笑话,用了的都知道
选Deepseek,性价比最高。
实测对比很有意义呢😄
很强,学习了🤙
QWEN3