古籍扫描像“开盲盒”,一页明清刻本丢进去,89.7%的字能直接蹦进电脑,剩下那10%多半是虫蛀的缺口——国家图书馆试了几个月,把原先32%的翻车率直接砍到脚踝。

说人话,以前人工誊抄要三天的卷子,目前按个回车,泡好的茶还没凉。

德勤那帮审计狗更鸡贼,年报表格扔进去,40%的加班时间原地蒸发,错误率只剩0.8%,等于1000个格子里最多错8格,老板看完报表都怀疑人生:原来审计也能准点下班。
华为Mate60干脆把模型塞进相机,拍合同像拍美食,自动拉正、去阴影、抽关键字段,一秒生成可编辑Word,出差党在机场柜台就能改条款,省得回酒店开电脑。
百度8月放出的企业版更“流氓”,合同里埋的“坑”字、发票上的假章,模型直接标红,像给财务配了副AI眼镜。
信通院发的“可信AI”牌照,目前独一份,相当于官方盖章:放心用,出事我背锅。
开源社区已经玩出花,1200多个野生程序员把它拆成15个行业怪胎:医院拿来读体检报告,律所拿来拆判决文书,连化学狗都蹭热度,ACS数据集上结构式识别91.2%,画错一个苯环都能被抓出来。
最离谱的是速度,A100上2100tokens/秒,内存还省18%,老黄卡跑起来像打了鸡血。
阿拉伯语手写体那种“鬼画符”都能整到85.3%,只能说训练师里大致混了不少中东学霸。
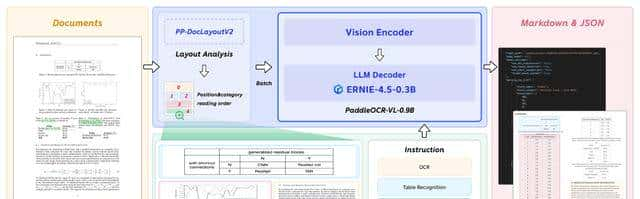
轻量级0.9B参数,笔记本就能跑,109种语言无缝切换,两阶段架构先认图再认字,把“像”和“字”分开喂,难怪RAG系统爱死它——知识库直接塞结构化文字,搜索秒回,连客服机器人都能答出页码。
一句话,PaddleOCR-VL正在把“纸质世界”转成“可搜索的Excel”,而且门槛低到离谱。
下次谁再让你手动敲表格,直接把这篇甩过去,省下的时间摸鱼也算行善。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...