
在人机语音交互领域,以GPT-4为代表的大型语言模型(LLM)极大地提升了对话系统的智能水平,使其能够进行更自然、更富有上下文的交流。然而,一个长期存在的瓶颈——交互的流畅性——依然阻碍着我们迈向真正无缝的人机对话。目前大多数语音助手仍采用半双工(half-duplex)的“对讲机”模式,用户和系统无法同时说话,导致了延迟和僵硬的交互体验。
实现全双工(full-duplex)交互,即系统能够边听边说边思考,是下一代语音交互的必然趋势。这其中的核心技术难题之一,便是语义端点检测(Semantic Endpoint Detection):系统如何实时判断用户是否已经“说完了”?这不仅仅是检测语音的结束,更是要理解用户话语在语义上是否完整。
最近关注到一偏语义VAD的论文 《PHOENIX-VAD: STREAMING SEMANTIC ENDPOINT DETECTION FOR FULL-DUPLEX SPEECH INTERACTION》,提出了一个优雅、高效且极具工程价值的解决方案Phoenix-VAD
1. 问题的核心:超越“静音”的语义端点检测
传统的语音活动检测(VAD)主要基于声学特征,判断有无语音信号。这种方法无法区分用户思考时的停顿和真正的话语结束,常常导致系统过早地“抢话”,严重影响用户体验。
为了解决这个问题,“语义VAD”应运而生。它旨在结合声学和语义信息,判断用户的意图边界。例如:
用户说:“请帮我查一下……”(语义不完整,应继续听)用户说:“请帮我查一下今天北京的天气。”(语义完整,应停止听并开始响应)
这本质上是一个实时的二元分类任务:在用户说话的每个时刻,系统都需要判断用户的状态是
Continue Speaking
Stop Speaking
然而,现有的语义VAD方案大多存在一些固有缺陷:
依赖ASR:许多方案需要一个独立的ASR模块先将语音转为全文,再进行语义判断,引入了额外的延迟和信息损失。耦合度高:一些模型将VAD功能与核心对话模型紧密耦合,导致模型臃肿,且每次更新对话能力都需要重新训练整个模型,缺乏灵活性。非流式处理:部分模型需要处理完整的用户语句才能做出判断,无法支持真正的流式实时交互。
Phoenix-VAD正是为了解决这些痛点而设计的,其核心目标是成为一个免ASR、即插即用、支持流式推理的全双工语义端点预测器。
2. Phoenix-VAD架构深度剖析:三大模块
Phoenix-VAD是一个基于LLM的自回归架构,其设计精巧地结合了音频处理、模态对齐和语言理解三大能力。其核心由三个关键组件构成,如图所示:
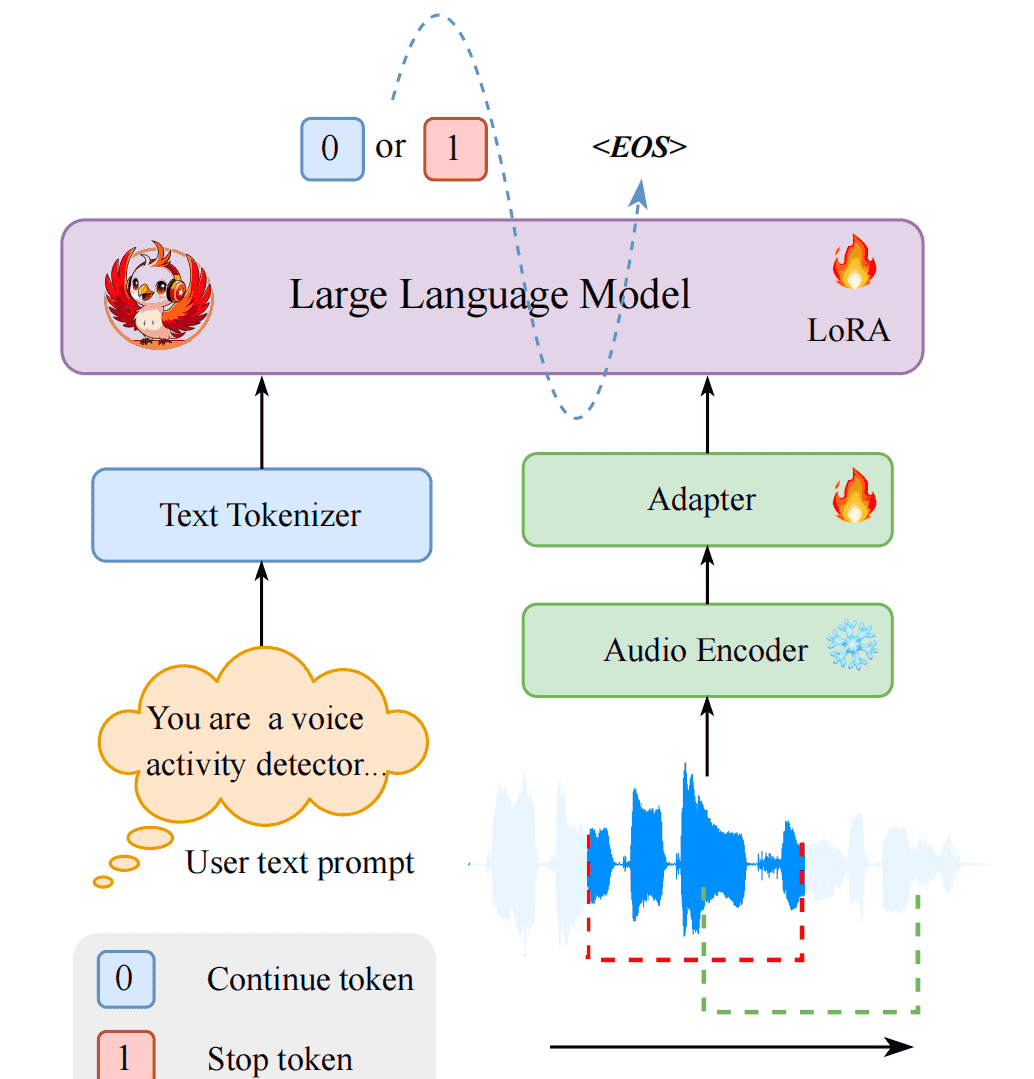
2.1. 组件一:音频编码器 (Audio Encoder) – 来自ASR结构
技术选型:采用了在语音识别领域表现卓越的 Zipformer 编码器,参数量约为1.5亿。功能:负责将原始的音频波形(raw waveform)输入,高效地提取出蕴含丰富声学信息的帧级别(frame-level)音频特征
A
极大节省训练资源:避免了训练一个庞大的音频编码器的计算开销。保持通用性:使得模型不易对VAD的训练数据过拟合,保持了对各种语音信号的鲁棒性。
2.2. 组件二:适配器 (Adapter) – Audio2Text
音频编码器输出的特征与LLM能够理解的文本嵌入(text embedding)在维度和时序分辨率上都存在差异。适配器的作用就是搭建一座桥梁,解决这个“模态鸿沟”(modality gap)。
结构:由两个线性层和一个ReLU激活函数组成,结构简单而高效。核心逻辑:
时序降采样(Temporal Downsampling):音频编码器输出的特征序列通常很长。为了与文本序列对齐并降低计算量,适配器首先对音频特征进行降采样。具体做法是:将每
k
k
k
这个过程大概是如下逻辑
import torch
import torch.nn as nn
# 假设 k=8, audio_feature_dim=512, llm_hidden_dim=1024
k = 8
audio_feature_dim = 512
llm_hidden_dim = 1024
# 适配器定义
adapter = nn.Sequential(
nn.Linear(audio_feature_dim * k, llm_hidden_dim),
nn.ReLU(),
nn.Linear(llm_hidden_dim, llm_hidden_dim)
)
# 输入: 形状为 (batch_size, sequence_length, audio_feature_dim)
# 例如: (1, 800, 512)
audio_features = torch.randn(1, 800, 512)
# 1. 时序降采样
batch_size, seq_len, feat_dim = audio_features.shape
# 确保序列长度是k的倍数
padded_seq_len = (seq_len + k - 1) // k * k
padding = padded_seq_len - seq_len
if padding > 0:
audio_features = nn.functional.pad(audio_features, (0, 0, 0, padding))
# 重塑并拼接
# new_shape: (1, 100, 8 * 512) -> (1, 100, 4096)
downsampled_features = audio_features.view(batch_size, -1, k * feat_dim)
# 2. 维度投影
# output_shape: (1, 100, 1024)
adapted_audio_features = adapter(downsampled_features)
print(f"Adapted audio features shape: {adapted_audio_features.shape}")
2.3. 组件三:中央LLM (Backbone LLM) – 语义决策
这是Phoenix-VAD的“大脑”,负责最终的语义理解和决策。
技术选型:采用了 Qwen2.5-0.5B-Instruct 模型,这是一个参数量仅为5亿的轻量级指令微调模型。输入:模型的输入由两部分拼接而成:
文本提示嵌入 (Text Prompt Embedding):一个固定的指令文本,例如 “You are a voice activity detector.”,将其通过LLM的tokenizer和embedding层转换为嵌入向量
TP
AP
输出:模型进行自回归解码,最终生成一个代表用户状态的token:
0
1
整体流程图
3. 流式推理的实现:滑动窗口策略
Phoenix-VAD能够实现流式推理的关键,在于其巧妙的滑动窗口训练与推理策略。
3.1. 训练阶段的滑动窗口
在训练时,模型并非一次性看到整个音频。而是模拟流式场景,将长的音频特征序列
F
Fc
参数定义:
Wf
Sf
逻辑:对于第
c
Fc
Yc
这种策略的价值在于:
模拟流式:训练过程与推理过程保持一致,都是基于一个固定长度的局部上下文进行判断。减少依赖:降低了模型对长程历史信息的依赖,使其更专注于从局部上下文中快速做出判断。数据增广:一个长的音频样本可以生成多个训练窗口,有效增加了训练数据量。
3.2. 推理阶段的流式处理
在实际推理时,Phoenix-VAD以
Sf
系统维护一个长度为
Wf
Sf
0
1
整个过程的延迟主要由模型单次前向传播的时间决定。论文指出,在单个NVIDIA A6000 GPU上,这个时间大约为50ms,远低于人类的感知阈值,完全满足实时交互的需求。
import numpy as np
class PhoenixVADStreaming:
def __init__(self, model, window_size_ms=2560, stride_ms=320, sample_rate=16000):
self.model = model
self.window_size = (sample_rate // 1000) * window_size_ms
self.stride_size = (sample_rate // 1000) * stride_ms
self.audio_buffer = np.zeros(self.window_size, dtype=np.float32)
def process_audio_chunk(self, chunk: np.ndarray):
"""
处理一个新的音频块 (长度为 stride_size)。
Args:
chunk: 新的音频数据块。
Returns:
int: 0 for Continue Speaking, 1 for Stop Speaking.
"""
if len(chunk) != self.stride_size:
# 可以进行填充或错误处理
pass
# 1. 更新滑动窗口缓冲区
# 移除旧数据
self.audio_buffer = np.roll(self.audio_buffer, -self.stride_size)
# 填入新数据
self.audio_buffer[-self.stride_size:] = chunk
# 2. 模型推理
# 输入是当前缓冲区内的完整音频
prediction = self.model.predict(self.audio_buffer) # predict方法封装了完整的处理流程
return prediction
# 使用示例
# vad_stream = PhoenixVADStreaming(loaded_model)
# for audio_chunk in get_audio_stream(chunk_size_ms=320):
# status = vad_stream.process_audio_chunk(audio_chunk)
# if status == 1:
# print("User has stopped speaking. Triggering response.")
# # ... 执行对话模型的响应逻辑 ...
# else:
# print("User is still speaking...")
4. 数据构建与消融实验:验证设计选择的价值
数据合成流程:Phoenix-VAD的训练数据是通过一个三阶段流程精心构建的:
文本生成:使用ChatGPT API结合内部资源,生成包含语义完整和不完整的大量文本样本。语音合成:使用高质量的TTS系统(如Index-TTS)将文本合成为语音,并通过随机采样音色库来增强说话人的多样性。时间戳标注:使用Paraformer等工具为合成语音中的每个字符标注精确的时间戳。这是生成训练标签的关键,因为“说完了”的标签
1
消融实验的启示:论文中的消融实验有力地证明了其设计选择的正确性。

减小块大小(160ms vs 320ms):将推理步长减半后,模型性能显著下降。这表明,更细的时间粒度虽然理论上响应更快,但会增加决策边界的预测不确定性,并放大了时间戳标注的微小误差,得不偿失。320ms是一个在响应速度和决策稳定性之间的甜点。分离训练适配器:如果先在ASR任务上预训练适配器,然后再冻结它去训练LLM,性能会急剧恶化。这深刻地揭示了任务目标的不一致性:ASR任务要求适配器关注词汇对齐,而VAD任务则要求适配器关注语音边界的精细时间线索。联合训练使得适配器能够同时学习这两种能力,从而达到最佳性能。
5. 小结一下
Phoenix-VAD为实现流畅、自然的全双工语音交互提供了一个强大而务实的解决方案。它的价值不仅在于其优异的性能,更在于其背后清晰的算法设计和工程逻辑。
即插即用 (Plug-and-Play):由于其免ASR和独立于对话模型的特性,Phoenix-VAD可以作为一个独立的模块,轻松集成到任何现有的口语对话系统中,极大地降低了全双工改造的门槛。流式与高效:通过滑动窗口策略和轻量化的模型设计,它在保证低延迟实时响应的同时,显著降低了计算资源的需求。语义驱动:它充分利用了LLM强大的语义理解能力,实现了真正意义上“听懂”用户的意图,而不仅仅是检测声音的起止。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










