
各工具在查找替换时可使用的正则表达式或通配符各有不同,可思考使用的工具及特点有:
1 word,有丰富的查找替换选项;
2 notepad,可打开多个文档操作;
2 dreamweaver,较好支持正则表达式及多行查找操作;
4 python,使用正则表达式做查找替换时,功能强劲;
如一样功能存在的一些细微区别:
分组替换 python是123,dreamweaver是$1$2$3
段落标记:word使用^p,dreamweaver是
或直接在文本框中按:shift+enter
1 word
word查找替换存在丰富的可选项组合:
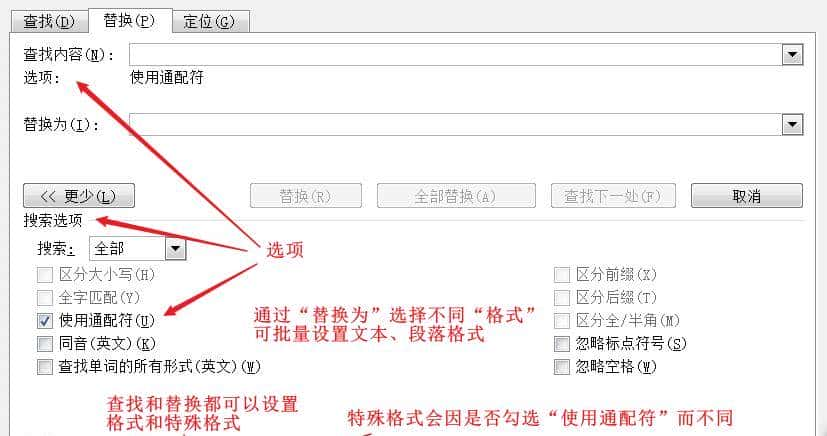
特殊格式不同的对话框:
2 notepad
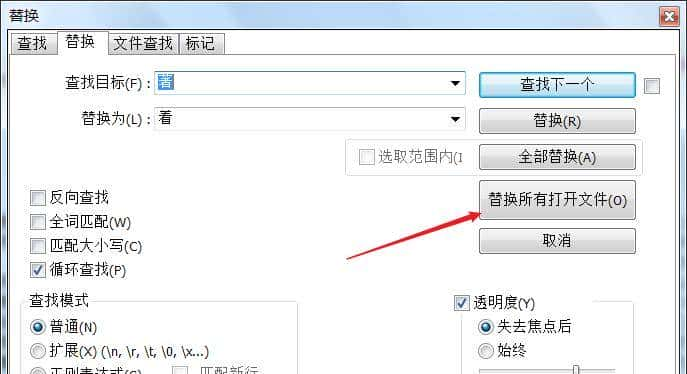
notepad支持在文件夹选择多个文件时,右击,可同时打开,并有“替换所有打开文件”的操作:
3 dreamweaver
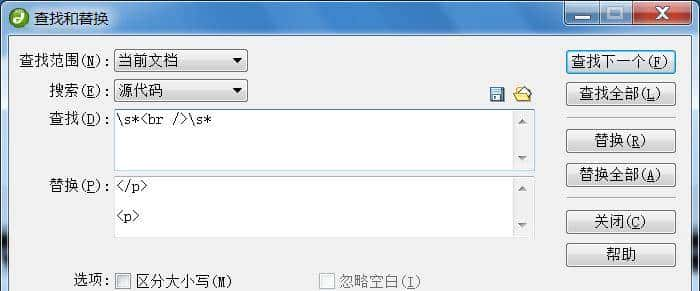
dreamweaver的查找替换对话框,对于正则表达式有较好的支持:
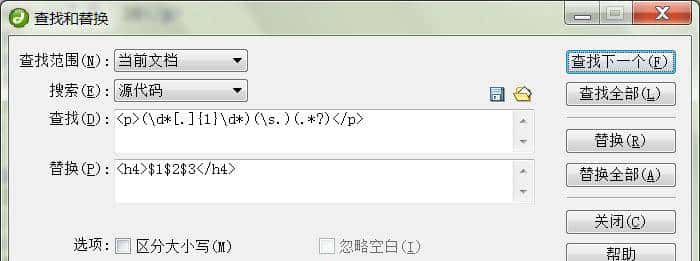
简单解释以上正则表达式:
<p>(d*[.]{1}d*)(s.)(.*?)</p>
[.]{1} 是指匹配英文句点.。
.*? 是指匹配除任意换行符以外的任意多字符。
可以直接作用多行文本:
4 python
当然,较复杂或需要完成较多的较固定的查找替换时,可以写一个简单的小程序,编程语言对于字符串操作支持都是其最基本的功能,而较容易使用的编程语言就是python了。
import sys
import os
import re
rInit = open('init.txt','rU',encoding='UTF-8')
wTemp = open('temp.txt','w',encoding="UTF-8")
nfn = str(rInit.readline()) # 第一行用作标题
nfn =nfn.replace("<p>","")
nfn =nfn.replace("</p>","")
s = rInit.read() # 整个文本文件作为一个字符串返回
s = s.replace(' ','') # 处理全角空格
s = s.replace("<<","<<")
s = s.replace("#include <","#include <")
s = s.replace("#include<","#include<")
#s = s.replace(">",">")
s = s.replace(',?' , ',”')
s = s.replace('.?' , '.”')
s = s.replace('
' , '
')
s = s.replace('
' , '
')
s = s.replace(' ' , '
')
s = re.sub(r'</div><div>', '<p></p>', s)
rejiu =re.compile(r'<S{,8}九S{,22}</S{,5}>')
s = rejiu.sub("", s)
wTemp.write(nfn) # 标题写回
wTemp.write("
")
wTemp.write(s)
rInit.close()
wTemp.close()-End-
© 版权声明
文章版权归作者所有,未经允许请勿转载。











收藏了,感谢分享