
DisCO 在数学推理微调任务上把 GRPO 和它的改善版远远甩在后面,1.5B 模型上平均领先 GRPO 约 7%、领先 DAPO 约 6%,甚至在最大响应长度(MRL)设为 8k 的情况下,表现超越了 GRPO 在 32k 长度下的结果。论文以 5、5、5、5 的高分被 NeurIPS 2025 接收。

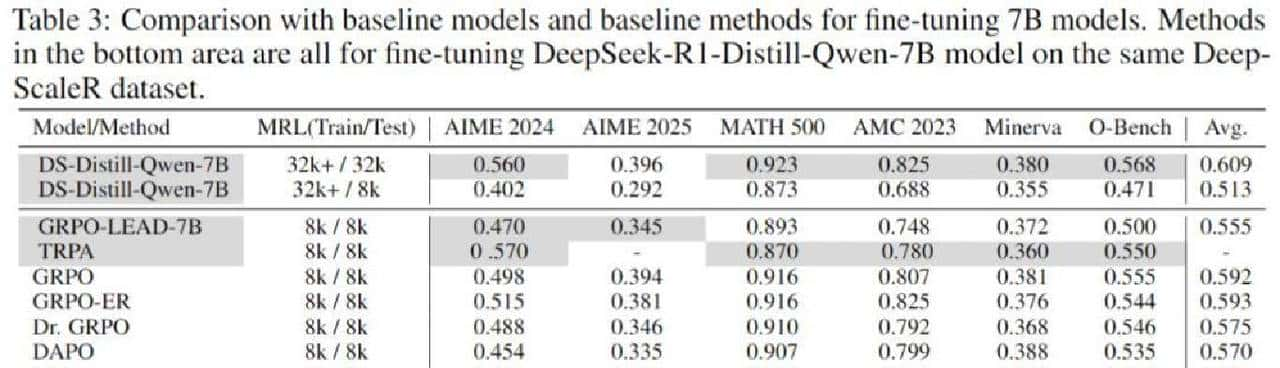
说清楚实验是怎么做的再谈理由。作者把工作放在六个数学推理基准上,比的是 Pass@1,都是在一次性抽样 16 次下算的平均值。微调做了两种规模:1.5B 和 7B。对照方法里有 GRPO、它的若干变体、DAPO,还有 DeepScaleR 项目里别人训练出的模型,外加一个 OpenAI 的 o1-preview 作为参考。数据主要来自 DeepScaleR,所以大多数比较是在同一套数据上完成的,这一点很重大,能避免数据差异带来的偏差。总体看下来,DisCO 在这些对比里是稳稳领先的:1.5B 上平均领先 GRPO 约 7%,领先 DAPO 约 6%;7B 上也有大约 3.5% 的优势。更有意思的是,DisCO 在 MRL 设为 8k 的时候,表现已经能压过 GRPO 在 32k 下的结果,这说明它在数据利用效率和策略稳定性上真的有优势。
训练时的轨迹给了不少线索。作者用训练奖励和生成熵两条曲线来盯着看。GRPO 的各种版本常见的问题是“熵崩塌”,也就是模型很快变得特别确定——生成多样性丢失,容易过早收敛到某种套路上。DAPO 则走到另一个极端,熵太高,变得过于随机,也不利于稳定提升。TRPA 用了 KL 惩罚,一开始看着稳,但后期同样会出现不稳定波动。相比之下,DisCO 的奖励呈现稳步上升,生成熵也保持在一个相对稳定的区间,不会突然塌下去或暴涨,这在训练长期稳定性上是个有说服力的证据。作者还做了消融实验,把每个模块拆开来测,发现每一块设计都有贡献,尤其是那套非裁剪评分函数,一旦去掉性能明显掉得很厉害。

为什么要做 DisCO?背景是 DeepSeek-R1 的成功让大家注意到群体相对策略优化(GRPO)这类方法。GRPO 的做法是:给问题 q,模型生成一堆候选答案,然后用群体相对优势函数来判定哪些答案好。作者对二元奖励(对/错)情况下的 GRPO 目标做了理论推导,发现两点问题。第一,群体相对优势这个目标和判别式监督学习实则有紧密联系,像是在做 AUC 最大化那种排序任务。第二,GRPO 会带来一种“难度偏差”:它在不同难度样本上优化的方向并不均衡,训练过程会被样本难度分布拉扯,最终影响模型区分稀少正确答案的能力。两条发现提示:GRPO 并非不可替代,判别式学习里的思路可以借来改善。
于是团队提出了判别式约束优化(DisCO)框架。思路很朴实:把判别式学习里那套让正确样本分数更高、错误样本分数更低的做法搬到强化学习微调里去。实现上有三个关键点。第一,用判别式的目标函数,类似 AUC 最优化,把正负样本对的排序作为训练目标;第二,思考到推理场景奖励稀疏且正负样本极不平衡,作者受分布鲁棒性启发,采用了局部 AUC 风格的目标,重点放在那些最能反映区别能力的局部难样本上,避免被大量容易错的样本淹没;第三,为了训练稳定,借了信任域的概念,用 KL 散度做约束,但不走 TRPO 那种昂贵的二阶优化路线,而是用一个平滑的平方铰链惩罚项替代不等式约束,这样求解起来更简单、计算开销也小。还有个工程细节:作者避开了常见的“裁剪操作会导致熵崩塌”的坑,改用非裁剪评分函数,这对保持训练期间的多样性协助很大。

从技术角度讲,DisCO 把判别式学习对付不平衡问题的技巧搬进了策略优化。推理任务里正确答案少、错误答案多是常态,这会让训练目标被大量易错样本主导。判别式的方法有一套成熟的应对手段,列如局部 AUC、分布鲁棒优化(DRO)等。作者把这些想法整合进目标函数,训练时不会被海量易错样本牵着走,而是把注意力聚焦到那些能区分对与错的样本对上。KL 限制用平方铰链平滑化后,不需要昂贵的二阶算子,也能在实践中保持约束效果,训练更稳。
实验表里有不少细节值得关注。表格列出多种强化学习方法在 1.5B 上的对比,有些列是其他团队训练出的模型,用阴影标注,数据来源是原论文或 DeepScaleR 项目。表下半部分是同一数据(DeepScaleR)上对
DeepSeek-R1-Distill-Qwen-1.5B 的微调实验。表里也注明了 MRL(Max Response Length),也就是训练或评估时允许模型生成的最长推理文本。除了最终的 Pass@1,作者还看了训练过程中的奖励曲线和熵曲线,这些曲线能直观地判断各方法是过早走向确定、过随机,还是保持相对稳态。图里左边两张对应 1.5B 的奖励和熵变化,右边两张对应 7B,(a)/(c) 是奖励随步数变化,(b)/(d) 是熵随步数变化,编码清晰,便于比较。
消融实验比较细致:把判别式目标、局部 AUC、平方铰链 KL 惩罚、非裁剪评分函数等逐一去掉或替换。结论是每一项设计都贡献明显,尤其是非裁剪评分函数,一旦替换回常见的裁剪版本,性能掉得最狠;局部 AUC 在对抗稀疏奖励和样本不平衡上也发挥了关键作用;平方铰链替代传统 TRPO 的 KL 约束,在实际训练中显著提高了稳定性。把这些碎片拼在一起,DisCO 在多个数学推理基准上展现出的提升,既在统计上显著,也能在训练曲线里看出来。
把这套方法放到更宽的背景里看,作者是在做一件挺务实的事:把监督学习里成熟的判别思想和强化学习里的策略优化做连接。对于推理类任务那种奖励稀疏、答案极不平衡的常见困境,这种“判别式+鲁棒化+平滑约束”的组合更像是一把工具箱,能把注意力拉回到那些真正区分对错的样本对上,而不是被大量无用或干扰样本拖住脚步。训练稳定性上的改善也不只是工程上的小修小补,它直接影响到能否把模型的潜力稳定释放出来。

说点直白的感受,这套工作里既有理论推导,也有工程细节的打磨,能把想法落地到不同规模模型上并且有重复性的提升,算是把一个方向从概念推进到可用层面的典型案例。对那些在推理模型微调上碰到熵崩塌、奖励饱和或者对长上下文利用效率不高的团队来说,这里有可参考的设计思路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










