
“简历上写用了 RocketMQ,面试官追着问为什么不用 Kafka;写了 Kafka,又被问为什么不选 RocketMQ;好不容易把两者都写上,结果被反问‘那你们为什么不用 RabbitMQ?’”
最近收到不少粉丝的吐槽,吐槽面试官对消息中间件选型 “穷追不舍”。其实,面试官并非故意 “刁难”,而是想通过这个问题,判断候选人是否真正理解技术选型的底层逻辑 ——没有最好的消息中间件,只有最适合业务场景的方案。

RocketMQ、Kafka、RabbitMQ 作为当前主流的三款消息中间件,各自在架构设计、性能表现、功能特性上存在明显差异,而这些差异恰恰决定了它们在不同业务场景中的适配度。如果只是单纯 “用” 过某款中间件,却说不清 “为什么选它”,本质上是对业务需求与技术特性的匹配逻辑理解不足。接下来,我们将从业务场景出发,拆解三款中间件的核心差异,帮你建立 “需求 – 特性 – 选型” 的清晰逻辑。
一、先搞懂核心:业务场景决定选型方向
在讨论具体中间件之前,我们需要先明确消息中间件的核心作用 ——解耦、削峰、异步通信,但不同业务对这三大作用的优先级需求截然不同:
有的业务追求 “极致吞吐”,比如日志采集、用户行为埋点,需要中间件能承载每秒数十万条的消息写入;
有的业务看重 “可靠性”,比如金融交易、订单支付,哪怕牺牲部分性能,也要确保消息不丢失、不重复;
有的业务需要 “灵活路由”,比如复杂的业务流程拆分,消息要能根据不同规则分发到不同下游系统。
这三大核心需求方向,恰好对应了三款中间件的 “优势领域”。接下来,我们逐一拆解它们的特性与适配场景。
二、三款中间件的 “特性标签” 与场景适配
1. Kafka:“高吞吐” 的代名词,适配大数据场景
Kafka 的设计初衷是解决 “日志数据的高吞吐传输” 问题,因此它的核心优势集中在 “高并发、高吞吐、低延迟” 上,同时具备较好的水平扩展能力。
核心特性:
吞吐能力极强
通过 “顺序写磁盘”“批量发送”“分区并行” 等设计,单机吞吐可轻松达到每秒数十万条消息,远超 RocketMQ 和 RabbitMQ;
延迟可控
在高吞吐场景下,延迟可控制在毫秒级,满足大部分实时数据处理需求;
生态完善
与 Hadoop、Spark、Flink 等大数据组件无缝集成,是实时计算、日志采集、用户行为分析等场景的 “标配”;
存储能力强
支持消息长时间存储(可配置保留天数),且存储成本低,适合需要 “回溯消息” 的场景(比如数据重放)。
适配场景:
日志采集:比如收集分布式系统的日志数据,汇总到大数据平台进行分析;
实时计算:比如电商的实时销量统计、用户实时画像构建,需要将数据快速传输到 Flink/Spark 集群;
海量数据同步:比如跨地域的数据备份、大文件(非事务性)的异步传输。
不适合场景:
金融级事务消息:Kafka 的事务支持相对薄弱,无法保证 “消息发送” 与 “本地事务” 的强一致性;
复杂路由需求:Kafka 仅支持 “主题 – 分区” 的简单路由,无法实现类似 “消息过滤”“死信队列” 等复杂路由逻辑。
2. RocketMQ:“可靠性 + 高吞吐” 平衡,适配互联网核心业务
RocketMQ 是阿里开源的消息中间件,脱胎于淘宝的业务场景,因此它在 “高可靠” 和 “高吞吐” 之间做了很好的平衡,同时针对互联网业务的痛点(如峰值流量、事务消息)做了大量优化。
核心特性:
事务消息成熟
支持 “两阶段提交” 的事务消息,能严格保证 “本地事务执行” 与 “消息发送” 的一致性,是电商订单、支付等核心业务的关键能力;
吞吐与可靠性兼顾
单机吞吐可达每秒数万条(虽低于 Kafka,但远超 RabbitMQ),同时通过 “同步刷盘”“主从复制” 等机制,确保消息不丢失;
峰值流量控制
支持 “流量削峰”“消息回溯”“重试机制”,能应对电商大促(如双 11)的突发流量;
国产化适配
完全开源,文档丰富,且有成熟的商业版(阿里云 RocketMQ)支持,适合国内企业的技术栈选型。
适配场景:
电商核心业务:比如订单创建后,异步通知库存扣减、物流下单、积分发放,需要事务消息保证数据一致性;
金融支付:比如支付结果通知、退款流程,需要确保消息不丢失、可追溯;
互联网平台的通用消息场景:比如用户注册后的短信通知、APP 推送,兼顾吞吐与可靠性需求。
不适合场景:
极致吞吐的大数据场景:比如纯日志采集、实时计算的数据源,Kafka 的吞吐能力更具优势;
复杂路由的企业级场景:比如需要多维度消息过滤、动态路由的传统企业应用,RabbitMQ 的灵活性更优。
3. RabbitMQ:“灵活路由” 的王者,适配复杂业务流程
RabbitMQ 基于 AMQP 协议实现,核心优势在于 “路由灵活、功能丰富”,能满足各种复杂的消息分发需求,同时在稳定性和易用性上表现出色。
核心特性:
路由逻辑极强
支持 “交换机(Exchange)” 的多种类型(Direct、Topic、Fanout、Headers),可实现 “点对点”“广播”“按规则过滤”“按头信息匹配” 等复杂路由;
功能完善
内置死信队列(DLQ)、延迟队列、消息确认(ACK)、消息优先级等功能,能应对复杂的业务流程(比如订单超时取消、异常消息重试);
易用性高
提供直观的 Web 管理界面,配置简单,社区活跃,问题排查成本低;
跨语言支持
支持 Java、Python、Go 等多种编程语言,适合多语言开发的团队。
适配场景:
企业级复杂业务流程:比如供应链系统中,同一批货物的状态变更需要通知采购、仓储、财务等多个部门,且每个部门需要不同格式的消息;
延迟任务:比如订单创建后 30 分钟未支付自动取消,通过延迟队列实现;
微服务间的精细化通信:比如微服务架构中,不同服务需要根据消息内容进行差异化处理(如按用户等级分发消息)。
不适合场景:
超大规模吞吐场景:RabbitMQ 的单机吞吐通常在每秒数千条,无法满足日志采集、实时计算等海量数据传输需求;
超大规模集群:RabbitMQ 的集群扩展能力相对较弱,在节点数量过多时,性能和稳定性会下降。
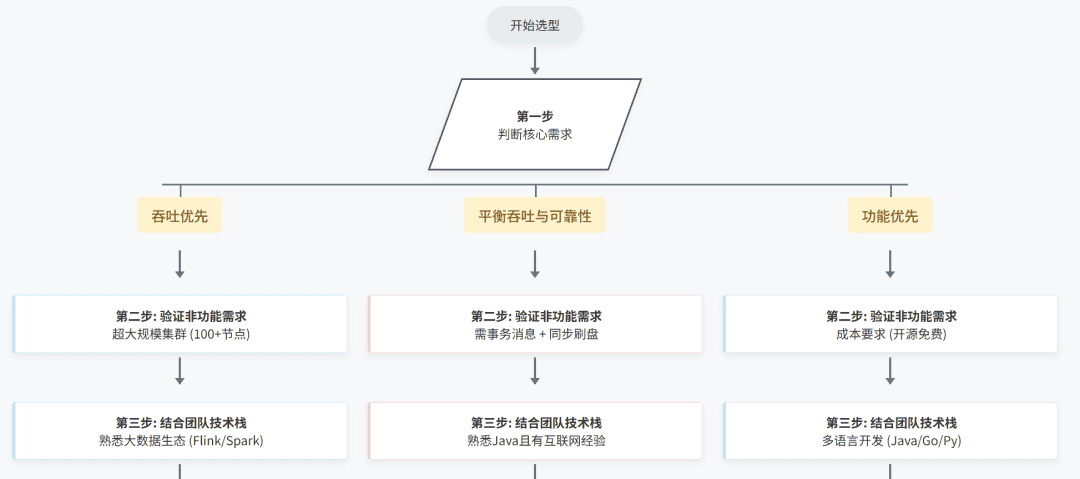
三、选型决策树:3 步搞定中间件选择
看完三款中间件的特性,可能有人还是会困惑:“我的业务既需要吞吐,又需要可靠性,该怎么选?” 其实,我们可以通过 “3 步决策法” 快速锁定选型方向:
第一步:判断核心需求是 “吞吐优先” 还是 “功能优先”
如果核心需求是 “处理海量数据,追求极致吞吐”(如日志、实时计算):直接选Kafka;
如果核心需求是 “复杂路由、延迟任务、多语言支持”(如企业级业务流程):直接选RabbitMQ;
如果核心需求是 “平衡吞吐与可靠性,且需要事务消息”(如电商、金融核心业务):直接选RocketMQ。
第二步:验证非功能需求
可靠性要求:金融场景需 “事务消息 + 同步刷盘”,优先 RocketMQ;
扩展性要求:超大规模集群(100 + 节点),优先 Kafka;
成本要求:开源免费且无商业版依赖,Kafka 和 RabbitMQ 更优(RocketMQ 商业版需付费)。
第三步:结合团队技术栈
团队熟悉大数据生态(Flink/Spark):选 Kafka,集成成本低;
团队熟悉 Java 且有互联网业务经验:选 RocketMQ,技术栈匹配度高;
团队多语言开发(如 Java+Go+Python):选 RabbitMQ,跨语言支持更友好。
四、回到面试:如何回答 “为什么选 X 不选 Y”?
最后,我们回到开头粉丝的面试问题。其实,只要掌握了 “场景 – 特性” 的匹配逻辑,回答这类问题就会非常轻松。比如:
当被问 “为什么用 RocketMQ 而不用 Kafka” 时,可以回答:“我们的业务是电商订单处理,核心需求是保证订单创建与库存扣减的事务一致性,同时需要应对大促的峰值流量。RocketMQ 的事务消息能解决一致性问题,且吞吐能力能满足我们每秒数万条的订单消息需求;而 Kafka 虽然吞吐更高,但事务支持薄弱,无法保证订单数据不丢失、不重复,因此选择了 RocketMQ。”
当被问 “为什么用 Kafka 而不用 RabbitMQ” 时,可以回答:“我们的业务是用户行为埋点,需要收集每天上亿条的用户点击数据,传输到 Flink 集群做实时分析。Kafka 的高吞吐特性(单机每秒数十万条)能轻松承载这个量级,且与 Flink 集成无缝;而 RabbitMQ 的吞吐能力无法满足,且复杂路由功能对我们来说是冗余的,因此选择了 Kafka。”
本质上,面试官想听到的不是 “X 比 Y 好”,而是 “我们的业务需要 A 特性,X 有 A 特性,Y 没有,因此选 X”—— 这才是技术选型的核心逻辑。
结语
消息中间件的选型,从来不是 “非此即彼” 的选择题,而是 “业务需求与技术特性” 的匹配题。Kafka 的高吞吐、RocketMQ 的事务可靠性、RabbitMQ 的灵活路由,分别对应了不同业务场景的核心诉求。

与其纠结 “哪款中间件更好”,不如先搞清楚 “我的业务需要什么”。只有把业务需求拆解清楚,再对应到中间件的特性上,才能做出最合理的选型 —— 这不仅能应对面试中的追问,更能为业务落地打下坚实的技术基础。
觉得有用的兄弟,点个赞,收藏起来,万一下次面试就用上了呢!

想了解更多高频面试题,欢迎关注微信公众号【Fox爱分享】,我准备了一份百万字面试宝典(已经2百多万字了),里面光高并发、分布式的项目场景题就有几百道,需要面试的同学自取。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










