
学习使用MNR训练调优一个Sentence Transformer模型

AI生成的图像
上一篇文章中我们使用Softmax Loss损失函数微调训练了第一个Sentence Transformers模型,本文我们将使用性能更好的Multiple Negatives Ranking Loss(多负样本排列损失)函数来学习微调训练性能更好的Sentence Transformer模型。
2019年第一个Sentence Transformer模型SBERT出现后句子密集词向量模型就开始蓬勃发展。后续大量的模型的性能很快超过了SBERT,这很大的缘由是Multiple Negatives Ranking Loss(多负样本排列损失)函数的使用。
同样的本文使用简单的介绍用两种方式来微调Sentence Transformer模型,第一种方法使用Pytorch编写代码进行训练。第二种方法使用Sentence Transformer提供的微调工具进行快速的微调,推荐使用第二种方法,它有更好的性能。
正如我们在关于softmax损失的文章中解释的那样,我们可以使用自然语言推理(NLI)数据集来微调句子转换模型。
在我们的例子中我们使用了部分斯坦福自然语言推理(SNLI)语料库,语料库中每个句子对由一个前提句和一个假设句组成,并被赋予一个标签:
0 — 含义关系,例如前提句暗示了假设句。
1 — 中性关系,前提句和假设句都可能是真实的,但它们之间不必定相关。
2 — 矛盾关系,前提句和假设句相互矛盾。
但在使用MNR损失进行微调时,我们将删除所有标签为中性或矛盾的行,只保留正相关的句子对。
我们将在每个步骤中将句子A(前提句,也称为锚点)和句子B(假设句,在标签为0时称为正例)输入到BERT中。
注意与softmax损失不同,我们不使用训练数据的标签label,取代的是我们为了使用MNR的多负样本,我们将通过每个batch的数据构建负样本。
数据准备:
第一我已经提前将nli数据集下载到了本地起名叫train.txt,train.txt的格式如下:

数据集对
from datasets import load_dataset
m_nli = load_dataset('csv', data_files='./snli_1.0/train.txt',split='train')
dataset = m_nli.filter( lambda x: 1 if x['label'] == 0 else 0)
print(len(dataset))代码中我们只保留了正相关的数据对,一共139406对
接下来我们继续使用transformer模型中的BertTokenizer对数据进行预处理,之前的文章介绍过使用Tokenizer是为了将文本数据转化为矩阵向量,方便使用pytorch进行数据训练,这里使用了BertTokenizer 类将'premise'和'hypothesis'列分别进行了处理转换为数学向量。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("E:\huggingface\sentence-transformers_bert-base-uncased\")
all_cols = ['label']
for part in ['premise', 'hypothesis']:
dataset = dataset.map(
lambda x: tokenizer(
x[part], max_length=128, padding='max_length',
truncation=True
), batched=True
)
for col in ['input_ids', 'attention_mask']:
dataset = dataset.rename_column(
col, part+'_'+col
)
all_cols.append(part+'_'+col)
print(all_cols)
print(dataset)接着我们使用pytorch的DataLoader完成数据的载入
import torch
dataset.set_format(type='torch', columns=all_cols)
batch_size = 32
loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)这里对许多的概念做了简化,可以查看之前的文章详细了解
开始使用Pytorch训练模型
学习训练SBERT模型,我们不需要从头训练,我们使用BERT的预训练模型做迁移学习,这样将节省大量的时间和成本。
from transformers import BertModel
model = BertModel.from_pretrained("E:\huggingface\sentence-transformers_bert-base-uncased\")使用MNR损失函数训练模型,同样使用孪生神经网络的方式,将数据对A和B分别送入孪生神经网络进行训练。
BERT模型输出512*768维的密集词向量。我们使用均值池化将它转化为的句子嵌入。这样使用孪生神经网络方法,我们每个步骤产生两个密集向量,句子A输出的a向量,正例B输出的p向量。
均值池化操作mean_pool的函数如下:
in_mask = attention_mask.unsqueeze(-1).expand(
token_embeds.size()).float()
pool = torch.sum(token_embeds * in_mask, 1) / torch.clamp(in_mask.sum(1), min=1e-9)
return pool使用平均池化函数我们就可以将我们的词向量输出从N*768转化为1*768维度
接下来我们将使用pytorch计算向量a和向量p的类似性
import torch
cos_sim=torch.nn.CosineSimilarity()
a=torch.randn(16,512)
p=torch.randn(16,512)
scores=[]
for item in a:
scores.append(cos_sim(item.reshape(1,item.shape[0]),p))
scores=torch.stack(scores)
print(scores)需要注意的是训练时是按照batch来进行训练的,这意味着我们将多个数据对同时送入模型进行计算 。
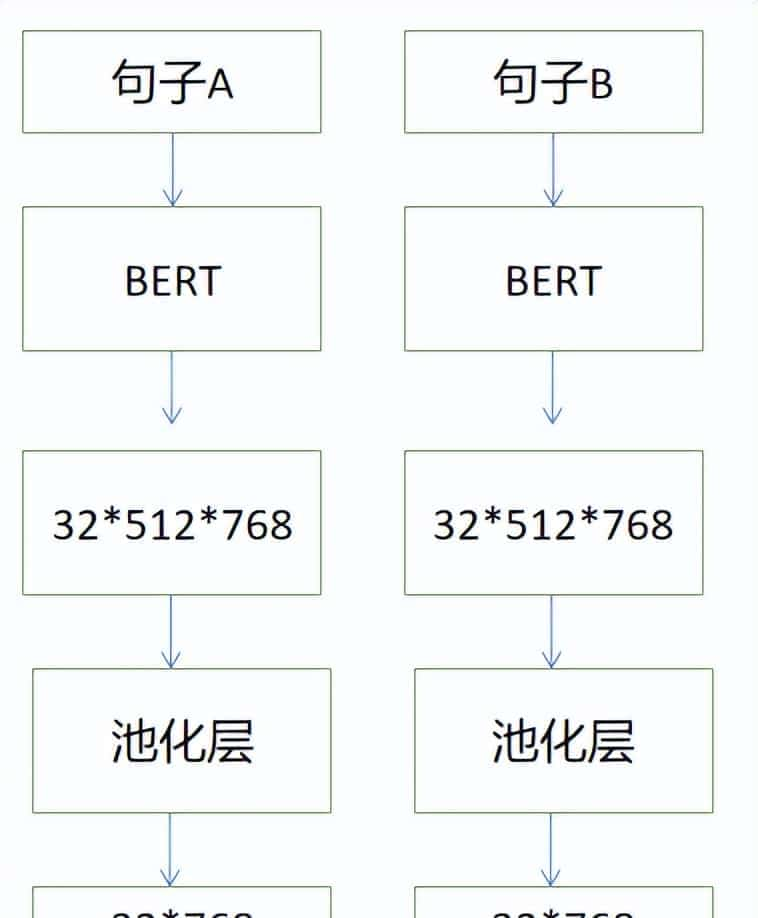
生成密集向量
所以我们一个批次的句子对A和B输入孪生神经网络后,分别输出的向量a和p的维度是32*768,接下来使用CosineSimilarity类计算a和p的类似性。
scores=[]
cos_sim = torch.nn.CosineSimilarity()scores = []
for item in a:
scores.append(cos_sim(item.reshape(1, 768), p))
scores = torch.stack(scores)输出scores的维度是32*32,到这里我们使用batch大小是32的批次获得了数据对的余弦类似性矩阵。如何使用batch为32的批次数据计算MNR损失呢
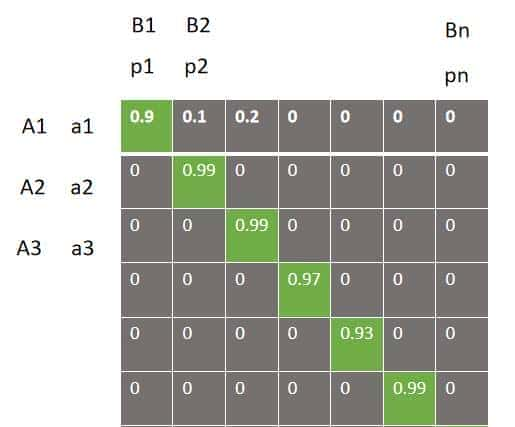
批次的类似度矩阵
我们得到的32*32的类似度矩阵,对角线的绿色部分对应的同一个句子对,需要注意的是我们的数据集只保留了正相关的数据,因此我们需要让对角线同一个数据对的类似性超级高,非对角线的类似度超级低。
因此我们根据batch大小32可以构建一个类别数为32的label标签,类似度矩阵每一行代表一个类别,这样就实现了同一个句子对的类似度高,非同一个句子对类似度低的定义,而且正样本只有一个,而负样本有31个。
labels = torch.tensor(range(len(scores)), dtype=torch.long, device=scores.device)
#输出:
#tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31],
#device='cuda:0')接下来我们根据类似度矩阵和类别标签,我们就可以定义交叉熵来进行训练工作了。
#定义交叉熵损失函数
loss_func = torch.nn.CrossEntropyLoss()
loss_func(scores, labels)虽然此处介绍了使用pytroch编写代码进行训练,但仅限于学习使用。这种方式效率和性能比较低下,在实际训练中推荐使用sentence transformers提供的训练工具,进行训练,这种方式更加简答同时训练出的模型性能更高。
使用sentence_transformer工具训练模型
正如我们之前提到的,使用 MNR 损失函数有一种更简单的方法来微调模型。sentence-transformers 库允许我们使用预训练的句子转换模型,并提供了一些便捷的训练工具。
载入数据的代码完全一样,不同的是我们不需要进行手动的token化;而是简单的使用(sentence-transformers)的InputExample库来完成这个操作。
from sentence_transformers import InputExample
train_samples = []
for row in dataset:
train_samples.append(InputExample( texts=[row['premise'], row['hypothesis']] ))InputExample仅包含带有a和p句对的数据,然后将其送到NoDuplicatesDataLoader对象中。这个数据加载器确保每个批次都不包含重复数据,这在使用MNR损失函数对随机抽样的句对进行类似性排序时超级有用。
目前我们来定义模型。sentence-transformers库允许我们使用模块构建模型。我们只需要一个transformer模型(我们将再次使用bert-base-uncased)和一个平均池化模块。
from sentence_transformers import models, SentenceTransformer
bert = models.Transformer('bert-base-uncased')
pooler = models.Pooling( bert.get_word_embedding_dimension(), pooling_mode_mean_tokens=True )
model = SentenceTransformer(modules=[bert, pooler])目前我们有了一个初始化的模型。在训练之前,唯一剩下的就是损失函数——MNR损失。
from sentence_transformers import losses
loss = losses.MultipleNegativesRankingLoss(model)有了这些,我们的数据加载器、模型和损失函数都准备好了。剩下的就是微调模型!
epochs = 1
warmup_steps = int(len(loader) * epochs * 0.1)
model.fit( train_objectives=[(loader, loss)],
epochs=epochs, warmup_steps=warmup_steps,
output_path='./sbert_test_mnr2',
show_progress_bar=False )完成代码如下:
import torch
from datasets import load_dataset
m_nli = load_dataset('csv', data_files='./snli_1.0/train.txt',split='train')
dataset = m_nli.filter( lambda x: 1 if x['label'] == 0 else 0)
print(len(dataset))
from sentence_transformers import InputExample
from tqdm.auto import tqdm # so we see progress bar
train_samples = []
for row in tqdm(m_nli):
train_samples.append(InputExample(
texts=[row['premise'], row['hypothesis']]
))
from sentence_transformers import datasets
batch_size = 32
loader = datasets.NoDuplicatesDataLoader(
train_samples, batch_size=batch_size)
from sentence_transformers import models, SentenceTransformer
bert = models.Transformer("E:\huggingface\sentence-transformers_bert-base-uncased\")
print(bert.get_word_embedding_dimension())
pooler = models.Pooling(
bert.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True
)
model = SentenceTransformer(modules=[bert, pooler])
from sentence_transformers import losses
loss = losses.MultipleNegativesRankingLoss(model)
epochs = 1
warmup_steps = int(len(loader) * epochs * 0.1)
model.fit(
train_objectives=[(loader, loss)],
epochs=epochs,
warmup_steps=warmup_steps,
output_path='./sbert_test_mnr2',
show_progress_bar=False
)代码中由于网络问题,我都是先将数据和模型下载到本地再导入的方式。
对比模型:
我们对比了使用MNR和Softmax损失函数微调的sentence transformer模型的性能,同时对比了更加强劲的all-mp-base-v2模型。
测试数据集使用了huggingface提供的STS数据集,这个数据聚焦对每个数据对给了1-5的类似度打分。最后使用sentence-transformers的评估工具进行模型的评估,代码如下。
import datasets
sts = datasets.load_dataset('glue', 'stsb', split='validation')
print(sts)
sts = sts.map(lambda x: {'label': x['label'] / 5.0})
from sentence_transformers import InputExample
samples = []
for sample in sts:
samples.append(InputExample(
texts=[sample['sentence1'], sample['sentence2']],
label=sample['label']
))
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
evaluator = EmbeddingSimilarityEvaluator.from_input_examples(
samples, write_csv=False
)
from sentence_transformers import SentenceTransformer
#评估mnr调优的模型
model = SentenceTransformer('./sbert_test_mnr2')
result=evaluator(model)
print(result)
#评估softmax调优的模型
model2= SentenceTransformer('./sbert_test_a')
result=evaluator(model2)
print(result)
#评估all-mp-base-v2调优的模型
model2= SentenceTransformer('all-mp-base-v2')
result=evaluator(model2)
print(result)
模型评估性能如下:
Softmax:0.67
MNR:0.77
all-mp-base-v2:0.88
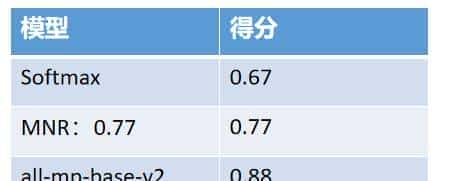
模型对比
结论:
本文我们使用MNR多负样本排列损失学习训练一个新的sentence transformer模型,并和其他模型进行了对比,结果显示MNR损失函数有更高的性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。













收藏了,感谢分享