
新词发现是一个老生常谈的任务了,对怎么算“词”,有一个很好的比喻:怎样判断两个人是情侣?第一,我们得常常看到他们在一起,而不是今天看到A和B在一起,明天看到A和C,B和D,那可能是海王;第二是他们周围的圈子也很丰富,不能说每次看到他们一起都是和其他同样的面孔在同样的环境,那可能是英语角练英语[/doge]。前者反映为凝固度,后者反映为自由度。
1.互信息:MI(Mutual Information)
这个指标衡量凝固度,对两个字计算
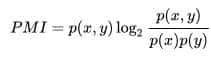
对多个字的,算平均互信息(AMI):
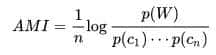
还有资料用以下方式计算:
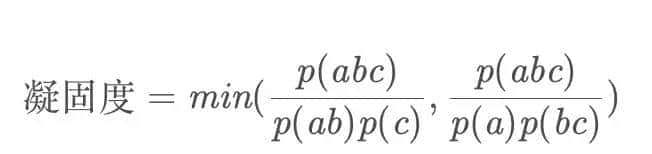
也就是思考词的两两组合的不同情况,取情况最坏(说明不能成为一个词)的某种组合作为瓶颈值。这样等于说我们期待这个词是无论怎么切分都很凝聚的。
2.自信息(信息熵):Entropy
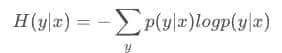
这个公式用于新词发现的计算时,反映了周围字的丰富度。我们分别计算一个词的左右邻字的信息熵。一个词我们希望左右邻字的信息熵都很高。这里需要一个公式计算左右邻熵的综合值。
hanlp中取左右信息熵中最小值。SmoothNLP和HelloNLP中公开的计算公式如下。

实际上源码中计算公式为:
smoothnlp:
math.log((l_e * 2 ** r_e + r_e * 2 ** l_e + 0.00001) / (abs(l_e - r_e) + 1), 1.5)
hellonlp:
math.log((l_e * math.e ** r_e+0.00001)/(abs(l_e - r_e)+1), math.e)
+ math.log((r_e * math.e ** l_e+0.00001)/(abs(l_e - r_e)+1), math.e)
这里的公式个人认为不是很合理。由于我们的目标是希望EL和ER都很大,而|EL-ER|是隐含希望他们很相近,所以会出现:
LS(2.99, 2.99) = 9.5222271192095
LS(3.0, 3.5) = 9.176423134994266
LH(2.99, 2.99) = 8.170547111175976
LH(3.0, 3.5) = 8.040445283853845
也就是说,EL和ER双高的情况的值竟然比EL和ER相对双低的情况的值还低,只由于后者接近,这显然不合理。
以及
LS(2, 100) = 161.32768043007533
LS(40, 40) = 79.18785911538012
LH(2, 100) = 98.10807767981238
LH(40, 40) = 87.37775890822788
这里左右邻熵失衡、左邻熵超级小的情况下,分值比左右邻熵双高且均衡的情况还要大,说明公式也没有很好地让双高且接近的值更大(由于差值的倒数有边际效应递减)。
所以可以自己设计一个公式L_mine。e.g.
min(l_e, r_e) * math.sqrt(max(l_e, r_e))
L_mine(2.99, 2.99) = 5.170193323271384
L_mine(3.0, 3.5) = 5.612486080160912
L_mine(2, 100) = 20.0
L_mine(40, 40) = 252.98221281347037
L_mine(20, 50) = 141.4213562373095
这样就同时思考的两边的值同时削弱了大值的影响,很好地让EL和ER双高的情况值最大。
以上两点是新词发现常用的两个指标,对于我们任务关键词抽取来说,还是欠缺了一点。由于我们希望抽取的词能更专业名词一点,且长词优先。不希望充斥大量的“这句话”、“忽大忽小”,虽然他们符合词的定义,但是不是我们的target word。所后来续还可以结合一些指标来筛选和算分。
3.tf-idf
我们希望这个词有一点特别,不是每篇文章都出现的口水词。很容易就能想到tf-idf可以做关键词提取。这里计算一个词的idf并不是用的这个词的idf,而是词里的每个字的idf的平均值。

4.词性结构
我们可以将词当作字进行如上的计算,先分词再结合。这时候分词就可以得到每个词的词性。整理出词性组合,就可以通过词性组合来筛选出目标词了。但是由于词性这一步也会有错误和例外,所以这一步我只做了简单的判断:当出现名词时,加分;当出现助词、符号等明显错误的,减分。
代码来说,先统计文档里ngram的基本信息,以及统计idf。
def calculate_idf(idf_list):
idf_di = dict()
for sentence_word_set in idf_list:
for word in sentence_word_set:
if word not in idf_di:
idf_di[word] = 0
idf_di[word] += 1
l = len(idf_list)
for word in idf_di:
idf_di[word] = math.log(l/(idf_di[word] + 1))
return idf_di
def calculate_frequency(sentences, k=4, mode="word"):
word_num = 0
freq_di = dict()
idf_list = []
for sentence in sentences:
sentence_set = set()
if mode == "word":
res = jieba.lcut(sentence)
words = [elem.word for elem in res]
flags = [elem.flag for elem in res]
elif mode == "char":
words = list(sentence)
flags = ["n" for i in words]
l = len(words)
word_num = word_num + l
for i in range(l):
sentence_set.add(words[i])
for j in range(1, k + 1 if i + k + 1 <= l else l - i):
word = tuple(words[i: i + j])
if word not in freq_di:
freq_di[word] = {"freq": 0, "left": [], "right": [], "pos":[]}
freq_di[word]["freq"] += 1
freq_di[word]["left"].append(words[i - 1] if i - 1 >= 0 else "")
freq_di[word]["right"].append(words[i + j] if i + j <= l else "")
freq_di[word]["pos"] = flags[i: i + j]
idf_list.append(sentence_set)
idf_di = calculate_idf(idf_list)
return freq_di, word_num, idf_di
计算entropy,这里有个问题,就是有的词是句首词或句尾词时意味着它没有左邻/右邻,这时候想到几种处理方式:1.没有邻时即不将这种情况算进去。这种方式容易漏掉诸如名字等容易出目前句首的词。2.此时将邻看作””这个字符和其他字符一样处理。 3.将邻看作””这个字符,但是“”彼此之间看作不同字符,也就是说句首句尾词认为它有一个互不一样的邻字。这时候我的处理方式是2和3方法的折中处理。将所有””看作不同字符,不过对这个情况的数目通过开方来降权。
def entropy(word_list):
di = dict(Counter(word_list))
num = sum(di.values())
res = 0
for word, freq in di.items():
if word == "":
res -= (1/num * math.log2(1/num)) * math.sqrt(freq)
else:
res -= freq/num * math.log2(freq/num)
return res
def L_entropy(freq_di, threshold=0, percent=10):
di = dict()
for word in freq_di:
if len(word) > 1:
l_e = entropy(freq_di[word]["left"])
r_e = entropy(freq_di[word]["right"])
final_entropy = min(l_e, r_e) * math.sqrt(max(l_e, r_e))
if final_entropy > threshold:
#di[word] = final_entropy
di[word] = [final_entropy, l_e, r_e]
#di = sorted(di.items(), key=lambda x: x[1], reverse=True)
di = sorted(di.items(), key=lambda x: x[1][0], reverse=True)
di = di[:int(len(freq_di) * percent / 100)]
print(di[0][1], di[-1][1])
di = {key: value for key, value in di}
return di
计算ami:
def ami(freq_di, word_num, threshold=0, percent=10):
di = dict()
for word in freq_di:
if len(word) > 1:
val = freq_di[word]["freq"]/word_num
for single_word in word:
val = val / (freq_di[tuple([single_word])]["freq"]/word_num)
val = math.log2(val)
val /= len(word)
if val > threshold:
di[word] = val
di = sorted(di.items(), key=lambda x: x[1], reverse=True)
di = di[:int(len(freq_di) * percent / 100)]
print(di[0][1], di[-1][1])
di = {key: value for key, value in di}
return di
最后对三体.txt进行测试,结合entropy, ami, idf, 词性结构分,词频几个因素综合筛选、算分得char模式top100词:
[ 雷迪亚兹 , 章北海 , 希恩斯 , PDC , 狄奥伦娜 , 申玉菲 , 穿梭机 , 瓦季姆 , 金字塔 , 银河系 , 吴岳 , 饕餮鱼 , 杨卫宁 , 曲率驱动 , 曹彬 , 黑暗森林 , 思想钢印 , 山杉惠子 , PIA , 赫尔辛根默斯肯 , 常伟思 , ETO , 降临派 , 尘埃云 , 斐兹罗 , 东方延绪 , 高Way , 阶梯计划 , 逃亡主义 , 黑暗森林威慑 , 联邦政府 , 黑暗森林打击 , 行星防御理事会 , 冯・诺伊曼 , 威慑纪元 , 伽尔宁 , 伊甸园 , 白Ice , DX3906 , 弗雷斯 , 疲惫 , 法扎兰 , 张援朝 , 失败主义 , ‘自然选择’号 , 执政官 , 柯伊伯带 , 公元世纪 , 亚洲舰队 , IDC , 哈勃二号 , 雷迪亚兹的 , 钢印族 , 韦斯特 , 引力波发射 , 乔纳森 , 国际社会 , 残骸 , 君士坦丁 , 蒙娜丽莎 , 曲率引擎 , 翘曲点 , 露珠公主 , 卢浮宫 , 白沐霖 , 星环集团 , 拯救派 , 杨晋文 , 小心翼翼地 , 信息窗口 , 基础研究 , 褐蚁 , KILLER , 君士坦丁堡 , 宇宙广播 , 晶莹 , 陶醉 , 红岸基地 , 末日战役 , ‘星环’号 , 祈祷 , 叶哲泰 , 科学执政官 , 四维碎块 , NH558J2 , 拐杖 , 针眼画师 , 阶梯计划的 , 沙瑞山 , 聚变发动机 , 指挥系统 , 舰队联席会议 , 电磁辐射 , 莫沃维奇 , 幼稚 , 蚂蚁 , 红岸系统 , 肥皂 , 追击舰队 , ‘审判日’号 ]
这里的一些错误词主要是”的,”地”模式,smoothnnlp对这种情况(最后一个字为频繁字)专门做了过滤处理,我这里还没做。
如果用word模式:
[ 行星防御理事会 , 狄奥伦娜 , 治安军 , 山杉惠子 , 各常任理事国 , 冯・诺伊曼 , 执剑人 , 雷达峰 , 莫沃维奇 , 莫沃维奇和关一帆 , 奥尔特星云 , 宏原子 , 无故事王国 , 恒星型氢弹 , 恒星级战舰 , 强互作用力 , 机械臂 , 程心想 , 常任理事国 , 联合国行星防御理事会 , 化学火箭 , 史耐德 , V装具 , 赫尔辛根默斯 , 可控核聚变 , 猜疑链 , 黑暗森林理论 , 禇岩 , 低熵体 , 斐兹罗 , 面壁者雷迪亚兹 , ”冯・诺伊曼 , 托马斯・维德 , 两位副舰长 , 187J3X1恒星 , 解析摄像机 , 半人马座 , 强互作用力宇宙探测器 , 解读者 , 第三宇宙速度 ]
效果还是不错的,肉眼看出远好于下面smoothnlp和hellonlp的结果。
[ 短短 , 长长 , 空间 , 技术 , 宇宙 , 引力 , 00 , 太阳 , 11 , 太空 , 狄奥伦娜 , 赫尔辛根默 , 辛根默斯肯 , 尔辛根默斯 , 史瓦西半径 , 尔辛根默 , 福尔摩斯 , 瓦西半径 , 赫尔辛根 , 申玉菲 , V装具 , 狄奥伦 , 奥伦娜 , 根默斯肯 , 辛根默斯 , 福尔摩 , 雷迪亚兹 , 史瓦西半 , 辛根默 , 张援朝 , 赫尔辛 , 逃亡主义 , 默斯肯 , 尔辛根 , 瓦西半 , 希恩斯 , 降临派 , 尔摩斯 , 饕餮鱼 , 控制单元 , 西半径 , 嘿嘿嘿 , 根默斯 , 青铜时代号 , 杨卫宁 , 运载舱 , 青铜时代 , 自然选择 , 史瓦西 , 雷迪亚 , 迪亚兹 , 执政官 , 自然选择号 , 拯救派 , 机械臂 , 逃亡主 , 澳大利亚 , 技术突变 , 望远镜 , 螳螂号 , 1187 , 章北海 , 思想钢印 , 然选择号 , 然选择 , 队司令 , 舰队司令 , 控制单 , 蒸汽机 , 科学和理性 , 层隐喻 , 187 , 环集团 , 亡主义 , 技术公有化 , 乱纪元 , 制单元 , 银河系 , 尘埃云 , 要回答 , 秘书长 , 哈哈哈 , 金字塔 , 星环集团 , 穿梭机 , 青铜时 , 铜时代号 , 000万年 , 短短短短 , 护士 , KB , 装具 , 吴岳 , 狄奥 , 残骸 , 伦娜 , 申玉 , 援朝 , 械臂 , 奥伦 ]
[ 短短 , 长长 , 太阳 , 技术 , 世界 , 宇宙 , 飞船 , 三体 , 太空 , 187j3x1 , 赫尔辛根默 , 辛根默斯肯 , 尔辛根默斯 , 尔辛根默 , 赫尔辛根 , 根默斯肯 , 辛根默斯 , 187j3 , j3x1 , 福尔摩斯 , 辛根默 , 爱因斯坦 , 雷迪亚兹 , 尔辛根 , 嘿嘿嘿嘿 , 战略研究室 , 饕餮鱼 , 福尔摩 , 略研究室 , 食品垛 , 黑暗森林 , 赫尔辛 , 默斯肯 , 根默斯 , 暗森林 , 尔摩斯 , 术战略研究 , 青铜时代号 , 执政官 , 降临派 , 因斯坦 , 青铜时代 , 逃亡主义 , 拯救派 , 技术战略研 , 嘿嘿嘿 , 控制单元 , 雷迪亚 , 迪亚兹 , 技术突变 , 洛文斯基 , 自然选择 , 自然选择号 , 红卫兵 , 思想钢印 , 研究室 , 机械臂 , 澳大利亚 , 望远镜 , 战略研究 , 章北海 , 爱因斯 , 金字塔 , 环集团 , 层隐喻 , 复制世界 , 黑暗森 , 蒸汽机 , 术战略研 , 然选择号 , 监护官 , 然选择 , 监听部 , 信念簿 , 星环集团 , 技术战略 , 同义词 , 逃亡主 , 银河系人类 , 略研究 , 哈哈哈 , 银河系 , 术突变 , 治安军 , 短短短短 , 怎样想 , 万千米 , 要回答 , 青铜时 , 穿梭机 , 控制单 , 铜时代号 , 饕餮 , 187j , 幽闭 , 规律 , 退却 , 独裁 , 仇恨 , 庄颜 ]
参考资料:
https://www.jianshu.com/p/9b8bf8bb197c
https://github.com/smoothnlp/SmoothNLP/tree/master/tutorials/新词发现
https://zhuanlan.zhihu.com/p/210584733
https://blog.csdn.net/cdd2xd/article/details/94354751
https://blog.csdn.net/wendingzhulu/article/details/44464895
https://blog.csdn.net/zhaomengszu/article/details/81452907
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










