
一、学前花絮
我们将介绍Python3中常用的OS文件/目录方法,在学习之前,大家必定用过windows系统中的各种文件夹/目录吧。实则用python管理文件/目录是一种需求,我们日常工作中手工创建或者修改文件/目录,而python语言提供了一种自动化处理的方式。
常用操作包括:
- 获取当前工作目录
- 获取上级目录、下级目录(通过路径拼接)
- 改变当前工作目录
- 创建目录
- 删除目录(空目录和非空目录)
- 遍历多级目录(递归)
注意:删除非空目录需要使用shutil模块。
我们将编写一个递归函数来遍历多级目录,并打印所有文件和目录。步骤:
- 导入必要的模块:os, shutil
- 定义常用操作示例
- 定义递归遍历目录的函数
二、Python3 OS 文件/目录方法以及遍历多级目录
2.1常用 OS 文件/目录方法:
1. 获取当前目录
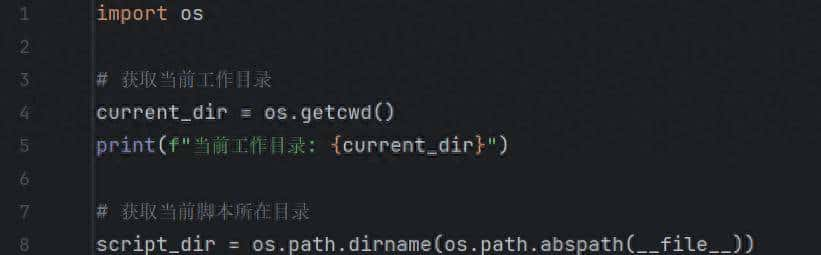
当前目录
输出如下:

输出结果
2.获取上级目录和下级目录
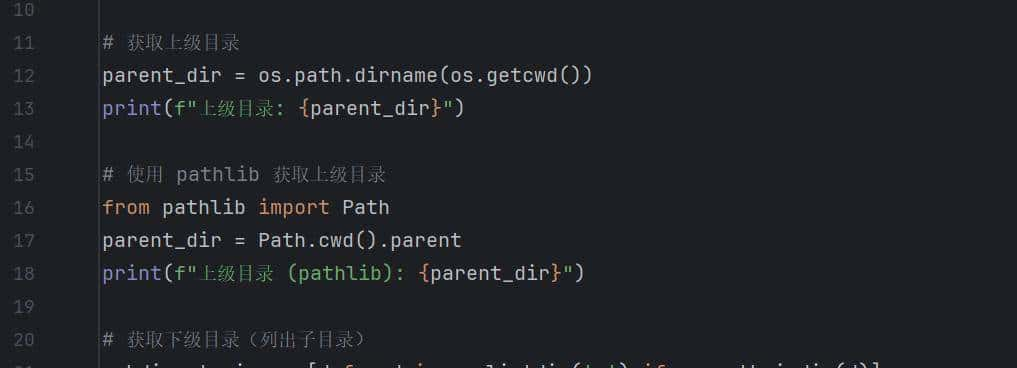
上下级目录
输出结果:

结果显示
3. 改变目录
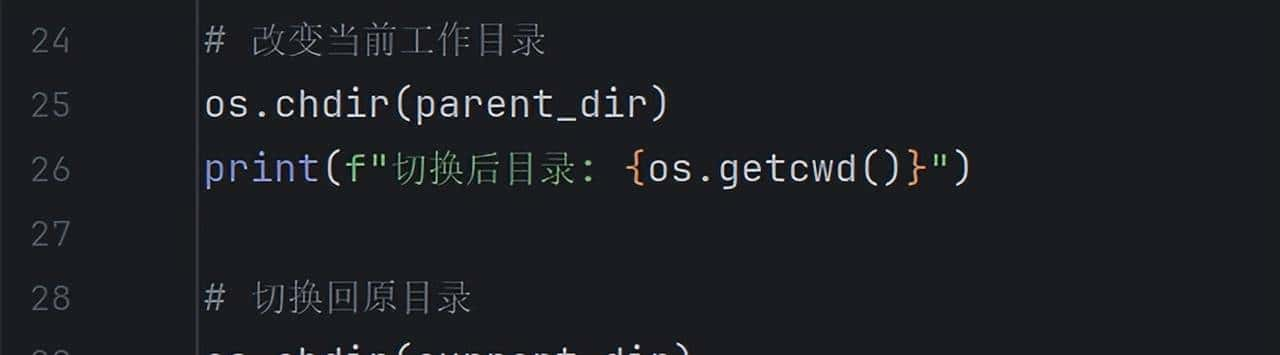
改变目录
输出结果:

结果显示
4. 创建目录
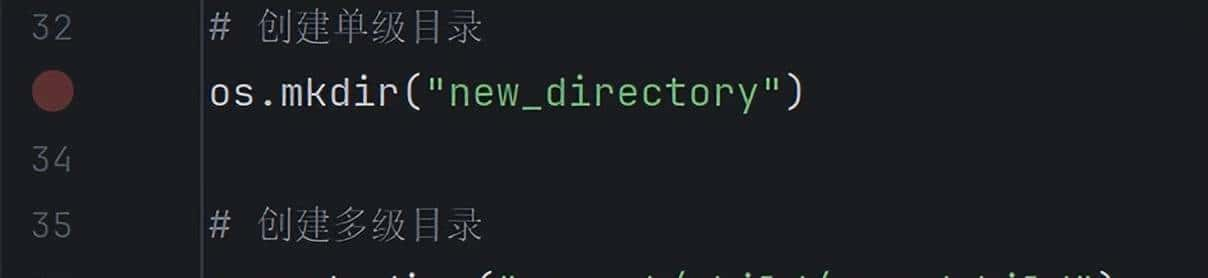
创建目录
5.删除目录
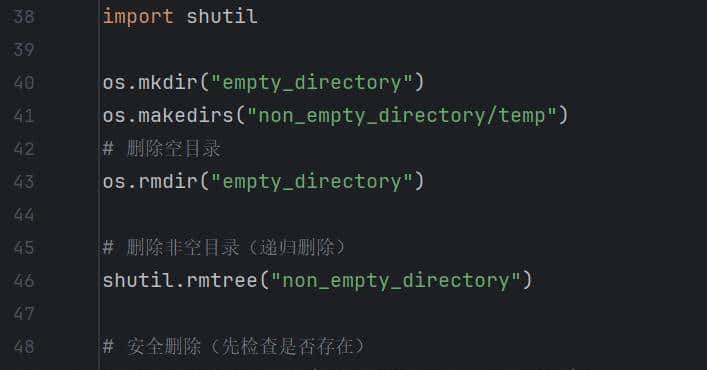
删除目录
6. 列出目录内容
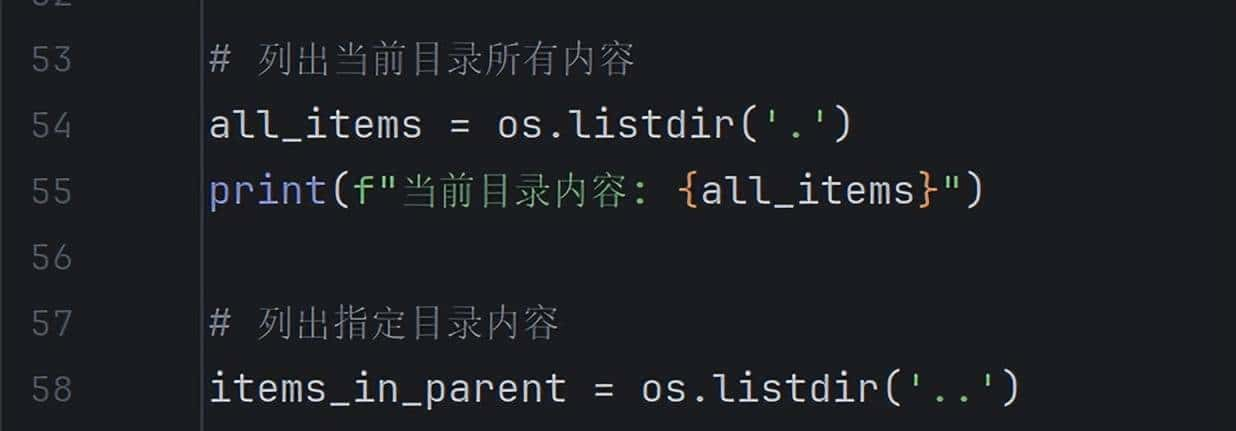
列出目录内容
输出结果:

结果显示
7. 路径操作
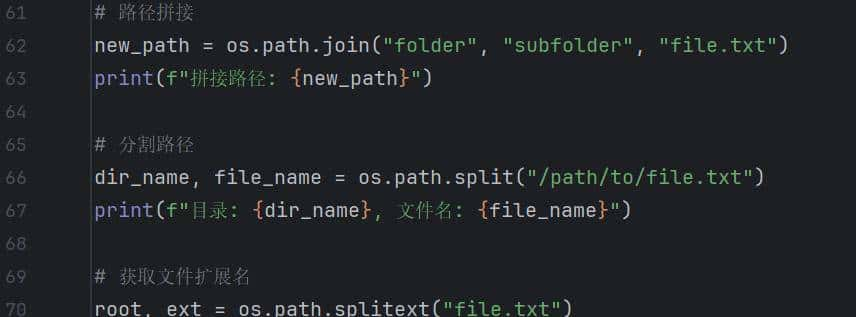
路径拼接
输出结果:

结果显示
2.2递归遍历多级目录的实现
下面是一个完整的递归遍历多级目录的程序,它会打印出目录树结构,并统计文件类型信息:
|
import os import time from pathlib import Path def traverse_directory(path, indent=0, file_stats=None): “”” 递归遍历目录并打印目录树结构 参数: path: 要遍历的目录路径 indent: 缩进级别(用于打印树状结构) file_stats: 文件类型统计字典 “”” if file_stats is None: file_stats = {} # 获取目录名 dir_name = os.path.basename(path) or path # 打印当前目录(带缩进) print(” ” * indent + f” {dir_name}/”) try: # 列出目录内容 with os.scandir(path) as entries: for entry in entries: # 计算下一级缩进 next_indent = indent + 4 if entry.is_dir(): # 递归遍历子目录 traverse_directory(entry.path, next_indent, file_stats) elif entry.is_file(): # 处理文件 file_ext = os.path.splitext(entry.name)[1].lower() or “无扩展名” # 更新文件统计 if file_ext not in file_stats: file_stats[file_ext] = {“count”: 0, “size”: 0} file_stats[file_ext][“count”] += 1 file_stats[file_ext][“size”] += entry.stat().st_size # 打印文件信息 size_kb = entry.stat().st_size / 1024 mod_time = time.strftime(“%Y-%m-%d %H:%M”, time.localtime(entry.stat().st_mtime)) print(” ” * next_indent + f” {entry.name} ({size_kb:.2f} KB, 修改于 {mod_time})”) except PermissionError: print(” ” * next_indent + “⚠️ 权限不足,无法访问”) except Exception as e: print(” ” * next_indent + f”❌ 错误: {str(e)}”) return file_stats def print_summary(file_stats): “””打印文件类型统计摘要””” print(” print(“-” * 50) print(f”{'扩展名':<15} {'数量':<10} {'总大小(KB)':<15} {'平均大小(KB)':<15}”) print(“-” * 50) total_files = 0 total_size = 0 for ext, stats in sorted(file_stats.items(), key=lambda x: x[1]['size'], reverse=True): count = stats[“count”] size_bytes = stats[“size”] size_kb = size_bytes / 1024 avg_size = size_kb / count if count > 0 else 0 print(f”{ext:<15} {count:<10} {size_kb:<15.2f} {avg_size:<15.2f}”) total_files += count total_size += size_kb print(“-” * 50) print( f”{'总计':<15} {total_files:<10} {total_size:<15.2f} {total_size / total_files if total_files > 0 else 0:<15.2f}”) print(“-” * 50) def main(): # 获取用户输入的目录路径 default_path = os.getcwd() user_input = input(f”请输入要遍历的目录路径 (默认为当前目录 '{default_path}'): “).strip() target_dir = user_input if user_input else default_path # 检查目录是否存在 if not os.path.isdir(target_dir): print(f”错误: 目录 '{target_dir}' 不存在!”) return print(f” # 遍历目录并收集统计信息 file_stats = traverse_directory(target_dir) # 打印统计摘要 print_summary(file_stats) print(” if __name__ == “__main__”: main() |
以上程序中,我们看到在函数 traverse_directory内部再次调用该函数,这就是递归的应用。递归与循环看起来效果差不多,但本质上不同:for/while 是迭代,递归是函数调用。
以上输出结果如下:
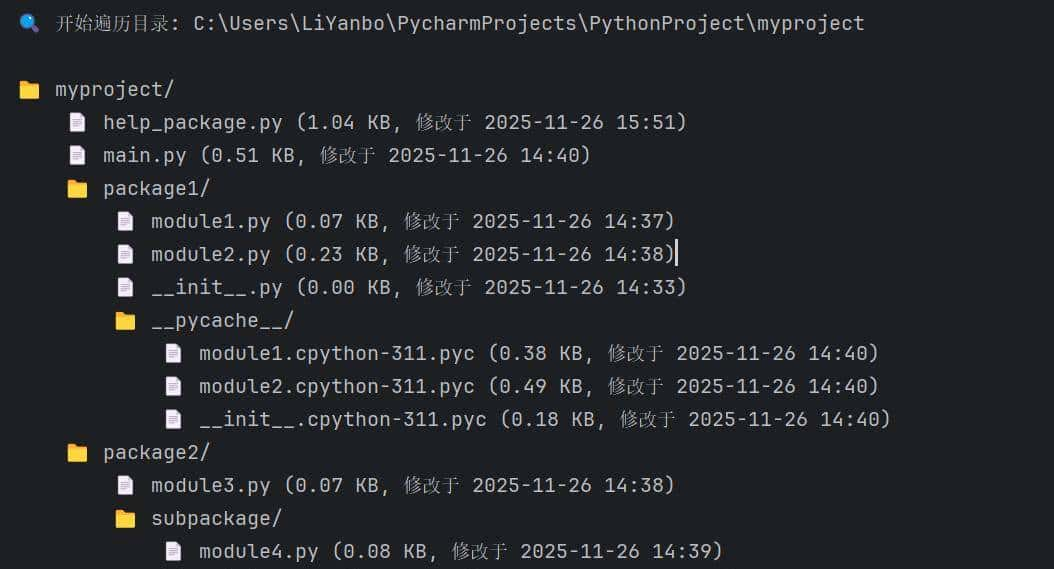
目录显示输出结果
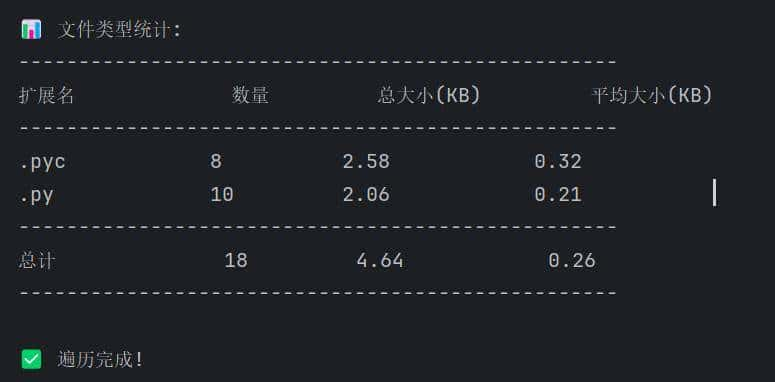
统计信息
生成目录树:

生成目录树
输出结果:
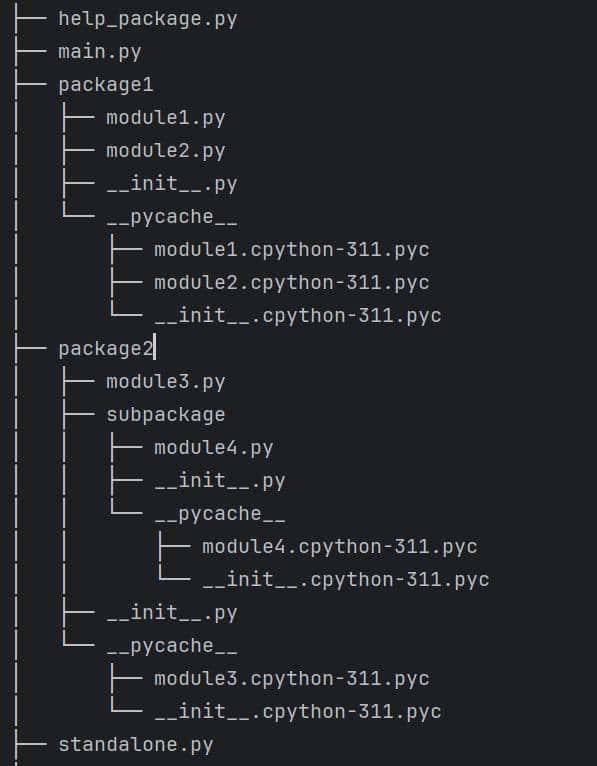
目录树显示
以上程序提供了强劲的目录遍历功能,可以协助你更好地理解和管理项目结构。你可以根据需要进一步扩展功能,列如添加文件内容搜索、大小过滤或导出报告等功能。
三、小结
今天我们学习了Python的文件/目录方法,并遍历多级目录。这个功能也是比较实用的,特别是在一个相对复杂的目录树中,如何计算所有文件(或者某个特征的文件)的文件大小等信息。
让我们保持学习热烈,多做练习。我们下期再见!

快乐男孩
#python#
© 版权声明
文章版权归作者所有,未经允许请勿转载。















怎么学习Python
好好学习
收藏了,感谢分享